Сергей Анисимов - Поисковое продвижение сайтов

- Название:Поисковое продвижение сайтов
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:2020
- Город:Москва
- ISBN:978-5-001-44212-7
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Сергей Анисимов - Поисковое продвижение сайтов краткое содержание
В тексте изложены принципы работы поисковых систем, результаты исследований экспертов и авторские наработки по продвижению сайтов. При этом книга задумывалась именно как практическое руководство по поисковой оптимизации, поэтому материал представлен в максимально простой форме, а все рекомендации приведены по принципу «бери и делай».
Книга адресована широкому кругу читателей: собственникам и топ-менеджерам бизнеса, начинающим и опытным специалистам по продвижению, интернет-маркетологам, дизайнерам, веб-программистам, студентам, а также всем, чьи интересы и деятельность непосредственно связаны с Интернетом.
В формате PDF A4 сохранен издательский макет.
Поисковое продвижение сайтов - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Универсальных рецептов нет, но важно понимать, что схема конкатенации – это составление шаблонов для определенных видов контента, где на место свободных полей можно подставить конкретные значения с каждой страницы.
Допустим, нужно заполнить метатеги для большого количества продуктовых страниц на сайте интернет-магазина парфюмерии. Для начала необходимо определить, как пользователи движутся по сайту. Пусть это происходит так: главная – категория – продукт. Эти три переменные необходимо заполнить.
Далее определяются дополнительные параметры и слова, которые важны для пользователей. Для этого необходимо проанализировать хвост низкочастотных запросов, который возникает при проверке основного запроса. Например, вот что мы видим при проверке в сервисе Яндекс. Wordstat [24] https://wordstat.yandex.ru/
категории «женские духи»:
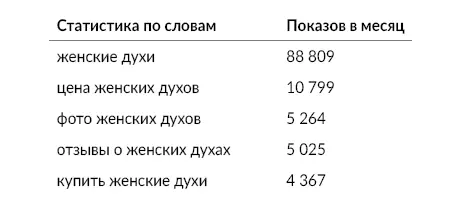
Анализируем таблицу и выбираем то, что волнует покупателей женских духов (цена, фото, отзывы, купить…).
Переходим к построению шаблона заголовка. Например, для страницы с товаром он мог бы быть таким:
{название категории} {название товара} – купить в {название магазина}. Цена от {цена} р., фото, отзывы, доставка.
После подстановки всех переменных получим:
Женские духи Dia Woman – купить в магазине Beauty. Цена от 17 800 р., фото, отзывы, доставка.
С мета-описанием аналогично. Если на страницах сайта есть подробное описание товара – можно планировать схемы детальнее, включать больше параметров и полезной для пользователей информации.
Рекомендуется делать схемы для каждого раздела сайта. Чем детальнее их проработать, тем лучше, хотя стоит помнить о балансе затрат и полученных результатов.
Метатег (ключевые слова)
На заре развития поисковых систем появилась красивая, но наивная идея о том, что веб-мастера будут сами подсказывать поисковым системам те ключевые слова, которым релевантна та или иная веб-страница.
Для реализации этой теории ввели метатег , слова из которого имели серьезное значение при ранжировании документов.
Что произошло дальше, догадаться нетрудно. Веб-мастера и специалисты по продвижению начали запихивать в все ключевые слова, по которым они хотели продвинуть сайт в результатах поиска. На релевантность никто не обращал внимания: зачем эти тонкости, когда можно было в короткий срок продвинуться по всем нужным коммерческим запросам?
Масштаб злоупотреблений достиг такой величины, что поисковые системы вынуждены были свести влияние буквально до нуля, поэтому на данный момент заполнять этот тег бессмысленно.
Если тег все-таки заполняется содержимым (так сказать, на всякий случай), необходимо соблюдать простые правила. Содержимое должно быть уникальным в пределах сайта, все ключевые слова должны быть релевантны странице, и их должно быть немного.
В противном случае поисковые системы могут воспринять содержимое метатега как веб-спам и понизить сайт в результатах поиска.
Метатег
Данный метатег [25] https://developers.google.com/search/reference/robots_metatag?hl=ru
позволяет контролировать сканирование и индексирование сайта поисковыми системами. По умолчанию задаются значения «index, follow» (то же самое, что «all») – дополнительно их прописывать не нужно. Разные поисковики распознают разные значения тега, но универсальными являются два:
– noindex: запрещает индексирование страницы;
– nofollow: запрещает роботу переходить по ссылкам с этой страницы.
Эти значения можно комбинировать, разделяя их запятыми. Например, комбинация
заставит робота поисковиков перейти по всем ссылкам на странице, но не индексировать ее содержимое.Нужно отметить, что использование данного метатега, как правило, свидетельствует о проблемах со структурой сайта. С такими проблемами еще можно мириться на огромном портале, где регулярно возникают трудноустранимые с программной точки зрения «тупики» (страницы, представляющие мало интереса для пользователей и возникающие вследствие несовершенства архитектуры сайта). Но для небольшого проекта это недопустимо.
✍ На заметку
Данное правило является частным случаем другого, более универсального, принципа, который звучит так: «Пользователи и поисковые системы должны видеть одинаковый контент». Если на сайте возникают страницы, содержимое которых нецелесообразно индексировать поисковому роботу, необходимо задуматься о том, а стоит ли их «индексировать» пользователям сайта и какое впечатление такие страницы на них произведут? Не проще ли просто их убрать?
Остается добавить, что использование данного тега для управления индексированием менее предпочтительно по сравнению с правильным формированием файла robots.txt (о нем мы поговорим позже).
10. Поиск и устранение дублей
Идентичный (дублированный) контент на разных страницах сайта может привести к ошибкам индексации и даже свести на нет все усилия по продвижению. Чем опасны дубликаты и почему от них стоит избавляться?
Во-первых, на дубли уходит часть статического веса, а неправильное распределение веса ухудшает ранжирование целевых разделов сайта.
✍ На заметку
Статический вес – это один из важных параметров, влияющих на продвижение сайта в целом и конкретной страницы в частности. Вес определяется количеством и качеством ссылающихся на страницу документов (в основном, html-страниц, но учитываются еще pdf и doc-файлы, а также другие распознаваемые поисковиками документы с гиперссылками).
Во-вторых, на дубли тратится часть драгоценного краулингового бюджета. Особенно остро эта проблема стоит для крупных информационных и e
✍ На заметку
В Интернете триллионы веб-страниц, и каждый день появляются сотни миллионов новых веб-страниц. В этой связи перед поисковыми системами стоит серьезная проблема: как успевать обходить, скачивать и ранжировать все это огромное хозяйство.
Для обхода страниц используются роботы. Поисковый робот («веб-паук», «краулер») – программа, являющаяся составной частью поисковой системы и предназначенная для перебора страниц Интернета и занесения информации о них в базу данных. Очевидно, что каким бы мощным и быстрым не был краулер, скачать единовременно все обновления со всех сайтов у него не получится.
Из-за этого паук скачивает сайты постепенно, небольшими «порциями», например, по нескольку десятков или сотен страниц в день. Размер этой порции на профессиональном сленге специалистов по продвижению и называется краулинговым бюджетом.
Читать дальшеИнтервал:
Закладка:









