Б Бёрнс - Распределенные системы. Паттерны проектирования

- Название:Распределенные системы. Паттерны проектирования
- Автор:
- Жанр:
- Издательство:Питер
- Год:2019
- ISBN:978-5-4461-0950-0
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Б Бёрнс - Распределенные системы. Паттерны проектирования краткое содержание
Распределенные системы. Паттерны проектирования - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Введение в микросервисы
С недавних пор термин «микросервисы» стал модным словеч-ком, описывающим системы с многоузловыми распределен-ными архитектурами. Микросервисами называются системы, созданные из множества разных компонентов, работающих в разных процессах и взаимодействующих посредством за-ранее определенных программных интерфейсов. Микросер-висы противопоставляются монолитным системам, которые Часть II. Паттерны проектирования обслуживающих систем 79сосредотачивают функциональность сервиса в одном строго скоординированном приложении. Эти два подхода изображены на рис. II.1 и II.2.
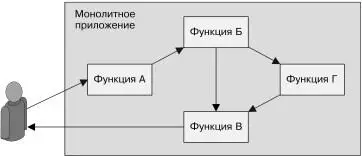
Рис. II.1. Монолитный сервис, вся функциональностькоторого сосредоточена в одном контейнере
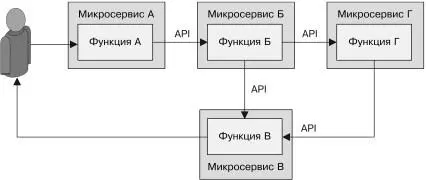
Рис. II.2. Микросервисная архитектура, в которой под каждуюфункцию выделяется отдельный контейнер
Микросервисный подход имеет немало преимуществ, многие из которых связаны с надежностью и гибкостью. Микросервисы делят приложение на небольшие части, каждая из которых от-вечает за предоставление определенной услуги. За счет сужения 80Часть II. Паттерны проектирования обслуживающих систем области действия сервисов каждый сервис в состоянии разра-батывать и поддерживать команда, которую можно накормить двумя пиццами 1. Уменьшение размера команды также снижает расходы на поддержание ее деятельности.
Кроме того, появление формального интерфейса между микросер-висами ослабляет взаимозависимость команд и устанавливает на-дежный контракт между сервисами. Такой формальный контракт снижает потребность в тесной синхронизации команд, поскольку команда, предоставляющая API, понимает, в каком объеме необхо-димо обеспечивать совместимость, а команда, потребляющая API, может рассчитывать на стабильное обслуживание, не заботясь о деталях реализации потребляемого сервиса. Такая декомпозиция позволяет командам независимо управлять темпом разработки и графиком выпуска новых версий, что дает им возможность вы-полнять итерации, улучшая тем самым код сервиса. Наконец, разделение на микросервисы повышает масштаби-руемость. Поскольку каждый компонент выделен в отдельный сервис, его можно масштабировать независимо от остальных. Нечасто случается так, что все сервисы в рамках более крупного приложения развиваются в одном темпе и масштабируются оди-наковым образом. Некоторые системы не имеют внутреннего состояния, и их можно масштабировать горизонтально, в то же время в других системах оно есть и требует шардирования или других подходов к масштабированию. Когда сервисы отделены друг от друга, каждый из них можно масштабировать наиболее подходящим способом. Это невозможно, когда все сервисы яв-ляются частями большого монолитного приложения. Микросервисный подход к проектированию систем, безусловно, имеет и свои недостатки. Два наиболее очевидных недостатка Часть II. Паттерны проектирования обслуживающих систем 81состоят в том, что связи внутри системы становятся слабее, а значит, отладка системы в случае отказа становится намного сложнее. Больше не получится загрузить в отладчик одно при-ложение и выяснить, что идет не так. Любая ошибка оказыва-ется следствием того, что большое количество систем работает на большом количестве машин. Такую среду сложно воспроиз-вести в отладчике. Неизбежным итогом этого является также и то, что микросервисные системы сложно проектировать и от-лаживать. Системы, основанные на микросервисах, используют различные способы и схемы взаимодействия между сервисами (синхронный, асинхронный, передача сообщений и т. п.), а так-же множество различных паттернов координации и управления сервисами.
Эти проблемы обуславливают потребность в распределенных паттернах. Когда микросервисная архитектура состоит из хо-рошо известных паттернов, ее проще проектировать, поскольку многие принципы проектирования уже закодированы в паттер-нах. Кроме того, паттерны упрощают отладку систем, поскольку позволяют разработчикам применять опыт, полученный при отладке других систем, спроектированных с использованием таких же паттернов.
В этой части вы познакомитесь с несколькими многоузловыми паттернами построения распределенных систем. Они не явля-ются взаимно исключающими. Любая реальная система стро-ится на основе набора паттернов, взаимодействующих в рамках
одного высокоуровневого приложения.
5 Реплицированные сервисы с распределением
нагрузки
Реплицированный сервис с распределением нагрузки — простей-ший распределенный паттерн, известный многим. В рамках такого сервиса все серверы идентичны друг другу и поддерживают входя-щий трафик. Паттерн состоит из масштабируемого набора серве-ров, находящихся за балансировщиком нагрузки. Балансировщик обычно распределяет нагрузку либо по карусельному (round-robin) принципу, либо с применением некоторой разновидности закре-пления сессий. В данной главе приводится конкретный пример развертывания такого сервиса с помощью Kubernetes. Сервисы без внутреннего состояния Сервисы без внутреннего состояния (stateless-сервисы) не требуют для своей работы сохранения состояния. В простейших приложе-Глава 5. Реплицированные сервисы с распределением нагрузки 83ниях, не хранящих состояние (stateless-приложениях), отдельные запросы могут быть направлены разным экземплярам сервиса. Примеры stateless-сервисов включают как сервисы доставки ста-тического контента, так и сложные промежуточные системы, при-нимающие и агрегирующие запросы от серверных сервисов.
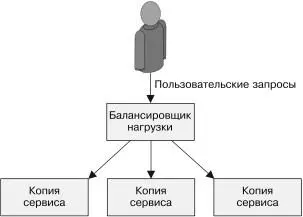
Рис. 5.1. Простой реплицированный stateless-сервис
Системы, не хранящие состояние, реплицируются для обеспе-чения избыточности и масштабируемости. Сколь угодно малый сервис требует минимум двух копий для обеспечения уровня «высокой доступности» соглашения об уровне услуг (SLA). Чтобы понять, почему это так, рассмотрим предоставление сер-
виса с уровнем доступности «три девятки» (99,9 %). У сервиса с уровнем доступности 99,9 % в день есть 1,4 минуты на простой (24 × 60 × 0,001). Даже исходя из того, что ваш сервис никогда не отказывает, у вас есть не более 1,4 минуты на обновление про-граммного обеспечения, чтобы соблюсти уровень обслуживания при использовании одного экземпляра сервиса. И это с учетом, что вы обновляете программное обеспечение раз в день. Если ваша команда серьезно вступила на путь Continuous Delivery и вы выпускаете новую версию приложения каждый час, то 84Часть II. Паттерны проектирования обслуживающих систем у вас есть не более 3,6 секунды на развертывание очередной вер-сии, чтобы соблюсти уровень обслуживания 99,9 % при исполь-зовании одного экземпляра сервиса. Стоит чуть задержаться — и вы уже не вписываетесь в заявленные 0,1 % времени простоя. Можно, конечно, вместо этого всего добавить вторую копию сервиса и балансировщик нагрузки. Таким образом, пока вы развертываете новую версию или восстанавливаете один эк-земпляр сервиса после сбоя (что, надеюсь, происходит нечасто), ваших ничего не подозревающих пользователей будет обслужи-вать второй его экземпляр.
Читать дальшеИнтервал:
Закладка:


