Роб Кёртен - Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform

- Название:Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform
- Автор:
- Жанр:
- Издательство:Петрополис
- Год:2001
- Город:Санкт-Петербург
- ISBN:5-94656-025-9
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Роб Кёртен - Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform краткое содержание
Книга "Введение в QNX/Neutrino 2» откроет перед вами в мельчайших подробностях все секреты ОСРВ нового поколения от компании QNX Software Systems Ltd (QSSL) — QNX/Neutrino 2. Книга написана в непринужденной манере, легким для чтения и понимания стилем, и поможет любому, от начинающих программистов до опытных системотехников, получить необходимые начальные знания для проектирования надежных систем реального времени, от встраиваемых управляющих приложений до распределенных сетевых вычислительных систем
В книге подробно описаны основные составляющие ОС QNX/Neutrino и их взаимосвязи. В частности, уделено особое внимание следующим темам:
• обмен сообщениями: принципы функционирования и основы применения;
• процессы и потоки: базовые концепции, предостережения и рекомендации;
• таймеры: организация периодических событий в программах;
• администраторы ресурсов: все, что относится к программированию драйверов устройств;
• прерывания: рекомендации по эффективной обработке.
В книге представлено множество проверенных примеров кода, подробных разъяснений и рисунков, которые помогут вам детально вникнуть в и излагаемый материал. Примеры кода и обновления к ним также можно найти на веб-сайте автора данной книги, www.parse.com.
Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
В случае с барьером, мы ждем «встречи» определенного числа потоков у барьера. Затем, когда заданное число потоков достигнуто, мы их всех разблокируем (заметьте, что потоки при этом продолжат выполнять свою работу).
Сначала барьер следует создать при помощи функции barrier_init() :
#include
int barrier_init(barrier_t *barrier, const barrier_attr_t *attr, int count);
Эта функция создает объект типа «барьер» по переданному ей адресу (указатель на барьер хранится в параметре barrier) и назначает ему атрибуты, которые определены в attr (мы будем использовать NULL, чтобы установить значения по умолчанию). Число потоков, которые должны вызывать функцию barrier_wait() , передается в параметре count .
После того как барьер создан, каждый из потоков должен будет вызвать функцию barrier_wait() , чтобы сообщить, что он отработал:
#include
int barrier_wait(barrier_t *barrier);
После того как поток вызвал barrier_wait() , он будет блокирован до тех пор, пока число потоков, указанное первоначально в параметре count функции barrier_init() , не вызовет функцию barrier_wait() (они также будут блокированы). После того как нужное число потоков выполнит вызов функции barrier_wait() , все эти потоки будут разблокированы «одновременно».
Вот пример:
/*
* barrier1.c
*/
#include
#include
#include
#include
barrier_t barrier; // Объект типа «барьер»
void* thread1(void *not_used) {
time_t now;
char buf[27];
time(&now);
printf("Поток 1, время старта %s", ctime_r(&now, buf));
// Выполнить вычисления
// (вместо этого просто сделаем sleep)
sleep(20);
barrier_wait(&barrier);
// После этого момента все потоки уже завершатся
time(&now);
printf("Барьер в потоке 1, время срабатывания %s",
ctime_r(&now, buf));
}
void* thread2(void *not_used) {
time_t now;
char buf[27];
time(&now);
printf("Поток 2, время старта %s", ctime_r(&now, buf));
// Выполнить вычисления
// (вместо этого просто сделаем sleep)
sleep(40);
barrier_wait(&barrier);
// После этого момента все потоки уже завершатся
time(&now);
printf("Барьер в потоке 2, время срабатывания %s",
ctime_r(&now, buf));
}
main() // Игнорировать аргументы
{
time_t now;
char buf[27];
// Создать барьер со значением счетчика 3
barrier_init(&barrier, NULL, 3);
// Создать два потока, thread1 и thread2
pthread_create(NULL, NULL, thread1, NULL);
pthread_create(NULL, NULL, thread2, NULL);
// Сейчас выполняются оба потока
// Ждать завершения
time(&now);
printf("main(): ожидание у барьера, время %s",
ctime_r(&now, buf));
barrier_wait(&barrier);
// После этого момента все потоки уже завершатся
time(&now);
printf("Барьер в main(), время срабатывания %s",
ctime_r(&now, buf));
}
Основной поток создал объект типа «барьер» и инициализировал его значением счетчика, равным числу потоков (включая себя!), которые должны «встретиться» у барьера, прежде чем он «прорвется». В нашем примере этот индекс был равен 3 — один для потока main() , один для потока thread1() и один для потока thread2() . Затем, как и прежде, стартуют потоки вычисления графики (в нашем случае это потоки thread1() и thread2() ). Для примера вместо приведения реальных алгоритмов графических вычислений мы просто временно «усыпили» потоки, указав в них sleep(20) и sleep(40) , чтобы имитировать вычисления. Для осуществления синхронизации основной поток ( main() ) просто блокирует сам себя на барьере, зная, что барьер будет разблокирован только после того, как рабочие потоки аналогично присоединятся к нему.
Как упоминалось ранее, с функцией pthread_join() рабочие потоки для синхронизации главного потока с ними должны умереть. В случае же с барьером потоки живут и чувствуют себя вполне хорошо. Фактически, отработав, они просто разблокируются по функции barrier_wait() . Тонкость здесь в том, что вы обязаны предусмотреть, что эти потоки должны делать дальше! В нашем примере с графикой мы не дали им никакого задания для них — просто потому что мы так придумали алгоритм. В реальной жизни вы могли бы захотеть, например, продолжить вычисления.
Предположим, что мы слегка изменили наш пример так, чтобы можно было проиллюстрировать, почему иногда хорошо иметь несколько потоков даже в системе с одиночным процессором.
В таком модифицированном примере один узел на сети ответственен за вычисление строк растра (как и в примере с графикой, рассмотренном выше). Однако, когда строка рассчитана, ее данные должны быть отправлены по сети другому узлу, который выполняет функцию отображения. Ниже приведена соответствующая модифицированная функция main() (на основе первоначального примера без потоков):
int main(int argc, char **argv) {
int x1;
... // выполнить инициализации
for (x1 = 0; x1 < num_x_lines; x1++) {
do _one_line(x1); // Область «С» на схеме
tx_one_line_wait_ack(x1); // Области «X» и «W» на схеме
}
}
Обратите внимание на то, что мы исключили отображающую часть программы и вместо этого добавили функцию tx_one_line_wait_ack() . Далее предположим, что мы имеем дело с достаточно медленной сетью, но процессор в действительности не занимается передачей данных — он просто отдает их некоторым аппаратным средствам, которые уже сами позаботятся об их передаче. Функция tx_one_line_wait_ack() потребует немного процессорного времени на то, чтобы обеспечить передачу данных аппаратным средствам, и после этого, пока не получит подтверждения о получении данных от удаленного узла, не будет потреблять процессорное время вообще.
Ниже представлена диаграмма, иллюстрирующая загрузку процессора в данном случае (графические вычисления на ней обозначены как «С», передача — как «X», а ожидание подтверждения — как «W»).
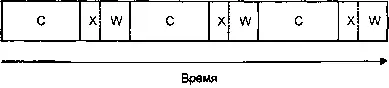
Последовательное выполнение, один процессор.
Минуточку! Мы тратим впустую драгоценные секунды, ожидая, пока аппаратура сделает свое дело!
Если мы сделали бы это в многопоточном варианте, мы смогли бы добиться более эффективного использования процессора, так?
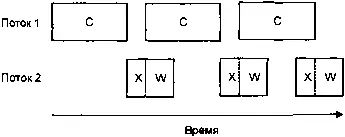
Многопоточное выполнение, один процессор
Это уже намного лучше, потому что теперь, даже при том, второй поток затрачивает немного времени на ожидание, мы добились уменьшения суммарного времени вычислений.
Читать дальшеИнтервал:
Закладка:






