Джон Келлехер - Наука о данных. Базовый курс

- Название:Наука о данных. Базовый курс
- Автор:
- Жанр:
- Издательство:Альпина Паблишер
- Год:2020
- Город:Москва
- ISBN:978-5-9614-3378-4
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Джон Келлехер - Наука о данных. Базовый курс краткое содержание
Книга знакомит с основами науки о данных. В ней охватываются все ключевые аспекты, начиная с истории развития сбора и анализа данных и заканчивая этическими проблемами, связанными с конфиденциальностью информации. Авторы объясняют, как работают нейронные сети и машинное обучение, приводят примеры анализа бизнес-проблем и того, как их можно решить, рассказывают о сферах, на которые наука о данных окажет наибольшее влияние в будущем.
«Наука о данных» уже переведена на японский, корейский и китайский языки.
Наука о данных. Базовый курс - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Рис. 6 дает обзор типичной архитектуры данных. Эта архитектура предназначена не только для больших данных, но и для данных любого размера. Диаграмма состоит из трех основных частей: уровня источников данных, на котором генерируются все данные в организации; уровня хранения данных, на котором данные хранятся и обрабатываются, и уровня приложений, на котором данные передаются потребителям этих данных и информации, а также различным приложениям.
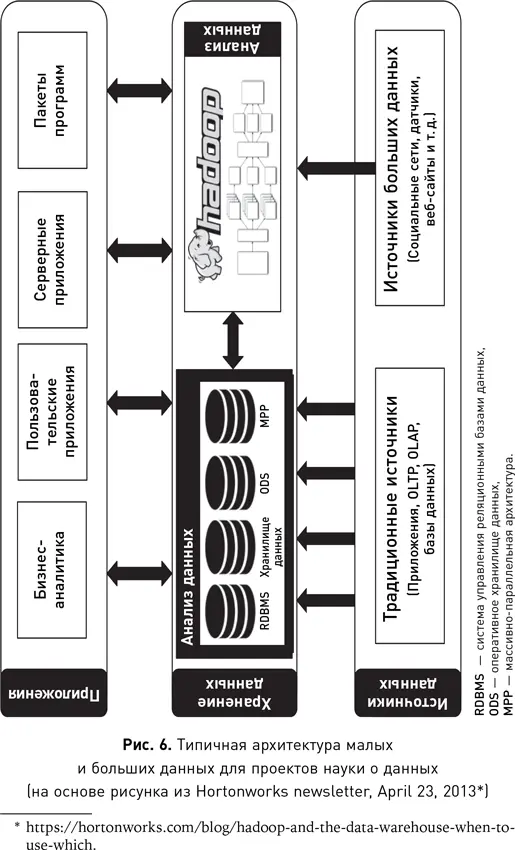
У каждой организации есть приложения, которые генерируют и собирают данные о клиентах, транзакциях и обо всем, что связано с работой организации (операционные данные). Это источники и приложения следующих типов: управление клиентами, заказы, производство, доставка, выставление счетов, банкинг, финансы, управление взаимодействием с клиентами (CRM), кол-центр, ERP и т. д. Приложения такого типа обычно называют системами обработки транзакций в реальном времени, или OLTP. Во многих проектах науки о данных именно эти приложения используются как источник входного набора данных для алгоритмов машинного обучения. Со временем объем данных, собираемых различными приложениями по всей организации, становится все больше и начинает включать данные, которые ранее были проигнорированы, недоступны или не были собраны по иным причинам. Эти новые источники, как правило, относятся уже к большим данным, поскольку их объем значительно выше, чем объем данных основных операционных приложений организации. Распространенные источники — это сетевой трафик, регистрационные данные различных приложений, данные датчиков, веб-журналов, социальных сетей, веб-сайтов и т. д. В традиционных источниках данные обычно хранятся в базе. Новые источники больших данных часто не предназначены для длительного их хранения, как в случае с потоковыми данными, поэтому форматы и структуры хранения будут варьироваться от приложения к приложению.
По мере увеличения количества источников возрастает проблема использования данных в аналитике и обмена ими между удаленными частями организации. Из истории (см. главу 1) нам известно, что хранение данных стало ключевым компонентом аналитики. В хранилище данные, поступающие со всей организации, интегрируются и становятся доступными для приложений (OLAP) и дальнейшего анализа.
Слой хранения данных, представленный на рис. 6, предназначен для обмена данными и их анализа. При этом он разделен на две части. Первая охватывает программное обеспечение для обмена данными, используемое большинством организаций. Наиболее популярным типом традиционного ПО для интеграции и хранения данных остаются реляционные базы данных (RDBMS). Это ПО часто служит основой для систем бизнес-аналитики (BI) в организациях. BI-системы призваны облегчить процесс принятия решений для бизнеса. Они предоставляют функции агрегирования, интеграции, отчетности и анализа. В основе BI-систем лежат базы данных, которые содержат интегрированные, очищенные, стандартизированные и структурированные данные, поступающие из различных источников. В зависимости от уровня зрелости архитектура BI-систем может состоять из очень разных компонентов — от базовой копии рабочего приложения и оперативного склада данных (ODS) до массивно-параллельных (MPP) решений баз данных BI и хранилищ данных. Аналитику, сгенерированную BI-системой, можно использовать в качестве входных данных для ряда потребителей на уровне приложений (рис. 6).
Вторая часть слоя хранения данных занимается управлением большими данными организации. Архитектура для их хранения и анализа включает платформу с открытым исходным кодом Hadoop, разработанную Apache Software Foundation для обработки больших данных. Эта платформа осуществляет распределенное хранение и обработку данных прямо в кластерах стандартных серверов. Для ускорения обработки запросов в наборах больших данных используется модель программирования MapReduce, которая реализует стратегию разделения — использования — объединения : a) большой набор данных разбивается на фрагменты, и каждый блок сохраняется в отдельном узле кластера; б) затем ко всем фрагментам применяется параллельный запрос; в) результат запроса вычисляется путем объединения результатов, сгенерированных для разных фрагментов. Кроме того, в последние годы платформа Hadoop стала использоваться для расширения корпоративных хранилищ данных. Не так давно хранилища вмещали данные за три года, но теперь это число достигло 10 лет и продолжает расти. Поскольку объемы данных все увеличиваются, требования к хранилищу и обработке баз и сервера также растут. Это может повлечь за собой значительные затраты. В качестве альтернативы некоторые устаревшие данные перемещают из хранилища в кластер Hadoop. В хранилище, таким образом, остаются только последние данные, скажем за три года, которые часто используются и должны быть доступны для быстрого анализа и представления, а старые или редко используемые данные хранятся в Hadoop. Большинство баз данных уровня предприятия имеют соответствующие функции для прямого подключения хранилищ к Hadoop, позволяя специалисту запрашивать на языке SQL любые данные, как если бы они все находились в одной среде. Такой запрос открывает доступ и к хранилищу данных, и к Hadoop. Обработка запроса автоматически разделяет его на две отдельные части, каждая из которых выполняется независимо, а результаты объединяются и интегрируются, прежде чем будут представлены специалисту по данным.
Анализ данных затрагивает и ту и другую части слоя хранения, представленного на рис. 6. Он может выполняться как на основе данных, взятых непосредственно из BI-систем или Hadoop, так и на результатах их анализа, повторенного множество раз. Часто данные из традиционных источников бывают заметно чище и плотнее полученных из источников больших данных. Тем не менее гигантский объем и режим реального времени, свойственные большим данным, означают, что усилия, приложенные для подготовки и анализа их источников, могут окупиться с точки зрения важной информации, недоступной из традиционных источников. Разнообразные методы анализа данных для тех или иных областей исследования (включая обработку естественного языка, компьютерное зрение и машинное обучение), используются для преобразования неструктурированных больших данных низкой плотности в ценные данные высокой плотности. Такие данные уже могут быть интегрированы с другими ценными данными из традиционных источников для дальнейшего анализа. Описанная структура, проиллюстрированная на рис. 3.1, представляет собой типичную архитектуру экосистемы науки о данных. Она подойдет для большинства организаций независимо от размера, однако по мере масштабирования организации увеличивается и сложность экосистемы науки о данных. Например, для небольших организаций может и не требоваться компонент Hadoop, но для крупных он становится незаменим.
Читать дальшеИнтервал:
Закладка:








