Роб Кёртен - Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform

- Название:Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform
- Автор:
- Жанр:
- Издательство:Петрополис
- Год:2001
- Город:Санкт-Петербург
- ISBN:5-94656-025-9
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Роб Кёртен - Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform краткое содержание
Книга "Введение в QNX/Neutrino 2» откроет перед вами в мельчайших подробностях все секреты ОСРВ нового поколения от компании QNX Software Systems Ltd (QSSL) — QNX/Neutrino 2. Книга написана в непринужденной манере, легким для чтения и понимания стилем, и поможет любому, от начинающих программистов до опытных системотехников, получить необходимые начальные знания для проектирования надежных систем реального времени, от встраиваемых управляющих приложений до распределенных сетевых вычислительных систем
В книге подробно описаны основные составляющие ОС QNX/Neutrino и их взаимосвязи. В частности, уделено особое внимание следующим темам:
• обмен сообщениями: принципы функционирования и основы применения;
• процессы и потоки: базовые концепции, предостережения и рекомендации;
• таймеры: организация периодических событий в программах;
• администраторы ресурсов: все, что относится к программированию драйверов устройств;
• прерывания: рекомендации по эффективной обработке.
В книге представлено множество проверенных примеров кода, подробных разъяснений и рисунков, которые помогут вам детально вникнуть в и излагаемый материал. Примеры кода и обновления к ним также можно найти на веб-сайте автора данной книги, www.parse.com.
Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
• Некоторые операции, которые по вашему мнению должны быть атомарными, в действительности таковыми не являются — это зависит от операции и от процессора. Отметим из такого списка операции типа «чтение- модификация-запись» (например, ++ , -- , &= , т.д.). См. файл для анализа возможных замен. (Заметьте, что это не проблема SMP в чистом виде; код для вышеупомянутых операции может выполняться не как атомарный на большинстве RISC-процессоров).
Ранее в разделе «Где хороша многопоточность» говорилось о том, что потокам также находят применение там, где имеет место обработка информации по множеству независимых алгоритмов с разделяемыми структурами данных. При этом, строго говоря, вы могли бы использовать несколько процессов (с одним потоком каждый), явно разделяющих данные, но в некоторых случаях вместо этого гораздо удобнее использовать один многопоточный процесс. Давайте рассмотрим, почему и где здесь можно использовать потоки.
В наших примерах будем отталкиваться от стандартной модели «ввод-обработка-вывод». В наиболее общем случае одна часть этой модели ответственна за получение откуда-либо входных данных, другая часть — за обработку этих данных и преобразование их в некоторые выходные данные (или управляющие воздействия), третья часть — за отправку полученных выходных данных куда надо.
Давайте, во-первых, осмыслим, что мы будем иметь в случае нескольких однопоточных процессов. Для нашей модели у нас было бы три процесса — процесс «ввода», процесс «обработки» и процесс «вывода»:

Система 1: Несколько операций, несколько процессов.
В таком виде наша модель в высшей степени абстрактна, но и в такой же степени «слабо связана». Процесс «ввода» не имеет никакой реальной связи ни с процессом «обработки», ни с процессом «вывода» — он просто отвечает за сбор входных данных и передачу их как-нибудь на следующий этап («этап обработки»).
Мы могли бы сказать то же самое о процессах «обработки» и «вывода» — они также не имеют никакой реальной связи друг с другом. Также здесь предполагается, что обмен данными («ввод — обработка» и «обработка — вывод») осуществляется по некоторому стандартному протоколу (например, через программные каналы, очереди сообщений POSIX, обмен сообщениями QNX/Neutrino — что угодно).
В зависимости от объема потока данных, мы можем пожелать оптимизировать характер связей. Самый простой путь состоит в том, чтобы связать три процесса «теснее». Попробуем теперь вместо использования универсального протокола соединения выбрать схему с разделяемой памятью (на диаграмме толстые стрелки указывают потоки данных; тонкие стрелки — потоки управления):

Система 2: Несколько операций, буферы разделяемой памяти между процессами.
В данной схеме мы « подтянули » связь так, чтобы в результате обеспечить более быстрый и более эффективный обмен данными. В то же время, мы здесь по-прежнему можем применять универсальный протокол для передачи «управляющей» информации, поскольку предполагается, что по сравнению с потоком данных ее не так много.
Система с наиболее тесными связями представлена на следующей схеме:
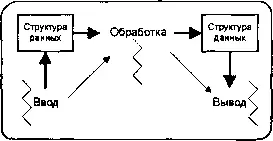
Система 3: Несколько операций, несколько потоков.
Здесь мы наблюдаем один процесс с тремя потоками. Все три потока неявно разделяют области данных. Обмен управляющей информацией может быть реализован аналогично предыдущим примерам или с помощью ряда примитивов синхронизации потоков (мы уже имели дело с мутексами, барьерами и семафорами — скоро рассмотрим и другие).
Давайте теперь сравним эти три метода по ряду критериев и взвесим все «за» и «против».
В системе 1 связь была самой слабой. Это имеет то преимущество, что каждый из трех процессов может быть легко (то есть при помощи командной строки, в противоположность перекомпиляции/переработке) заменен другим модулем. Это следует из самой природы модели, потому что «единицей модульности» здесь является сам функциональный модуль. Система 1 является также единственной, которая из всех трех может быть распределена по узлам сети QNX/Neutrino. Поскольку информационные связи здесь абстрагированы до некоторого универсального протокола, очевидно, что эти три процесса могут быть выполнены на любой машине в сети. Это может быть очень мощным фактором масштабируемости в Вашем проекте — вам может понадобиться расширить свою сеть до сотен узлов, либо разделенных географически, либо как-то иначе — например, для совместимости с другими аппаратными средствами.
Однако, как только мы переходим к применению разделяемой памяти, мы теряем способность распределять модули по сети. QNX/Neutrino не поддерживает распределенные объекты разделяемой памяти. Таким образом, в Системе 2 мы реально ограничили себя выполнением всех трех процессов на одной и той же машине. Мы не потеряли способность легкой замены или исключения модулей, потому что модули все еще представляют собой отдельные процессы, управляемые командной строкой. Но мы добавили ограничение, в соответствии с которым все заменяемые компоненты должны соответствовать модели с разделяемой памятью.
В системе 3 мы теряем все отмеченные ранее проектные возможности. Мы определенно не можем выполнять различные потоки одного процесса на различных узлах (хотя при этом мы можем выполнять их на различных процессорах в SMP-системе). Также мы потеряли наши возможности переконфигурации — теперь нам обязательно понадобится механизм явного доопределения, который из алгоритмов «ввода», «обработки» и «вывода» мы должны использовать (эту проблему можно решить с помощью разделяемых объектов, также известных как динамические библиотеки — DLL).
Так почему же я должен проектировать свою систему, используя многопоточность, как в Системе 3? Почему бы мне для обеспечения максимальной универсальности не выбрать Систему 1?
Ну, даже при том, что Система 3 является наиболее ригидной, она, скорее всего, окажется самой быстродействующей. В ней не будет переключений контекста между потоками в различных процессах, мне не придется настраивать разделяемую память, а также применять абстрактные методы синхронизации типа программных каналов, очередей сообщений POSIX или обмен сообщениями QNX/Neutrino для обеспечения доставки данных или управляющей информации — я смогу использовать базовые примитивы синхронизации потоков на уровне ядра. Другим преимуществом является то, что при запуске системы, состоящей из одного процесса (с тремя потоками), я могу быть уверен, что все, что мне понадобится далее, уже загружено с носителя (то есть потом не выяснится что-то типа «Опа! А нужного-то драйвера на диске и нету...») И, наконец, Система 3 также, скорее всего, будет наиболее компактной, потому что не придется использовать три отдельных копии информации, характерной для процессов (например, дескрипторы файлов).
Читать дальшеИнтервал:
Закладка:






