Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/1150039/roman-zykov-roman-s-data-science-kak-monetizirova.webp "Обложка книги")
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Жанр:
- Издательство:Издательство Питер
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres] краткое содержание
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
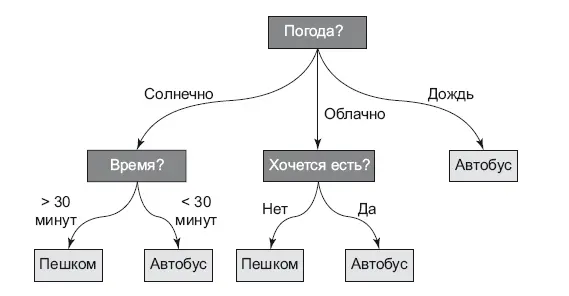
Рис. 8.7.Дерево решений
Для этого вначале выбирается фича. Разделив датасет по ее значению (для непрерывных подбираются пороги), мы получаем наибольшее уменьшение энтропии Шеннона (или наибольший информационный выигрыш). Для этого на каждом шаге происходит полный перебор всех фич и их значений. Этот процесс повторяется много раз, пока мы не достигнем ситуации, когда уже делить нечего, в выборке данных остались только наблюдения одного класса – это и будет листом. Часто это грозит переобучением – полученное дерево слишком сильно подстроилось под выборку, запомнив все данные в листьях. На практике при построении деревьев решений у них ограничивают глубину и максимальное число элементов в листьях. А если ничего не помогает, то проводят «обрезку» дерева (pruning или postpruning). Обрезка идет от листьев к корню. Решение принимается на основе проверки: насколько ухудшится качество дерева, если объединить эти два листа. Для этого используется отдельный небольшой датасет, который не участвовал в обучении [55].
Ошибки обучения
Модель в процессе обучения, если она правильно выбрана, пытается найти закономерности (patterns) и обобщить (generalize) их. Показатели эффективности позволяют сравнивать разные модели или подходы к их обучению путем простого сравнения. Согласитесь, что если у вас будут две модели, ошибка прогнозирования первой равна 15 %, а второй 10 %, то сразу понятно, что следует предпочесть вторую модель. А что будет, если при тестировании в модель попадут данные, которых не было в обучающем датасете? Если при обучении мы получили хорошее качество обобщения модели, то все будет в порядке, ошибка будет небольшой, а если нет, то ошибка может быть очень большой.
Итогом обучения модели могут быть два типа ошибок:
• модель не заметила закономерности (high bias, underfitting – недообучена);
• модель сделала слишком сложную интерпретацию, например, там, где мы видим линейную зависимость, модель увидела квадратичную (high variance, overfitting – переобучена).
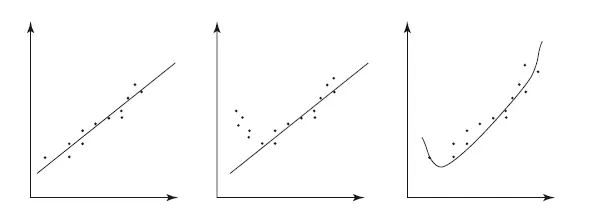
Рис. 8.8.Правильное обучение, недообучение, переобучение
Попробую это продемонстрировать. На картинке (рис. 8.8) изображены результаты экспериментов в виде точек (вспомните лабы по физике в школе). Мы должны найти закономерности – построить линии, их описывающие. На первой картинке все хорошо: прямая линия хорошо описывает данные, расстояния от точек до самой линии небольшие. Модель правильно определила закономерность. На второй – явно у нас зависимость нелинейная, например квадратичная. Значит, линия, проведенная по точкам, неправильная. Мы получили недообученную модель (underfitting), ошиблись порядком функции. На третьей картинке ситуация наоборот, модель выбрана слишком сложной для линейной зависимости, которая наблюдается по точкам. Выбросы данных исказили ее. Здесь налицо переобучение, нужно было выбрать модель попроще – линейную.
Я нарисовал относительно искусственную ситуацию – одна независимая переменная на горизонтальной оси и одна зависимая переменная на вертикальной оси. В таких простых условиях мы можем прямо на графике увидеть проблему. Но что будет, если у нас много независимых переменных, например десяток? Тут на помощь приходит подход для тестирования модели – валидация.
Она служит как раз для понимания таких ошибок, когда мы работаем с моделью как с черным ящиком. Самый простой подход – делим случайно датасет на две части: большую часть используем для обучения модели, меньшую – для ее тестирования. Обычно соотношение 80 к 20. Фокус здесь в том, что настоящая ошибка, когда модель выведем в бой, будет близка к ошибке, которую мы получим на тестовом датасете. Есть еще один вариант валидации, когда данные делятся не на две, а на три части: на первой части – обучается модель, на второй – происходит подбор гиперпараметров модели (настройки модели), на третьей уже получают тестовую оценку. Эндрю Ын в своей книге «Machine learning Yearning» [60] считает эту модель валидации основной. Теперь обсудим сам алгоритм диагностики. Допустим, у нас есть две цифры – среднеквадратичные ошибки для обучающего датасета и тестового. Теперь сравним их:
• Тестовые и обучающие ошибки практически совпадают, сама ошибка минимальна и вас устраивает. Поздравляю, модель обучена правильно, ее можно выводить в бой.
• Тестовая ошибка существенно больше обучающей. При этом обучающая ошибка вас устраивает. Налицо переобучение – модель получилась слишком сложной для данных.
• Обучающая ошибка получилась высокой. Возникла ситуация недообучения. Либо выбранная модель слишком простая для этих данных, либо не хватает самих данных (объема или каких-то фич).
Более сложная версия валидации – k-fold cross validation (k-кратная перекрестная проверка). Ее активно применяют в серьезной работе, научных исследованиях и соревнованиях. Она заключается в случайном разделении датасета на k равных частей, например на 8 частей. Затем извлекаем первую часть из датасета, тренируем модель на оставшихся, считаем ошибки на обучающих данных и извлеченных данных (тестовая ошибка). Эту последовательность повторяем для всех частей. На выходе получаем k ошибок, которые можно усреднить. И делаем аналогичные сравнения, как описано выше.
Как бороться с переобучением
Для борьбы с переобучением есть несколько простых рецептов, которые применяются на практике. Во-первых, можно попытаться найти больше данных – привет, Капитан Очевидность! Это очень наивный совет, ведь обычно работают уже с максимально полным датасетом.
Второй способ – удалить выбросы в данных. Это можно сделать через анализ распределений: описательные статистики, гистограммы, графики «ящики и усы», диаграммы рассеяния будут полезны.
Третий вариант – удалить часть фич (независимых переменных). Это работает особенно хорошо для линейных методов, которые очень чувствительны к мультиколлинеарности фич. Мультиколлинеарность означает, что часть фич зависимы друг от друга. Природа этой зависимости может быть натуральной и искусственной. Естественная зависимость – число покупок и количество потраченных денег. Искусственная зависимость – когда аналитик добавил в датасет новые фичи как функцию от уже существующих. Например, возвел значение одной из них в квадрат, при этом старая фича осталась в датасете. В реальной работе эти ситуации встречаются сплошь и рядом.
Одним из негативных эффектов этого явления в линейных методах является резкое изменение коэффициентов, когда в модель добавляется новая, зависимая от уже включенных в нее фич. Например, аналитик использует линейную регрессию, чтобы понять, сделает ли покупатель еще одну покупку или нет. В модели у него уже была фича – число сделанных покупок, допустим, ее коэффициент равен 0.6. Следующим шагом он добавляет в модель объем средств, потраченных на совершенные покупки. Коэффициент этой фичи будет 0.5, при этом коэффициент числа покупок становится отрицательным: –0.1. Очень странная ситуация – понятно, что чем больше покупок клиент совершил в прошлом, тем больше вероятность, что он продолжит покупать. А тут мы видим, что число покупок влияет негативно. Это произошло из-за того, что корреляция (зависимость) между числом покупок и потраченными деньгами очень высокая и деньги оттянули на себя этот эффект. Сами коэффициенты могут быть важными, если вы пытаетесь понять причины какой-либо ситуации. С мультиколлинеарностью можно прийти к неверным выводам. Интересно, что у статистического анализа и машинного обучения разные цели. Для статистического анализа коэффициенты модели важны – они объясняют природу явления. Для машинного обучения важны не так, главное – достичь хорошей метрики, а как – не имеет значения.
Читать дальшеИнтервал:
Закладка:









