Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/1150039/roman-zykov-roman-s-data-science-kak-monetizirova.webp "Обложка книги")
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Жанр:
- Издательство:Издательство Питер
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres] краткое содержание
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Итак, у нас есть два параметра для сегментации – Recency (далее R) и Frequency (далее F), оба эти параметра могут прогнозировать дальнейшее поведение клиента c определенной точностью. И если объединить их в один параметр RF – то точность прогноза повышается в разы. Далее я приведу последовательность шагов (по методике Джима Ново):
• Параметр R – бьется на пять частей, и появляются пять значений от 1 до 5. 5 – это когда заказ был сделан совсем недавно.
• Параметр F – бьется на пять частей, и появляются пять значений от 1 до 5. 5 – это когда клиент в течение определенного периода времени (этот период тоже нужно рассчитать) сделал очень много заказов.
• Строится RF-сетка (grid): в виде двузначной комбинации R и F. 55 – сегмент лучших клиентов, 11 – самых худших клиентов.
• Вычисляются вероятность совершения следующего действия для каждого сегмента.
• 25 RF сегментов объединяются по вероятностям (из прошлого шага) в большие сегменты.
С точки зрения RFM, самый лучший клиент – это тот (рис. 9.3), который совершил покупку совсем недавно, до этого сделал их много на хорошую сумму денег. Этот фундаментальный принцип помог создавать фичи, которые предсказывают вероятность совершения действий в дальнейшем. Его можно распространить на любые действия людей, кроме покупок: вероятность заболеть, вероятность вернуться на сайт, вероятность попасть в тюрьму, вероятность кликнуть на баннер. Всего лишь с помощью этих переменных и простой линейной модели на одном из конкурсов Kaggle я смог получить очень неплохой результат. Для лучших результатов, кроме действительных цифр, я использовал бинарное кодирование. За базу можно взять сегментацию, о которой я написал выше. Можно брать отдельно переменные R и F или целиком RF.
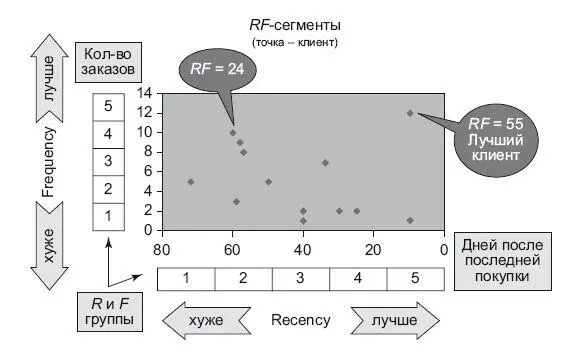
Рис. 9.3.RF-сегментация
Последний совет
Кроме каких-либо теоретических книг в качестве дополнительных источников знаний рекомендую два бесплатных ресурса: книгу Эндрю Ына [60] про практику машинного обучения и правила Google для инженерии ML-проектов [72]. Они помогут в дальнейшем совершенствовании.
Глава 10
Внедрение ML в жизнь: гипотезы и эксперименты

Все эксперименты проводятся для того, чтобы дать фактам возможность опровергнуть нулевую гипотезу.
Сэр Рональд Фишер, «Планирование экспериментов» (1935)Модели ML рождаются, живут и умирают. Жизнь меняется, это закон природы: если что-то долго не меняется, то оно умирает. Улучшая и оптимизируя модель, мы даем ей новую жизнь и надежду. Помочь нам в этом могут гипотезы (или идеи) и эксперименты, подтверждающие или отвергающие гипотезы. В 2016 году на сцене концертного зала MIT я рассказывал про то, как убивать гипотезы как можно раньше. Доклад зашел на ура, поэтому я решил изложить те идеи и выводы в этой главе.
Гипотезы
Гипотеза – это идея по улучшению продукта. Неважно, что это – сайт, товар или магазин. Существует даже должность менеджера по продукту, одной из задач которого является создание и поддержание списка таких гипотез, расстановка приоритетов их исполнения. Список гипотез еще называют бэклогом (backlog). Он является важным стратегическим элементом развития компании. Как придумывать гипотезы и расставлять их в порядке приоритетов – тема отдельной большой книги. Если кратко, идеальная ситуация выглядит так – продуктологи взаимодействуют с рынком, с существующими и потенциальными клиентами, изучают конкурентные решения, проводят фокус-группы, чтобы понять, сколько то или иное изменение (гипотеза) принесет компании денег. На основе этих исследований гипотезы попадают в список и приоретизируются. Бизнес требует денежных метрик для приоритезации гипотез, чем точнее они подсчитаны, тем лучше. Но в реальности с большинством гипотез сделать это очень сложно, и оценка происходит по принципу «пальцем в небо». Самые громкие коммерческие успехи в истории были революционными, а не эволюционными – вспомните хотя бы появление первого iPhone.
Приоритизация гипотез служит главной цели – как можно быстрее достичь успеха. Если следовать этой логике, идеи, которые с большей вероятностью могут дать результат, должны быть первыми в списке на реализацию. Но у каждой гипотезы есть такая характеристика, как сложность ее реализации, – вот почему, приоритизируя гипотезы, важно оценивать их трудоемкость и стоимость инфраструктуры (сервера, наем дополнительного персонала). Допустим, первая гипотеза обещает принести примерно 10 млн рублей за год, при этом затраты на ее реализацию – это месяц работы двух разработчиков и одного аналитика данных. Вторая обещает 2 млн рублей за год, при этом реализовать ее смогут два человека за пять дней работы. Какую гипотезу выбрать первой? Это решение я оставляю за менеджментом, однозначного совета дать здесь не могу.
Что если гипотезы и их приоритизацию делать внутри отделов? С одной стороны, этот подход кажется правильным – минимум централизации, максимум скорости. Но давайте представим себе, что компания – это живой организм, а ее самый сильный отдел (например, IT) – это руки. У отдела хороший список гипотез, и приоритеты расставлены более правильно, чем у других отделов, – то есть руки прокачаны как следует. А теперь представим себе соревнования по триатлону – на олимпийской дистанции нужно проплыть 1500 метров, сразу после этого сесть на велосипед и проехать 40 км, а затем пробежать 10 км. Сильные руки пригодятся на первом этапе, но в двух других дисциплинах нужны уже сильные ноги. Если они не так хорошо натренированы, спортсмен проиграет гонку более сбалансированным соперникам или даже может сойти с дистанции. В бизнесе, как в спорте, невозможно сделать ставку на один отдел – нужен сбалансированный подход. Я сам проходил это в Retail Rocket – варился в собственном соку, приоритизировал свои гипотезы сам. Да, мы стали очень сильными в одной области, но остальные команды не успевали за нами. Если вернуться назад, я бы сделал ставку на совместную работу, продукт и рынок.
Все гипотезы из списка невозможно протестировать. Большинству уготовано так и остаться навеки гипотезами. Это нормально и даже хорошо – значит, более выгодные идеи реализуются раньше остальных. Каждая гипотеза потребляет ресурсы, они не бесконечны, поэтому невозможно протестировать все идеи. Скажу больше – 9 из 10 гипотез не принесут результата. Но понятно это может стать только на одном из многочисленных этапов ее тестирования. Моя теория заключается в том, что нужно убивать гипотезу как можно раньше, как только мы получим первый сигнал о том, что она не взлетит. Это сэкономит ресурсы – много ресурсов! – и даст шанс лучшим гипотезам, которые ожидают своей очереди.
Читать дальшеИнтервал:
Закладка:









