Б Бёрнс - Распределенные системы. Паттерны проектирования

- Название:Распределенные системы. Паттерны проектирования
- Автор:
- Жанр:
- Издательство:Питер
- Год:2019
- ISBN:978-5-4461-0950-0
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Б Бёрнс - Распределенные системы. Паттерны проектирования краткое содержание
Распределенные системы. Паттерны проектирования - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:

Рис. 5.4. Работа кэширующего сервера
Для наших целей воспользуемся кэширующим веб-сервером Varnish с открытым исходным кодом ( https://varnish-cache.org/ ). Развертывание кэширующего сервера Простейший способ развертывания веб-кэша — рядом с каж-дым экземпляром сервиса при использовании паттерна Sidecar (рис. 5.5).
Такой подход при всей простоте имеет недостатки. В частности, вам придется масштабировать кэш одновременно с приложени-ем. Это не всегда желательно. Для кэша следует использовать наименьшее количество экземпляров с наибольшим количеством памяти (например, не десять копий с 1 Гбайт памяти у каждой, а две копии с 5 Гбайт памяти у каждой). Для того чтобы понять, почему так лучше, представьте, что каждая страница кэширует-ся в каждом экземпляре. При десяти экземплярах кэша каждая Глава 5. Реплицированные сервисы с распределением нагрузки 91
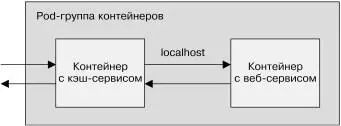
Рис. 5.5. Добавление кэширующего веб-сервера
в виде контейнера-прицепа
страница будет записана десять раз, что уменьшит общее коли-чество разных страниц, одновременно находящихся в кэше. Это снижает коэффициент попадания — долю запросов, обслужива-емых из кэша, что, в свою очередь, уменьшает полезность кэша. И хотя желательно иметь как можно меньше крупных экземпля-ров кэш-серверов, небольших экземпляров веб-серверов должно быть как можно больше. Многие языки, например NodeJS, могут задействовать только одно процессорное ядро, и поэтому имеет смысл создавать много экземпляров сервиса, чтобы в полной мере использовать преимущества многоядерных систем, даже в рамках одной машины. Следовательно, имеет смысл настроить кэширу-ющую прослойку как другой реплицированный stateless-сервис, находящийся над веб-сервисом (рис. 5.6).
 конечного пользователя сервиса. Если вы, следуя при-веденному ранее совету, развернули небольшое количе-ство кэш-серверов, привязка IP-адресов могла произойти таким образом, что некоторые экземпляры веб-сервиса не получают трафика. Вместо привязки сессии к IP следует
конечного пользователя сервиса. Если вы, следуя при-веденному ранее совету, развернули небольшое количе-ство кэш-серверов, привязка IP-адресов могла произойти таким образом, что некоторые экземпляры веб-сервиса не получают трафика. Вместо привязки сессии к IP следует
92Часть II. Паттерны проектирования обслуживающих систем
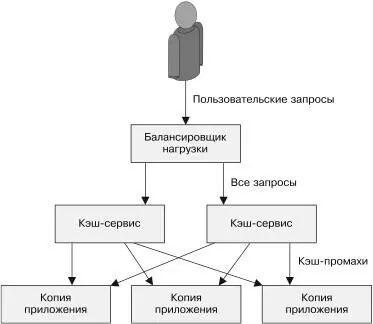
Рис. 5.6. Добавление кэширующей прослойки к реплицированному сервисуПрактикум. Развертывание кэширующей прослойки
Сервис dictionary-server, который мы развернули ранее, распре-деляет трафик по экземплярам сервера-словаря и может быть найден по DNS-имени dictionary-server-service . Данный паттерн изображен на рис. 5.7.
Начнем создание кэширующей прослойки с настройки кэши-рующего сервера Varnish:
vcl 4.0;
backend default {
.host = "dictionary-server-service";
.port = "8080";
Глава 5. Реплицированные сервисы с распределением нагрузки 93
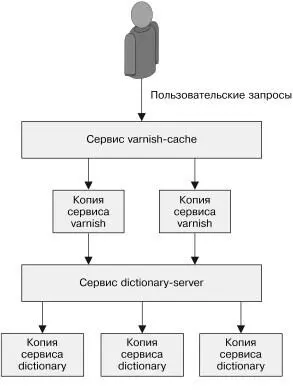
Рис. 5.7. Добавление кэширующей прослойки
к серверу-словарю
Создадим объект ConfigMap , содержащий указанную конфигу-рацию:
kubectl create configmap varnish-config
--from-file=default.vcl
Теперь можно разворачивать реплицированный Varnish-кэш на основе следующего конфигурационного файла: apiVersion: extensions/v1beta1
kind: Deployment
metadata:
94Часть II. Паттерны проектирования обслуживающих систем name: varnish-cache
spec:
replicas: 2
template:
metadata:
labels:
app: varnish-cache
spec:
containers:
- name: cache
resources:
requests:
# Зарезервируем 2 Гбайт памяти
# для каждого экземпляра Varnish-кэша
memory: 2Gi
image: brendanburns/varnish
command:
- varnishd
- -F
- -f
- /etc/varnish-config/default.vcl
- -a
- 0.0.0.0:8080
- -s
# Количество выделяемой здесь памяти должно
# соответствовать количеству зарезервированной
# памяти, указанному ранее
- malloc,2G
ports:
- containerPort: 8080
volumeMounts:
- name: varnish
mountPath: /etc/varnish-config
volumes:
- name: varnish
configMap:
name: varnish-config
Развернуть реплицированные Varnish-серверы можно следу-ющей командой:
kubectl create -f varnish-deploy.yaml
Глава 5. Реплицированные сервисы с распределением нагрузки 95Наконец, развернем балансировщик нагрузки для Varnish-кэша: kind: Service
apiVersion: v1
metadata:
name: varnish-service
spec:
selector:
app: varnish-cache
ports:
- protocol: TCP
port: 80
targetPort: 8080
Создать его можно с помощью такой команды: kubectl create -f varnish-service.yaml
Расширение возможностей кэширующей прослойки
Теперь, когда мы развернули кэширующую прослойку для реплицированного stateless-сервиса, посмотрим, что еще он умеет делать, кроме собственно кэширования. Обратные HTTP-прокси вроде Varnish обычно имеют возможность расширения и, помимо кэширования, могут предоставлять дополнительные возможности.
Ограничение частоты запросов и защита от атак типа «отказ в обслуживании» (DoS) Некоторые специалисты проектируют сайты с учетом защиты от DoS-атак. Все больше разработчиков сегодня проектируют программные интерфейсы. В связи с этим отказ в обслужива-нии может произойти из-за того, что разработчик некорректно настроил клиент, либо из-за того, что инженер, ответственный за доступность сайта, случайно запустил нагрузочные тесты 96Часть II. Паттерны проектирования обслуживающих систем на рабочем сервере. Следовательно, имеет смысл добавить в кэширующую прослойку защиту от отказа в обслуживании, установив ограничение частоты запросов. Большинство об-ратных HTTP-прокси, например Varnish, поддерживают нечто похожее. В частности, у Varnish есть модуль throttle, который можно настроить так, чтобы он ограничивал частоту запросов с определенным путем с конкретных IP-адресов, в том числе для анонимных или зарегистрированных пользователей. Если вы развертываете API, целесообразно иметь достаточно низкий лимит запросов для анонимных пользователей, кото-рый можно повысить после регистрации. Требуя авторизации, мы сможем проводить аудит, чтобы определить, чьи действия привели к неожиданно высокой нагрузке. Ограничение частоты запросов также служит барьером для потенциальных взлом-щиков, которым понадобится замаскироваться под нескольких пользователей, чтобы успешно реализовать атаку. Когда количество запросов от одного пользователя достигает определенного лимита, сервер вернет ему ошибку с кодом 429, означающую превышение количества максимально допустимых запросов. Многим пользователям нужно будет знать, сколько еще они могут сделать запросов, прежде чем достигнут лими-та. В связи с этим вам может понадобиться добавить в HTTP-заголовок информацию о количестве оставшихся запросов. Для подобной информации нет стандартного поля в HTTP-заголовке, однако многие API возвращают одну из разновид-ностей поля X-RateLimit-Remaining .
Читать дальшеИнтервал:
Закладка:


