Михаил Гук - Аппаратные интерфейсы ПК. Энциклопедия

- Название:Аппаратные интерфейсы ПК. Энциклопедия
- Автор:
- Жанр:
- Издательство:Издательский дом «Питер»
- Год:2002
- Город:Санкт-Петербург
- ISBN:5-94723-180-8
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Михаил Гук - Аппаратные интерфейсы ПК. Энциклопедия краткое содержание
Книга посвящена аппаратным интерфейсам, использующимся в современных персональных компьютерах и окружающих их устройствах. В ней подробно рассмотрены универсальные внешние интерфейсы, специализированные интерфейсы периферийных устройств, интерфейсы устройств хранения данных, электронной памяти, шины расширения, аудио и видеоинтерфейсы, беспроводные интерфейсы, коммуникационные интерфейсы, вспомогательные последовательные интерфейсы. Сведения по интерфейсам включают состав, описание сигналов и их расположение на разъемах, временные диаграммы, регистровые модели интерфейсных адаптеров, способы использования в самостоятельно разрабатываемых устройствах. Книга адресована широкому кругу специалистов, связанных с эксплуатацией ПК, а также разработчикам аппаратных средств компьютеризированной аппаратуры и их программной поддержки.
Аппаратные интерфейсы ПК. Энциклопедия - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Конвейерные транзакции AGP (команды AGP) инициируются только ускорителем; логикой AGP они ставятся в очереди на обслуживание и исполняются в зависимости от приоритета, порядка поступления запросов и готовности данных. Эти транзакции могут быть адресованы ускорителем только к системному ОЗУ. Если устройству AGP требуется обратиться к локальной памяти каких-либо устройств PCI, то оно должно выполнять эти транзакции в режиме PCI. Транзакции, адресованные к устройству AGP, отрабатываются им как ведомым устройством PCI, однако имеется возможность быстрой записи в локальную память FW (Fast Write), в которой данные передаются на скорости AGP (2х или 4х), и управление потоком их передач ближе к протоколу AGP, нежели PCI. Транзакции FW обычно инициируются процессором и предназначены для принудительного «заталкивания» данных в локальную память ускорителя.
Концепцию конвейера AGP иллюстрирует рис. 6.12. Порт AGP может находиться в одном из четырех состояний:
♦ IDLE — покой;
♦ DATA — передача данных конвейеризированных транзакций;
♦ AGP — постановка в очередь команды AGP;
♦ PCI — выполнение транзакции в режиме PCI.
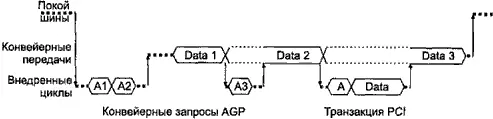
Рис. 6.12. Конвейер AGP
Из состояния покоя IDLE порт может вывести запрос транзакции PCI (как от ускорителя, так и с системной стороны) или запрос AGP (только от ускорителя). В состоянии PCI транзакция PCI выполняется целиком, от подачи адреса и команды до завершения передачи данных. В состоянии AGP ведущее устройство передает только команду и адрес для транзакции (по сигналу PIPE#или через порт SBA), ставящейся в очередь ; несколько запросов могут следовать сразу друг за другом. В состояние DATA порт переходит, когда у него в очереди имеется необслуженная команда, готовая к исполнению. В этом состоянии происходит передача данных для команд, стоящих в очереди. Это состояние может прерываться запросами PCI (для выполнения целой транзакции) ил и AGP (для постановки в очередь новой команды), но прерывание возможно только на границах данных транзакций AGP. Когда порт AGP обслужит все команды, он снова переходит в состояние покоя. Все переходы происходят под управлением арбитра порта AGP, реагирующего на поступающие запросы (REQ# от ускорителя и внешние обращения от процессора или других устройств PCI) и ответы контроллера памяти.
Транзакции AGP некоторыми моментами отличаются от транзакций PCI.
♦ Фаза данных отделена от фазы адреса, чем и обеспечивается конвейеризация.
♦ Используется собственный набор команд.
♦ Транзакции адресуются только к системной памяти, используя то же пространство физических адресов, что и PCI. Транзакции могут иметь длину, кратную 8 байтам, и начинаться только по 8-байтной границе. Транзакции чтения иного размера должны выполняться только в режиме PCI; транзакции записи могут использовать сигналы С/BE[3:0]#для маскирования лишних байтов.
♦ Длина транзакции явно указывается в запросе.
♦ Конвейерные запросы не гарантируют когерентность памяти и кэша. Для операций, требующих когерентности, должны использоваться транзакции PCI.
Возможны два способа подачи команд AGP (постановки запросов в очередь), из которых в текущей конфигурации выбирается один, причем изменение способа «на ходу» не допускается.
♦ Запросы вводятся по шине AD[31:0]и С/BE[3:0]с помощью сигнала PIPE#, по каждому фронту CLKведущее устройство передает очередное двойное слово запроса вместе с кодом команды.
♦ Команды подаются через внеполосные (sideband) линии адреса SBA[7:0]. «Внеполосность» означает, что эти сигналы используются независимо от занятости шины AD. Синхронизация подачи запросов зависит от режима (1х, 2х или 4х).
При подаче команд по шине AD во время активности сигнала PIPE#код команды AGP (CCCC) кодируется сигналами С/BE[3:0], при этом на шине ADпомещается начальный адрес (на AD[31:3]) и длина n (на AD[2:0]) запрашиваемого блока данных. Определены следующие команды:
♦ 0000 (Read) — чтение из памяти (n+1) учетверенных слов (по 8 байт) данных, начиная с указанного адреса;
♦ 0001 (HP Read) — чтение с высоким приоритетом;
♦ 0100 (Write) — запись в память;
♦ 0101 (HP Write) — запись с высоким приоритетом;
♦ 1000 (Long Read) — «длинное» чтение (n+1)×4 учетверенных слов (до 256 байт данных);
♦ 1001 (HP Long Read) — «длинное» чтение с высоким приоритетом;
♦ 1010 (Flush) — очистка, выгрузка данных всех предыдущих команд записи по адресам назначения (на порте AGP выглядит как чтение, возвращающее произвольное учетверенное слово в качестве подтверждения исполнения; адрес и длина, указанные в запросе, значения не имеют);
♦ 1100 (Fence) — установка «ограждений», позволяющих низкоприоритетному потоку записей не пропускать чтения;
♦ 1101 (Dual Address Cycle, DAC) — двухадресный цикл для 64-битной адресации: в первом такте по ADпередается младшая часть адреса и длина запроса, а во втором — старшая часть адреса (по AD) и код исполняемой команды (по С/BE[3:0]).
При внеполосной подаче команд по шине SBA[7:0] передаются 16-битные посылки четырех типов. Каждая посылка передается за два приема, по фронту и спаду синхросигнала. Тип посылки кодируется старшими битами:
♦ тип 1: 0ААА AAAA AAAA ALLL — поле длины (LLL) и младшие биты адреса (А[14:03]);
♦ тип 2: 10СС CCRA AAAA АААА — код команды (CCCC) и средние биты адреса (А[23:15]);
♦ тип 3: 110R AAAA АААА AAAA — старшие биты адреса (А [35:24]);
♦ тип 4: 1110AAAA АААА AAAA — дополнительные старшие биты адреса, если требуется 64-битная адресация.
Посылка из всех единиц является пустой командой ( NOP); они посылаются в покое шины SBA. Биты «R» зарезервированы. Посылки типов 2, 3 и 4 являются «липкими» (sticky) — значения, ими определяемые, сохраняются до введения новой посылки того же типа. Постановку команды в очередь инициирует посылка типа 1, задающая длину транзакции и ее младшие адреса, — код команды и остальная часть адреса должны быть определены ранее введенными посылками типов 2–4. Такой способ очень экономно использует такты шины для подачи команд при пересылках массивов. Синхронизация данных на SBA зависит от режима порта.
♦ В режиме 1х каждая часть передается по фронту CLK; начало посылки (старшая часть) определяется по получению байта, отличного от 11111111b, по последующему фронту передается младшая часть. Очередная команда может вводиться за каждую пару тактов CLK (когда код команды и старший адрес уже введены).
♦ В режиме 2х для SBA используется отдельный строб SB_STB, по его спаду передается старшая часть, а по последующему фронту — младшая. Частота этого строба (но не фаза) совпадает с CLK, так что очередная команда может вводиться в каждом такте CLK .
Интервал:
Закладка:



![Михаил Барятинский - Танки III Рейха. Том III [Самая полная энциклопедия]](/books/1094087/mihail-baryatinskij-tanki-iii-rejha-tom-iii-samaya.webp)





