Джон Келлехер - Наука о данных. Базовый курс

- Название:Наука о данных. Базовый курс
- Автор:
- Жанр:
- Издательство:Альпина Паблишер
- Год:2020
- Город:Москва
- ISBN:978-5-9614-3378-4
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Джон Келлехер - Наука о данных. Базовый курс краткое содержание
Книга знакомит с основами науки о данных. В ней охватываются все ключевые аспекты, начиная с истории развития сбора и анализа данных и заканчивая этическими проблемами, связанными с конфиденциальностью информации. Авторы объясняют, как работают нейронные сети и машинное обучение, приводят примеры анализа бизнес-проблем и того, как их можно решить, рассказывают о сферах, на которые наука о данных окажет наибольшее влияние в будущем.
«Наука о данных» уже переведена на японский, корейский и китайский языки.
Наука о данных. Базовый курс - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Перемещение алгоритмов в данные
Традиционный подход к анализу данных включает их извлечение из различных баз, интеграцию, очистку, размещение, построение прогнозной модели, а затем загрузку окончательных результатов анализа в базу данных, чтобы их можно было использовать как часть рабочего процесса, отображать в виде отчетности и т. д. На рис. 7 показано, что большая часть процесса обработки данных, включающего их подготовку и анализ, протекает на отдельном сервере, вне баз и хранилища. При этом значительное количество времени может быть затрачено только на перемещение данных из базы и загрузку в нее результатов.
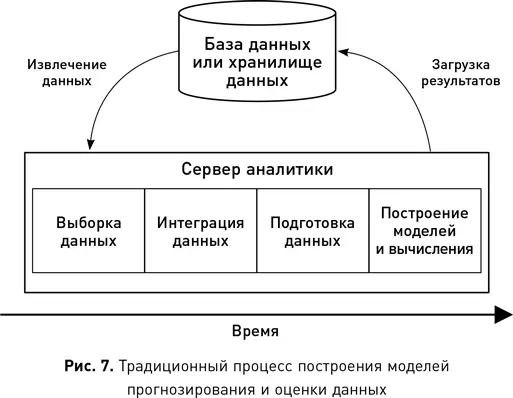
Для примера: в эксперименте по построению модели линейной регрессии около 70–80 % времени ушло на извлечение и подготовку данных. На создание моделей было потрачено лишь оставшееся время. В процессе скоринга данных примерно 90 % времени было затрачено на их извлечение и сохранение готового набора обратно в базу. Только 10 % времени пришлось на сам скоринг. Эти результаты основаны на наборах данных от 50 000 до 1,5 млн записей. Большинство поставщиков корпоративных баз данных уже осознали, сколько времени экономится, если отказаться от их перемещения, и отреагировали на это включением функции анализа и алгоритмов машинного обучения непосредственно в механизмы базы данных. В последующих разделах мы рассмотрим, каким образом алгоритмы машинного обучения были интегрированы в современные базы данных, как хранятся большие данные в Hadoop и как комбинации этих двух подходов позволяют легко работать со всеми данными в организации, используя SQL как общий язык доступа, анализа, машинного обучения и прогнозной аналитики в режиме реального времени.

Поставщики баз данных постоянно инвестируют в развитие масштабируемости, производительности, безопасности и функциональности своих продуктов. Современные базы данных намного более продвинуты, чем традиционные реляционные базы данных. Они могут хранить и запрашивать данные в различных форматах. Кроме реляционных форматов, можно определять типы объектов, хранить документы, хранить и запрашивать объекты JSON, геоданные и т. д. Помимо этого, большинство современных баз имеют массу статистических функций, а некоторые поставляются с основными статистическими приложениями. Например, база данных Oracle поставляется с более чем 300 различными встроенными статистическими функциями. Они охватывают бо́льшую часть статистического анализа, необходимого для проектов науки о данных, и включают практически все статистические функции, доступные в других инструментах и языках, таких как R. Изучение функционала баз данных организации может позволить аналитику действовать более эффективно и масштабируемо, используя язык SQL. Кроме того, большинство поставщиков баз данных (включая Oracle, Microsoft, IBM и EnterpriseDB) интегрировали в свои базы разнообразные алгоритмы машинного обучения, которые можно запускать на SQL. Использование алгоритмов машинного обучения, встроенных в ядро базы и доступных через SQL, известно как машинное обучение в базе данных . Такое машинное обучение способствует более быстрой разработке моделей и скорейшей интеграции результатов анализа с приложениями и панелями мониторинга. Кратко идея размещения алгоритмов машинного обучения непосредственно в базах данных может быть выражена следующим образом: «Переместить алгоритмы в данные, вместо того чтобы перемещать данные в алгоритмы».
Использование алгоритмов машинного обучения в базе данных имеет следующие преимущества:
• Отсутствие движения данных.Некоторые продукты для обработки данных требуют их экспорта из базы и конвертации в особый формат, чтобы поместить в алгоритм машинного обучения. Благодаря машинному обучению в базе данных перемещение или преобразование данных не требуется. Это упрощает весь процесс, делает его менее трудоемким и подверженным ошибкам.
• Скорость.Для аналитических операций, выполняемых в базе данных без их перемещения, можно использовать вычислительные возможности сервера самой базы, обеспечивая увеличение производительности до 100 раз по сравнению с традиционным подходом. Большинство серверов баз данных имеют высокие спецификации, множество процессоров и эффективное управление памятью для обработки наборов данных, содержащих более миллиарда записей.
• Высокая безопасность.База данных обеспечивает контролируемый и поддающийся проверке доступ к данным, увеличивая производительность специалиста и поддерживая нормы безопасности. Кроме того, машинное обучение в базе данных позволяет избежать рисков, присущих процессу извлечения и загрузки данных на альтернативные серверы. К тому же традиционный процесс обработки данных приводит к созданию множества копий (а иногда и разных версий) наборов данных в разных хранилищах организации.
• Масштабируемость.База данных может легко масштабировать аналитику по мере увеличения объема данных благодаря алгоритмам машинного обучения. Программное обеспечение баз предназначено для эффективного управления большими объемами данных с использованием нескольких серверных процессоров и памяти, что позволяет выполнять алгоритмы машинного обучения параллельно другим задачам. Базы данных также очень эффективны при обработке больших наборов данных, которые не помещаются в память. Сорокалетняя история развития баз гарантирует, что наборы данных будут обработаны быстро.
• Режим реального времени.Модели, разработанные с использованием алгоритмов машинного обучения в базе данных, могут быть немедленно развернуты и использованы в средах реального времени. Это позволяет интегрировать модели в привычные приложения и предоставлять прогнозы конечным пользователям и клиентам.
• Развертывание в среде эксплуатации.SQL — это язык базы данных, который может быть использован для доступа к алгоритмам и моделям машинного обучения в базах. Модели, разработанные с использованием автономного ПО для машинного обучения, возможно, придется перекодировать на другие языки программирования, прежде чем они смогут быть развернуты в корпоративных приложениях. Но это не относится к машинному обучению в базе данных. SQL можно использовать и вызывать любым языком программирования и инструментом науки о данных. Это значительно упрощает задачу включения модели из базы данных в производственные приложения.
Читать дальшеИнтервал:
Закладка:








