Роб Кёртен - Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform

- Название:Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform
- Автор:
- Жанр:
- Издательство:Петрополис
- Год:2001
- Город:Санкт-Петербург
- ISBN:5-94656-025-9
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Роб Кёртен - Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform краткое содержание
Книга "Введение в QNX/Neutrino 2» откроет перед вами в мельчайших подробностях все секреты ОСРВ нового поколения от компании QNX Software Systems Ltd (QSSL) — QNX/Neutrino 2. Книга написана в непринужденной манере, легким для чтения и понимания стилем, и поможет любому, от начинающих программистов до опытных системотехников, получить необходимые начальные знания для проектирования надежных систем реального времени, от встраиваемых управляющих приложений до распределенных сетевых вычислительных систем
В книге подробно описаны основные составляющие ОС QNX/Neutrino и их взаимосвязи. В частности, уделено особое внимание следующим темам:
• обмен сообщениями: принципы функционирования и основы применения;
• процессы и потоки: базовые концепции, предостережения и рекомендации;
• таймеры: организация периодических событий в программах;
• администраторы ресурсов: все, что относится к программированию драйверов устройств;
• прерывания: рекомендации по эффективной обработке.
В книге представлено множество проверенных примеров кода, подробных разъяснений и рисунков, которые помогут вам детально вникнуть в и излагаемый материал. Примеры кода и обновления к ним также можно найти на веб-сайте автора данной книги, www.parse.com.
Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Если бы в нашем примере тратилось T computeединиц времени на вычисления, T tx — на передачу и T wait— на ожидание аппарату средств, тогда для первого случая в нашем примере общие затраты времени на обработку были бы равны:
(T compute+ T tx+ T wait) ∙ num_x_lines ,
тогда как затраты времени при использовании двух потоков были бы равны:
(T compute+ T tx) ∙ num_x_lines + T wait,
что меньше на величину:
T wait∙ ( num_x_lines – 1),
в предположении, конечно, что T wait≤ T compute.
 Отметим, что мы изначально будем ограничены интервалом времени, равным:
Отметим, что мы изначально будем ограничены интервалом времени, равным:
T compute+ T tx∙ num_x_lines ,
потому что мы должны будем завершить по меньшей мере одно полное вычисление, а также еще и передать данные. Иными словами, мы можем использовать многопоточность для распараллеливания вычислений, но аппаратный ресурс для передачи данных у нас все равно есть только один.
А если бы мы разработали вариант системы с четырьмя потоками и выполнили это в SMP-системе с четырьмя процессорами, это выглядело бы примерно так:
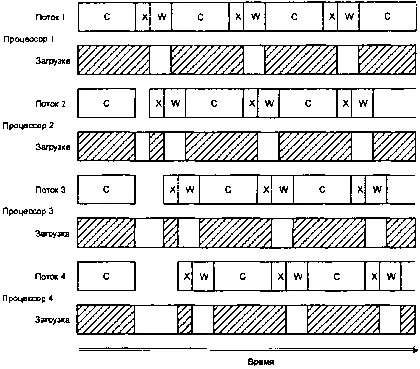
Четыре потока, четыре процессора.
Обратите внимание, насколько каждый из этих четырех центральных процессоров недоиспользован (см. незаштрихованные прямоугольники в строках «Загрузка»). На представленном выше рисунке имеются две интересные зоны. Когда все четыре потока стартуют одновременно, все они вычисляются. К сожалению, когда потоки заканчивают вычисления, они начинают конкурировать за право обладания аппаратными средствами передачи данных (зоны «X» на диаграмме смещены одна относительно другой, поскольку, имея только один передающий ресурс, можно вести только одну передачу одновременно). Это дает нам небольшую аномалию на начальном этапе. После того как потоки отработали этот этап, они оказываются естественным образом синхронизированы по отношению к работе аппаратных средств, так как время передачи данных намного меньше, чем ¼ времени вычислительного цикла. Если игнорировать эту небольшую аномалию в работе системы на начальном этапе, значения временных интервалов в данной системе можно оценить по формуле:
(T compute+ T tx+ T wait) ∙ num_x_lines / num_cpus
Из этой формулы следует, что применение четырех потоков на четырех процессорах обеспечивает сокращение затрат времени приблизительно в 4 раза по сравнению с аналогичным временем в модели с единственным потоком, т.е. по сравнению с данным! примера, с которого мы начали обсуждение этой проблемы.
Суммируя все то, что мы узнали из анализа примера с использованием многопоточного варианта с одиночным процессором, в идеале мы желали бы иметь больше потоков, чем процессоров, чтобы дополнительные потоки могли «подобрать» время простоя процессоров, которое естественным образом возникает из интервалов ожидания подтверждения (а также из интервалов ожидания, связанных с конкуренцией за передатчик) В этом случае у нас бы получилось примерно вот что: (см. рис. «Восемь потоков, четыре процессора»).

Восемь потоков, четыре процессора.
На этом рисунке предполагается следующее:
• потоки 5, 6, 7 и 8 привязаны к процессорам 1, 2, 3, и 4 (для упрощения);
• передача данных выполняется с более высоким приоритетов чем вычислительные операции;
• прервать передачу нельзя.
Из диаграммы видно, что хоть мы теперь и имеем в два раза больше потоков, чем процессоров, мы по-прежнему сталкиваемся с временными интервалами, в течение которых процессоры «недоиспользованы». На рисунке показаны три таких интервала времени. Эти интервалы обозначены числами, соответствующими номеру процессора, и указаны на временных диаграммах загрузки процессоров в строках «Загрузка»:
1. Поток 1 ожидает подтверждения (состояние «W»), при этом поток 5 завершил вычисления и ждет доступности передатчика.
2. Потоки 2 и 6 ожидают подтверждения.
3. Поток 3 ожидает подтверждения, при этом поток 7 завершил вычисления и ждет доступности передатчика.
Этот пример для нас — важный урок. Бессмысленно просто увеличивать количество процессоров в надежде, что все ваши дела пойдут быстрее, поскольку имеются также и ограничивающие факторы. В некоторых случаях эти ограничивающие факторы определяются просто конструкцией материнской платы мультипроцессорной системы, то есть структурой подсистемы разрешения конфликтов за устройства в память, когда несколько процессоров пытаются обратиться по одному и тому же адресу. В нашем случае обратите внимание, что строка «Использование порта передачи данных» стала все больше заполняться. Если бы мы просто увеличили число процессоров, то в конечном счете столкнулись бы с проблемами, связанными с тем, что соответствующие потоки простаивали бы в ожидании передатчика.
В любом случае, используя потоки-«мусорщики» для сбора неиспользованных ресурсов процессоров, мы сможем обеспечить намного более эффективное использование процессоров. Это время приближенно оценивается по формуле:
(T compute+ T tx+ T wait) ∙ num_x_lines / num_cpus
При выполнении только вычислений мы ограничены только количеством процессоров; ни один процессор не будет простаивать в ожидании подтверждения. Впрочем, это был бы идеальный случай. Как вы видели из диаграммы, реально периодически возникают временные интервалы, когда один процессор простаивает. Также, как отмечалось ранее, мы в любом случае ограничены по скорости значением:
T compute+ T tx∙ num_x_lines .
При том, что в общем случае вы можете запросто «игнорировать», работаете вы с SMP-архитектурой или с одиночным процессором, есть ряд обстоятельств, которые определенно добавят вам головной боли. К сожалению, это могут быть такие маловероятные события, которые могут проявиться не на этапе разработки, а на этапе его испытаний, в демонстрационных версиях или даже, что самое неприятное, на стадии эксплуатации. Так вот, следование ряду принципов «защитного программирования» избавит вас от связанной с этими проблемами нервотрепки.
Вот краткий перечень того, что следует четко помнить, имея дело с SMP-системой:
• Потоки действительно могут работать и работают параллельно — ни в коем случае не доверяйте при их синхронизации таким механизмам как диспетчеризация FIFO или система приоритетов.
• Потоки могут также выполняться одновременно с обработчиками прерываний (ISR) — это означает, что вам нужно будет не только защитить поток от обработчика прерываний, но и наоборот — обработчик прерываний от потока. Подробнее об этом см. в главе 4, «Прерывания».
Читать дальшеИнтервал:
Закладка:






