Джон Келлехер - Наука о данных. Базовый курс

- Название:Наука о данных. Базовый курс
- Автор:
- Жанр:
- Издательство:Альпина Паблишер
- Год:2020
- Город:Москва
- ISBN:978-5-9614-3378-4
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Джон Келлехер - Наука о данных. Базовый курс краткое содержание
Книга знакомит с основами науки о данных. В ней охватываются все ключевые аспекты, начиная с истории развития сбора и анализа данных и заканчивая этическими проблемами, связанными с конфиденциальностью информации. Авторы объясняют, как работают нейронные сети и машинное обучение, приводят примеры анализа бизнес-проблем и того, как их можно решить, рассказывают о сферах, на которые наука о данных окажет наибольшее влияние в будущем.
«Наука о данных» уже переведена на японский, корейский и китайский языки.
Наука о данных. Базовый курс - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Многие организации используют преимущества машинного обучения в базе данных. Среди них встречаются как небольшие компании, так и крупные. Вот примеры организаций, использующих эту технологию:
• Fiserv — американский поставщик финансовых услуг, который занимается выявлением и анализом мошенничества. Он перешел от работы с несколькими поставщиками технологий хранения данных и машинного обучения к использованию машинного обучения в своей базе данных. В частности, эта технология позволяет сократить время создания/обновления и развертывания модели обнаружения мошенничества с почти недели до нескольких часов.
• Компания 84.51° (формально Dunnhumby, USA) использовала множество различных аналитических решений при создании моделей для своих клиентов. Обычно каждый месяц более 318 часов уходило на перемещение данных из базы на сервера машинного обучения и обратно. При этом на создание моделей тратилось еще как минимум 67 часов. Компания внедрила алгоритмы машинного обучения непосредственно в базу данных. Как только данные перестали покидать базу, экономия времени сразу составила более 318 часов. Поскольку база данных использовалась в качестве вычислительного инструмента, специалисты смогли масштабировать аналитику и время создания или обновления моделей машинного обучения сократилось с 67+ часов до 1 часа. Это дало экономию 16 дней. Теперь они могут получать результаты значительно быстрее и начинать взаимодействие с клиентами намного раньше, вскоре после совершения ими покупки.
• Wargaming — создатели World of Tanks и многих других игр — использует машинное обучение в базе данных, чтобы моделировать и прогнозировать взаимодействие с более чем 120 млн своих клиентов.
Хотя современная база данных невероятно эффективна для обработки транзакций, в эпоху больших данных для управления разнообразными формами данных и их долгосрочного хранения требуется новая инфраструктура. Современная база данных может справляться с объемами до нескольких петабайт, но при таком масштабе традиционные решения для баз могут стать чрезмерно дорогими. Этот вопрос стоимости обычно упирается в вертикальное масштабирование. В традиционной парадигме чем больше данных должна хранить и обрабатывать организация в течение необходимого срока, тем больший ей требуется сервер, а это увеличивает стоимость его конфигурации и лицензирования баз данных. Традиционная технология позволяет запрашивать и принимать миллиард записей ежедневно, но такой масштаб обработки обойдется в несколько миллионов долларов.
Hadoop — это платформа с открытым исходным кодом, которая была разработана и выпущена Apache Software Foundation. Она хорошо зарекомендовала себя для эффективного приема и хранения больших объемов данных и обходится дешевле, чем традиционный подход. Кроме того, на рынке появился широкий ассортимент продуктов для обработки и анализа данных на платформе Hadoop. Приведенное выше высказывание, касающееся современных баз данных — «переместить алгоритмы в данные, вместо того чтобы перемещать данные в алгоритмы», — также применимо и к Hadoop.
В Hadoop данные делятся на разделы, которые распределяются по узлам кластера. В процессе работы с Hadoop различные аналитические инструменты обрабатывают данные в каждом из кластеров (часть этих данных может постоянно находиться в оперативной памяти), что обеспечивает быструю обработку данных, поскольку несколько кластеров анализируются одновременно. Ни извлечение данных, ни ETL-процесс не требуются. Данные анализируются там, где они хранятся. Существуют и другие примеры аналогичного подхода, скажем решения от Google и Amazon, где аналитическое программное обеспечение, такое как Spark, разворачивается на распределенных вычислительных архитектурах, позволяя анализировать данные там, где они находятся.
В мире больших данных специалист может запрашивать их массивные наборы с использованием аналитических языков, таких как Spark, Flink, Storm, и широкого спектра инструментов, а также постоянно растущего числа бесплатных и коммерческих продуктов. Эти продукты представляют собой инструменты высокоуровневой аналитики или панели мониторинга, которые упрощают работу специалиста с данными и аналитикой, что позволяет ему сконцентрироваться на анализе данных. Однако современному специалисту по данным приходится анализировать их в двух разных местах: в современных базах данных и в хранилищах больших данных на Hadoop. В следующей части мы рассмотрим, как решается эта проблема.
Если у организации нет данных такого размера и масштаба, которым требуется Hadoop, то для управления данными ей будет достаточно традиционной базы данных. Однако есть мнение, что инструменты хранения и обработки данных, доступные в мире Hadoop, в итоге вытеснят традиционные базы данных. Такое сложно себе представить, и потому в последнее время обсуждается более сбалансированный подход к управлению данными в так называемом мире гибридных баз, где традиционные базы данных сосуществуют с Hadoop.

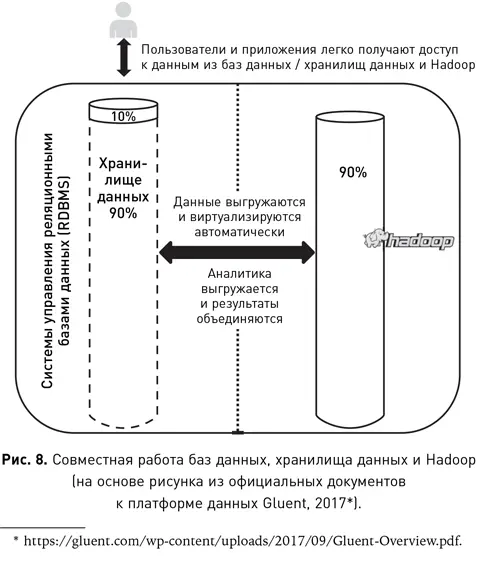
В мире гибридных баз все данные связаны между собой и работают вместе, что позволяет эффективно обмениваться ими, обрабатывать и анализировать их. На рис. 8 показано традиционное хранилище данных, но при этом большая часть данных находится не в базе или хранилище, а перемещена в Hadoop. Между базой данных и Hadoop создается соединение, которое позволяет специалисту запрашивать данные, как если бы они находились в одном месте. Ему не потребуется запрашивать отдельно данные из базы и из Hadoop. Гибридная база автоматически определит, какие части запроса необходимо выполнить в каждом из местоположений, затем объединит результаты и представит их специалисту. Точно так же по мере роста хранилища часть данных устаревает, и гибридное решение автоматически перемещает редко используемые данные в среду Hadoop, а те, что становятся востребованными, наоборот, возвращает обратно. Гибридная база данных сама определяет местоположение данных на основе частоты запросов и типа проводимого анализа.
Одним из преимуществ гибридных решений является то, что специалист по-прежнему запрашивает данные на SQL. Ему не нужно изучать другой язык запросов или применять особые инструменты. Сегодняшние тенденции позволяют предположить, что в ближайшем будущем основные поставщики баз данных, облачных хранилищ и программного обеспечения для интеграции данных будут предлагать именно гибридные решения.
Подготовка и интеграция данных
Интервал:
Закладка:








