Компьютерра - Журнал «Компьютерра» № 25-26 от 11 июля 2006 года (645 и 646 номер)

- Название:Журнал «Компьютерра» № 25-26 от 11 июля 2006 года (645 и 646 номер)
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:неизвестен
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Компьютерра - Журнал «Компьютерра» № 25-26 от 11 июля 2006 года (645 и 646 номер) краткое содержание
Журнал «Компьютерра» № 25-26 от 11 июля 2006 года (645 и 646 номер) - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
И никогда не нужно забывать, что «машина» знает только то, что мы ей смогли сообщить. А избыточное доверие к результатам вычислений… Приведу следующий пример.
Идет защита докторской диссертации крупного специалиста по… ну, скажем, «мышам». Автор представляет материал со всей Евразии — десятки видов, десятки признаков. Для определения сходства и различия между видами используется кластерный анализ. Для самок и самцов строятся независимые кладограммы (древовидные графы, отражающие уровень сходства внутри иерархически соподчиненных групп). Кладограмма самцов имеет достаточно обычный вид, а вот самок выглядит странно (рис. 2). Эти кладограммы вставлены в разосланный по городам и весям автореферат докторской и демонстрируются на защите.
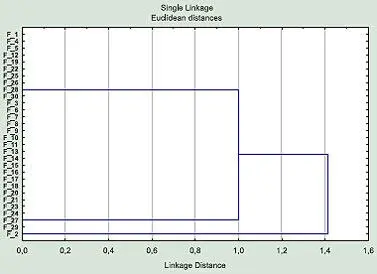
Диссертант говорит, что изменчивость самок и самцов подчиняется разным закономерностям, и обращает внимание на то, что самки формируют две группы, внутри которых они не отличаются друг от друга. На основании этого ему удается сделать некоторые выводы и предположения. Ни один из специалистов, присутствующих на защите или приславших отзывы на автореферат, не задает элементарный вопрос: почему же тогда их относят к разным видам и даже разным группам видов, раз по всем изученным признакам они идентичны?
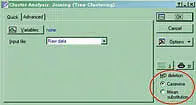
Ларчик открывается просто. Дело в том, что при проведении кластерного анализа в программе Statistica необходимо решить, что же делать с пустыми ячейками в таблице объекты/признаки. По умолчанию в соответствующем модуле (рис. 3) стоит опция «Casewise», означающая, что признак, по которому не определен хотя бы один из объектов, вообще выбрасывается из рассмотрения. В нашем примере это означает, что особи классифицировались лишь по двум признакам [Последние версии Statistica отказываются работать по одному признаку, а предыдущие соглашались даже на это. В цитируемой диссертации был использован всего один признак, но, создавая аналогичную картинку, я вынужден был добавить еще один, чтобы ублажить более привередливую версию программы], каждый из которых может принимать всего два значения (например, есть кисточки на ушах или нет).
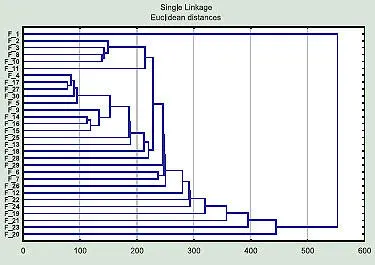
Чтобы компенсировать «дыры» в данных, необходимо выбрать опцию «Mean substitution». При таком выборе отсутствующее значение заменится средним для всей совокупности объектов и окажет наименьшее влияние на конечный результат (разумеется, еще лучшее решение — определить все признаки для всех объектов). Выбрав замену средним значением, мы можем получить дерево, напоминающее приведенное для самцов (рис. 4).
На престижном научном форуме была представлена работа, касающаяся выделения морфотипов (групп организмов, объединенных сходством) в популяциях животных, которые мы назовем «воронами». На протяжении многих лет я интересуюсь гипотетической возможностью корректно описать популяционное разнообразие посредством выделения нескольких морфотипов особей, чтобы потом сравнивать популяции по частотам этих типов. И вот я вижу работу, в которой это удалось сделать…
Наличие нескольких типов в популяции «ворон» иллюстрируется картиной, которая аналогична показанной на рис. 5. Здесь использовано объединение в кластеры по методу Уорда (Ward’s method). Этот метод строит кластеры (группы) так, чтобы получающаяся внутри групповая дисперсия была минимальна. К сожалению, кластеры, которые выделялись при исследованиях одной выборки, не соответствовали кластерам, которые удавалось увидеть аналогичными методами в другой.
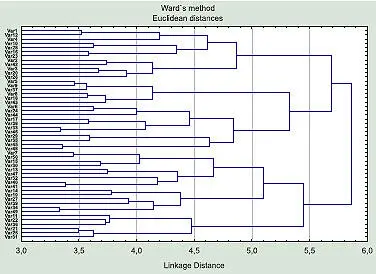
Вернувшись в гостиницу, я построил таблицу, заполненную шумом (так, формула «=Rnd(1)» в заголовке столбца приводит к его заполнению псевдослучайными числами от 0 до 1). Кластеризовав эти случайные объекты с использованием тех же методов, я получил «морфотипы», объединенные примерно на том же уровне сходства, что и в работе про «ворон» (рис. 5). Что характерно, на ее автора это не произвело никакого впечатления: «Ну и что, что и в случайном материале выделяются группы? У меня же материал не случайный!»
Выделение типов имеет смысл только в том случае, если они отделены друг от друга определенным разрывом. Если мы анализируем с помощью методов кластерного анализа совокупность объектов, относящихся к отграниченным друг от друга типам, построенные в ходе анализа кластеры будут соответствовать этим типам. Если же типов в структуре самого материала нет, анализ все равно построит кластеры: ничем другим работа его алгоритмов закончиться не может.
Описанные выше ошибки в использовании статистики были яркими, но достаточно редкими. Теперь я с содроганием от собственной наглости [И выражением благодарности замечательному специалисту в области биометрии С. Н. Шамраю, который помог мне разобраться в этом вопросе, но не несет никакой моральной ответственности за мои возможные ошибки] должен приступить к обсуждению ошибки, которая является нормой для множества работ, как в моей узкой специальности, так и в изучении смежных групп.
Как систематик описывает разнообразие организмов? Упрощая, можно сказать, что он собирает в разных регионах серии подобных животных, сравнивает их друг с другом и решает, относятся ли они к одной форме, к разным подвидам или к разным видам. Новые подвиды и виды описывают, указывая их отличия от старых, ранее известных. В старые времена это сравнение проводилось в основном на основании интуиции систематика: его профессиональный взгляд мог (или не мог) выделить признаки, на основании которых принималось то или иное решение. Сейчас свое решение принято подтверждать статистическими методами. Как это делают чаще всего?
Собирают две серии объектов (например, уклеек из бассейна реки А и из бассейна реки Б), описывают их по максимальному количеству признаков, допускающих их представление в виде чисел, а потом сравнивают по всем этим признакам по критериям Стьюдента и Фишера (см. врезку). Послушная Statisticа подсветит красным те признаки, по которым найдутся достоверные отличия. Дальше смотрим, сколько таких признаков найдется и на какой статус отличий они потянут. Например, в авторитетнейшем для моей отрасли науки отечественном методическом сборнике один из классиков указывал, что два достоверных отличия — мало для описания подвида, а вот три — в самый раз.
Читать дальшеИнтервал:
Закладка:









