Валентин Арьков - Эконометрические оценки. Учебное пособие

- Название:Эконометрические оценки. Учебное пособие
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:неизвестен
- ISBN:9785005530646
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Валентин Арьков - Эконометрические оценки. Учебное пособие краткое содержание
Эконометрические оценки. Учебное пособие - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Надо понимать, что у самого Excel есть ограничение по количеству строк на одном листе электронной таблицы. Их может быть чуть больше 1 миллиона. То есть полтора или два миллиона строк вы уже не сможете создать на одном листе.
Но если вы захотите сгенерировать свой «разрешённый» миллион случайных чисел с помощью надстройки, то может и не получиться. Попробуйте выяснить, до какого предела можно генерировать с помощью надстройки. Это тоже интересный эксперимент.
Итак, вам предстоит повторить показанные опыты двумя способами – как мы с вами разбирали – с помощью надстройки Анализ данных и с помощью функции RAND, см. рис.

Рис. План задания
Вам предстоит сгенерировать 10000 случайных чисел и повторить этот опыт 10 раз. Затем записать ваши оценки вероятности. Можете записать от руки в конспект или приложить копию экрана, чтобы показать, что вы это проделали.
Вот таким образом мы с вами знакомимся с понятием вероятности. Вероятность существует в теории. Мы на неё можем посмотреть через обработку данных, но каждый раз это число будет немножко отличаться. Она будет близкой к настоящему, правильному, теоретическому значению. Но каждый раз она будет отличаться. Это явление природы называется словом ОЦЕНКА. Как видим, оценка тоже содержит себе некоторую случайность, некоторую непредсказуемость, маленькую случайную ошибку. Насколько она маленькая, что с этим делать и как дальше работать? Эти тонкости и будут темой следующего занятия.
В данном занятии мы посмотрели на так называемые псевдослучайные числа – то есть они на самом деле не совсем случайные. Нам только кажется что они случайные. Генерируется последовательность, которая зависит от начального состояния. Мы увидим этот инструмент и в Excel, и в любых других программных генераторах, в том числе, и в питоне. То есть в Python.
Libre Office Calc – надстройка
Проведём ещё один эксперимент. Нам предстоит как сгенерировать случайные числа в электронной таблице Libre Office Calc. Calc – это сокращение от слова «Калькулятор».
Основная идея всё та же – вызвать генератор через надстройку. Немного отличается верхнее меню, но разобраться будет несложно.

Рис. План демонстрации
В верхнем меню выбираем Sheet – Fill Cells – Fill Random Number, см. рис.
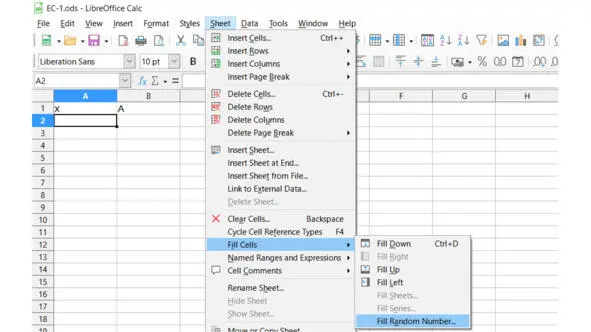
Рис. Вызов генератора случайных чисел
Появляется меню настройки генератора случайных чисел, см. рис. Выбираем равномерное распределение: Distribution – Uniform. Значения Minimum / Maximum: от нуля до единицы. Диапазон адресов ячеек Cell range – А2:А10001. Как видим, здесь у нас имеется дополнительная галочка Enable custom seed, если мы вручную задаём начальное состояние генератора.
Есть дополнительная возможность сразу же и округлять полученные случайные числа – Enable rounding. Но мы просто повторим предыдущие шаги, чтобы увидеть, насколько похожи все электронные таблицы.
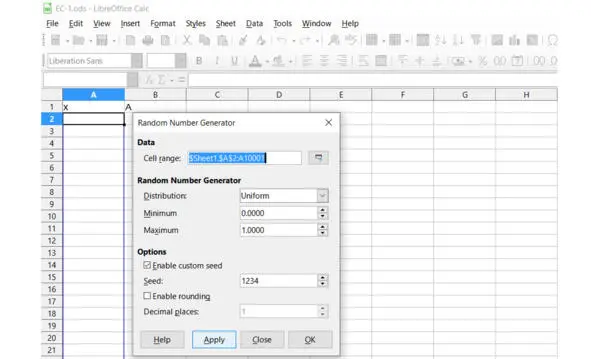
Рис. Настройка генератора случайных чисел
Далее мы округляем эти числа и находим среднее значение, см. рис. Функции такие же, как в Excel. Это обеспечивает почти полную совместимость на уровне файлов, включая названия функций.
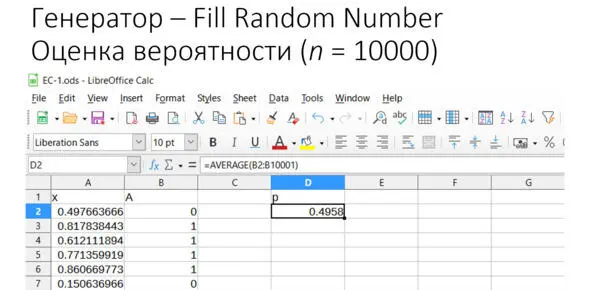
Рис. Результаты моделирования
Как можно видеть, и в этом примере оценка вероятности приблизительно соответствует точному, теоретическому значению 0,5.
Libre Office Calc – функция
Проведём ещё один эксперимент – по примеру того, что мы проделали в Excel с вызовом функции RAND, см. рис.

Рис. План демонстрации
Вводим функцию RANDв ячейку А2.
Затем вызываем заполнение диапазона нашей формулой: Sheet – Fill Cells – Fill Down, см. рис.
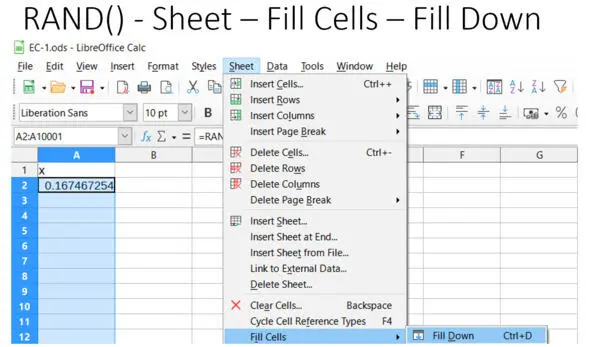
Рис. Заполнение ячеек
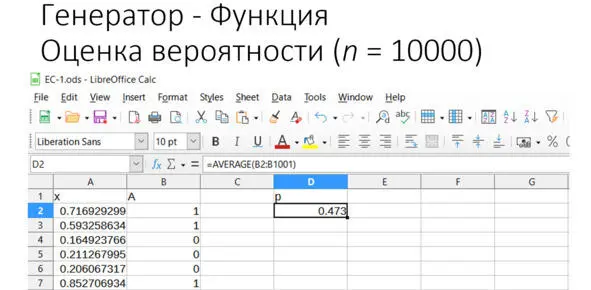
Рис. Результаты моделирования
Как видим, мы можем заполнять ячейки почти так же, как мы это проделали в Excel. Названия функций тоже совпадают. Во многом это объясняется тем, что пользователи ожидают совместимость на уровне файлов. А в файлах могут быть не только числа, но и вызовы функций. В нашем примере это функции RAND, ROUNDи AVERAGE.
В результате мы тоже получили оценку вероятности около 0,5. И тоже с небольшой погрешностью. И эта случайность тоже заметна при многократном повторении опыта.
Когда мы вызываем генератор через функцию, электронная таблица пересчитывает все значения при любых изменениях, при обновлении таблицы и при сохранении файла. Все оценки будут вокруг теоретического значения 0,5, но все будут немного разными – плюс-минус.
Вам предстоит проделать показанные эксперименты. Повторите этот опыт несколько раз, чтобы убедиться, что оценка вероятности немного меняется. Но в среднем оценка «крутится» вокруг точного значения, см. рис.

Рис. План задания
Jupyter Lab
Следующий эксперимент мы проделаем в питоне. Или в Python – если больше нравятся английские названия.
Здесь мы с вами познакомимся с некоторыми приемами работы в диалоговой среде Anaconda / Jupyter Lab и некоторыми командами Python.
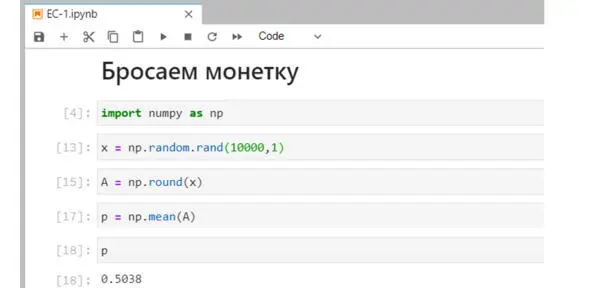
Рис. Программа в Jupyter Lab
В первой строчке мы импортируем библиотеку numpyи назначаем ей псевдоним np – для краткости. Это библиотека для работы с числовыми массивами. В обычном, базовом питоне мы тоже можем создавать различные объекты. Однако, numpyпозволяет работать с матрицами, то есть с массивами / таблицами чисел. Это могут быть столбцы, или строки, или таблички чисел. Все они условно называются массивами.
Читать дальшеИнтервал:
Закладка: