Джон Келлехер - Наука о данных. Базовый курс

- Название:Наука о данных. Базовый курс
- Автор:
- Жанр:
- Издательство:Альпина Паблишер
- Год:2020
- Город:Москва
- ISBN:978-5-9614-3378-4
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Джон Келлехер - Наука о данных. Базовый курс краткое содержание
Книга знакомит с основами науки о данных. В ней охватываются все ключевые аспекты, начиная с истории развития сбора и анализа данных и заканчивая этическими проблемами, связанными с конфиденциальностью информации. Авторы объясняют, как работают нейронные сети и машинное обучение, приводят примеры анализа бизнес-проблем и того, как их можно решить, рассказывают о сферах, на которые наука о данных окажет наибольшее влияние в будущем.
«Наука о данных» уже переведена на японский, корейский и китайский языки.
Наука о данных. Базовый курс - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
1. Рассчитайте ошибку для каждого из нейронов в выходном слое и обновите согласно правилу веса входящих связей этих нейронов.
2. Поделитесь ошибкой, рассчитанной для нейрона, с каждым из нейронов в предыдущем слое, который связан с ним, пропорционально весу связей между двумя нейронами.
3. Для каждого нейрона на предыдущем уровне вычислите общую ошибку сети, за которую он ответственен, суммируя с теми ошибками, которые были переданы обратно в него, и используйте результат этого суммирования, чтобы обновить веса на связях, входящих в этот нейрон.
4. Пройдите таким же образом остальные слои в сети, повторяя шаги 2 и 3 до тех пор, пока веса между входными нейронами и первым слоем скрытых нейронов не будут обновлены.
При обратном распространении ошибки вес, обновляемый для каждого нейрона, высчитывается так, чтобы уменьшить, но не устранить полностью ошибку нейрона в обучающем экземпляре. Причина этого заключается в том, что цель обучения сети — дать ей возможность сделать выводы, которых нет в данных обучения, а не просто запомнить эти данные. Таким образом, каждое обновление весов продвигает сеть к такому их набору, который лучше всего подходит к набору данных, и на протяжении многих итераций сеть постепенно сужает значения весов в наборе, которые учитывают общее распределение данных больше, чем характеристики обучающих объектов. В некоторых версиях обратного распространения ошибки веса обновляются только после того, как несколько объектов (или пакет объектов) были представлены сети, а не после ввода каждого обучающего объекта. Единственная настройка, необходимая для этого, заключается в том, чтобы алгоритм использовал среднюю ошибку сети для этих объектов в качестве меры ошибки на выходе для процесса обновления веса.
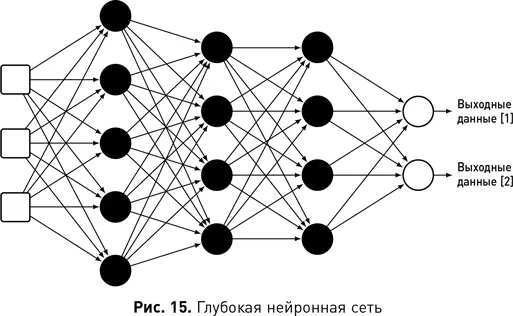
Одним из наиболее удивительных технических достижений последних 10 лет стало появление глубокого обучения. Сети глубокого обучения — это те же нейронные сети, имеющие несколько [19]слоев скрытых юнитов, — другими словами, они глубоки с точки зрения количества скрытых слоев. Нейронная сеть на рис. 15 имеет пять слоев: один входной, три скрытых (черные кружки) и один выходной слой справа, содержащий два нейрона. Эта сеть иллюстрирует то, что в каждом слое может быть разное количество нейронов: входной слой содержит три нейрона, первый скрытый слой — пять, следующие два скрытых слоя — четыре, а выходной слой — два. На примере этой сети видно и то, что выходной слой также может иметь несколько нейронов. Использование нескольких выходных нейронов полезно, если целью является номинальный или порядковый тип данных, имеющий разные уровни. В подобных сценариях сеть настраивают таким образом, чтобы для каждого уровня существовал один выходной нейрон, и обучают ее так, чтобы для каждого входа только один из выходных нейронов выводил высокую активацию (означающую прогнозируемый целевой уровень).
Подобно предыдущим сетям, которые мы рассматривали, это также полностью подключенная сеть с прямой связью. Однако не все сети являются таковыми. Было разработано множество типов сетевых топологий. Например, рекуррентные нейронные сети (РНС) вводят в сетевую топологию петли: выходное значение нейрона возвращается на один из входов в процессе обработки следующего набора входных значений. Этот цикл дает сети память, которая позволяет ей обрабатывать каждый вход в контексте предыдущих, уже обработанных ею раньше. Следовательно, РНС подходят для обработки последовательных данных, таких как естественный язык [20]. Другой популярной архитектурой глубоких нейронных сетей являются сверхточные нейронные сети (СНС). СНС были первоначально разработаны для использования с данными изображений {1} . Сеть распознавания изображений должна обнаруживать на изображении визуальный признак независимо от того, в какой части изображения он встречается. Например, если сеть выполняет распознавание лиц, она должна уметь распознавать форму глаза, где бы он ни находился — в верхнем правом углу или в центре изображения. СНС достигают этого за счет групп нейронов, которые имеют одинаковый набор весов на своих входах. В этом контексте набор входных весов определяет функцию, которая возвращает истинное значение, если в наборе поступающих в нее пикселей появляется определенный визуальный признак. Это означает, что каждая группа нейронов с одинаковыми весами учится идентифицировать определенный визуальный признак и каждый нейрон в группе действует как детектор этого признака. В СНС нейроны в каждой группе расположены так, чтобы каждый исследовал свой фрагмент изображения, а вместе группа охватывала бы его целиком. Таким образом, если заданный визуальный признак присутствует на изображении, один из нейронов в группе идентифицирует его.
Сила глубоких нейронных сетей в том, что они могут автоматически изучать полезные атрибуты, такие как детекторы признаков в СНС. Глубокое обучение иногда так и называют — «обучение признакам», поскольку глубокие сети по сути изучают новое представление входных данных, которое лучше подходит для прогнозирования целевого выходного атрибута, чем исходный необработанный ввод. Каждый нейрон в сети определяет функцию, которая отображает значения в новый входной атрибут. Поэтому нейрон в первом слое сети может изучать функцию, которая преобразует необработанные входные значения (например, вес и рост) в более полезный атрибут (например, ИМТ). Однако выход этого нейрона наравне с его сестринскими нейронами в первом слое подается в нейроны второго слоя, изучающие функции, которые преобразуют выходные данные первого слоя в новые и еще более полезные представления. Этот процесс сопоставления входных данных с новыми атрибутами и передачи этих новых атрибутов в качестве входных данных для следующих функций распространяется по сети, и по мере того, как сеть становится глубже, она может изучать все более и более сложные сопоставления. Именно способность автоматически изучать сложные сопоставления входных данных с полезными атрибутами делает модели глубокого обучения настолько точными при выполнении задач с многомерным вводом (таких, как обработка изображений и текста).
Давно известно, что чем глубже нейронная сеть, тем более сложные отображения данных она способна изучать. Однако развитие глубокое обучение получило лишь в последние несколько лет, и причина этого заключается в том, что стандартная комбинация случайного веса с последующим алгоритмом обратного распространения ошибки не очень хорошо работала с глубокими сетями. Во-первых, ошибка в этом случае распределяется по мере того, как процесс возвращается со слоя на слой, так что к тому времени, когда алгоритм достигает ранних слоев глубокой сети, оценки ошибок уже не так полезны [21]. В результате слои в ранних частях сети не учатся полезным преобразованиям данных. Однако в последние годы были разработаны новые типы нейронов и адаптации к алгоритму обратного распространения, которые помогают решить эту проблему. Также было обнаружено, что требуется осторожная инициализация весов сети. Два других фактора, которые усложняли обучение глубоких сетей, заключались в том, что для обучения нейронной сети требуется большая вычислительная мощность и к тому же нейронные сети показывают максимальную эффективность на большом количестве обучающих данных. В последние годы большие вычислительные мощности стали доступнее, и это сделало обучение глубоких сетей осуществимым.
Читать дальшеИнтервал:
Закладка:








