Валентин Арьков - Эконометрические оценки. Учебное пособие

- Название:Эконометрические оценки. Учебное пособие
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:неизвестен
- ISBN:9785005530646
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Валентин Арьков - Эконометрические оценки. Учебное пособие краткое содержание
Эконометрические оценки. Учебное пособие - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Дальше мы будем обращаться к функциям из этой библиотеки np.
Вторая строка – вызов генератора случайных чисел с равномерным распределением. В аргументах функции randуказываем размеры массива, который хотим получить: 10000 строк и 1 столбец.
Следующим шагом мы округляем эти числа с помощью функции round.
Далее находим среднее значение для всего этого массива чисел. Это делает функция mean. Полученную оценку вероятности выводим на экран.
Здесь надо отметить один любопытный момент. Функции для вычисления среднего значения могут называться MEANи AVERAGE. Могут быть и другие названия. Причём это происходит в рамках одного пакета программ – если это делали в разное время и разные команды разработчиков. За этим приходится следить. Конечно же, мы всегда можем посмотреть справку под названием help. Там же обычно даются примеры использования команды.
Запускаем нашу программу несколько раз и наблюдаем, что выводится на экран в качестве оценки вероятности.
Google Colab
Мы можем проделать наши опыты с теми же результатами и в облачном сервисе Google Colaboratory, см. рис.

Рис. Программма в Google Colab
Внешне всё очень похоже на Anaconda / Jupyter Lab. Мы получаем практически стопроцентную совместимость с программой, отлаженной на локальном компьютере. Тем не менее, иногда бывает тонкости. Colab работает с самыми последними версиями библиотек. И нам не требуется постоянно их обновлять вручную.
Итак, мы запускаем Colab. Нас спрашивают, хотим ли мы открыть существующий файл или создать новый. Создаем новый блокнот.
Вводим первую команду, нажимаем комбинацию клавиш [Shift+Enter]. Проходит некоторое время на запуск – в правой верхней части экрана выводится сообщение про соединение с виртуальной машиной: Connect.
Обратим внимание, что при вводе функцию сразу появляется всплывающая подсказка.
Когда ячейка выполнилась, слева от этой ячейки блокнота видим комментарий в квадратных скобках – выводится какое-то число. Это порядковый номер выполненной ячейки. Ячейки можно запускать в разном порядке, и это будет отображаться в квадратных скобках.
И ещё один момент: при вычислении среднего значения не уточняется метод расчёта. В описании функции говорится: arithmetic mean, то есть среднее арифметическое. На занятиях по статистике вы можете узнать, что среднее можно считать десятью разными способами. Но средняя арифметическая простая используется чаще всего.
Чтобы вывести полученную оценку на экран мы просто вводим имя переменной.
Запускаем несколько раз: Runtime – Run All.
Для вывода на экран можно также использовать команду print. Это обеспечит побольше знаков после запятой. Здесь можно задать любой формат вывода.
Подведём итоги. Неважно, какими средствами анализа мы пользуемся. Результаты обработки данных каждый раз представляют собой случайные числа. Они будут приближаться к точному, правильному значению. Но оценка содержит внутри себя случайность.
Ваша задача – потренироваться и убедиться в следующем. Оценки – это результат обработки реальных данных. Исходные данные содержат случайность. Поэтому оценки тоже являются случайными числами. Нужно проделать этот опыт на локальном компьютере и в облаке, см. рис.

Рис. План задания
4. Распределение
Наша следующая тема – распределение. А точнее, распределение вероятностей. Это понятие из теории вероятностей.
Чтобы всё запутать, у нас есть ещё одно понятие распределения – в экономике. Это касается дистрибуции, когда оптом берут крупную партию товара и развозят по магазинам мелкими партиями. Конечно, это не имеет никакого отношения к распределению в статистике.
Нас будет интересовать статистика, эконометрика, теория вероятности. Здесь распределение – это зависимость, показанная на рис.
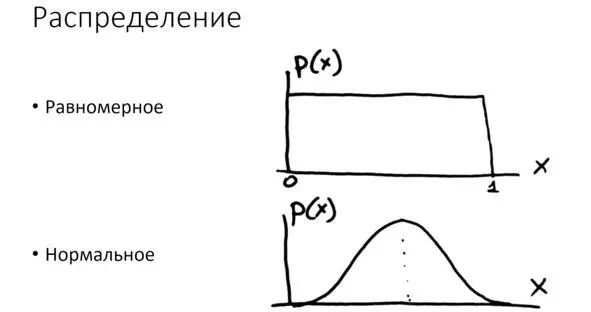
Рис. Примеры стандартных распределений
Итак, распределение – это вероятность появления разных значений какой-то случайной величины. На рисунке приведены два примера – равномерное и нормальное распределение. Мы их подробно исследовали на лабораторных работах по статистике.
При использовании программного генератора достаточно указать название распределения и его параметры.
Нормальное распределение имеет один пик. В целом, такая форма кривой называется колоколообразной. То есть она похожа по форме на колокол.
Соответствующее английское название – Probability Distribution. Probability – это вероятность. Distribution – распределение.
Распределение вероятностей – это вероятность появления разных значений случайной величины. Когда мы обрабатываем реальные данные, эту вероятность мы можем найти только приблизительно с помощью оценок. На практике распределение – это частота появления разных значений. Что-то бывает чаще, что-то бывает реже.
Чтобы сгенерировать случайные числа, мы используем программный генератор.
Рис. Запуск генератора
Всё начинается с равномерного распределения. Случайное число от нуля до единицы. Это считается своеобразным стандартом, строительным «кирпичиком» для реализации любого другого распределения.
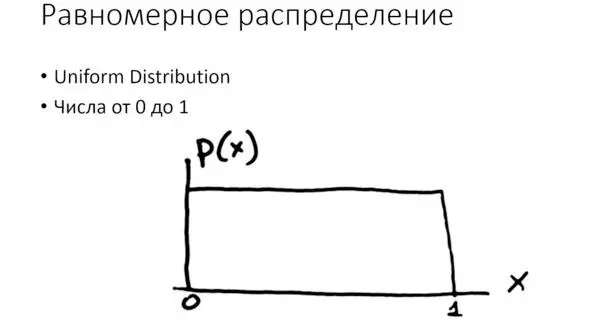
Рис. Стандартное нормальное распределение
В некоторых случаях мы можем вручную указать тот диапазон значений, который нас интересует. Стандартные параметры – это диапазон значений от нуля до единицы.
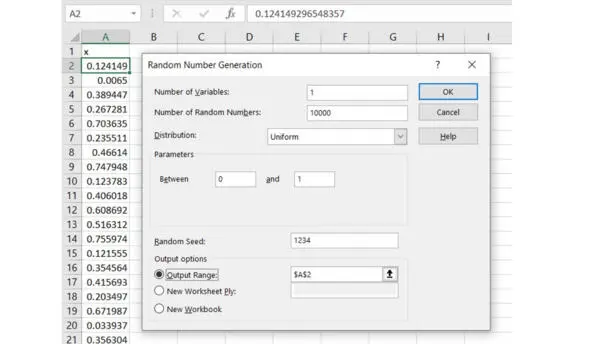
Рис. Настройка генератора
Запускаем генератор случайных чисел. В диалоговом окне указываем число переменных, см. рис. Напомним, что переменные в электронных таблицах и во многих других случаях располагаются по столбцам. Это имеет отношение к истории. Традиционно, задолго до появления компьютеров числа записывали в колонку. Внизу столбца подсчитать сумму. Вручную числа удобно складывать столбиком. Соответственно, и в компьютерах используется традиционное расположение данных. Оно интуитивно понятно.
Читать дальшеИнтервал:
Закладка: