А. Цветкова - Информатика и информационные технологии: конспект лекций

- Название:Информатика и информационные технологии: конспект лекций
- Автор:
- Жанр:
- Издательство:Конспекты, шпаргалки, учебники «ЭКСМО»b4455b31-6e46-102c-b0cc-edc40df1930e
- Год:2007
- Город:Москва
- ISBN:978-5-699-23180-5
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
А. Цветкова - Информатика и информационные технологии: конспект лекций краткое содержание
Конспект лекций соответствует требованиям Государственного образовательного стандарта высшего профессионального образования РФ и предназначен для освоения студентами вузов специальной дисциплины «Информатика и информационные технологии». Лаконичное и четкое изложение материала, продуманный отбор необходимых тем позволяют быстро и качественно подготовиться к семинарам, зачетам и экзаменам по данному предмету.
Информатика и информационные технологии: конспект лекций - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
5) STACK – определение сегмента стека. Заставляет компоновщик соединить все одноименные сегменты и вычислять адреса в этих сегментах относительно регистра ss. Комбинированный тип STACK (стек) аналогичен комбинированному типу PUBLIC, за исключением того, что регистр ss является стандартным сегментным регистром для сегментов стека. Регистр sp устанавливается на конец объединенного сегмента стека. Если не указано ни одного сегмента стека, компоновщик выдаст предупреждение, что стековый сегмент не найден. Если сегмент стека создан, а комбинированный тип STACK не используется, программист должен явно загрузить в регистр ss адрес сегмента (подобно тому, как это делается для регистра ds).
По умолчанию атрибут комбинирования принимает значение PRIVATE.
3. Атрибут класса сегмента (тип класса) – это заключенная в кавычки строка, помогающая компоновщику определить соответствующий порядок следования сегментов при собирании программы из сегментов нескольких модулей. Компоновщик объединяет вместе в памяти все сегменты с одним и тем же именем класса (имя класса в общем случае может быть любым, но лучше, если оно будет отражать функциональное назначение сегмента). Типичным примером использования имени класса является объединение в группу всех сегментов кода программы (обычно для этого используется класс «code»). С помощью механизма типизации класса можно группировать также сегменты инициализированных и неинициализированных данных.
4. Атрибут размера сегмента. Для процессоров i80386 и выше сегменты могут быть 16– или 32-разрядными. Это влияет прежде всего на размер сегмента и порядок формирования физического адреса внутри него. Атрибут может принимать следующие значения:
1) USE16 – это означает, что сегмент допускает 16-разрядную адресацию. При формировании физического адреса может использоваться только 16-разрядное смещение. Соответственно, такой сегмент может содержать до 64 Кбайт кода или данных;
2)USE32 – сегмент будет 32-разрядным. При формировании физического адреса может использоваться 32-разрядное смещение. Поэтому такой сегмент может содержать до 4 Гбайт кода или данных.
Все сегменты сами по себе равноправны, так как директивы SEGMENT и ENDS не содержат информации о функциональном назначении сегментов. Для того чтобы использовать их как сегменты кода, данных или стека, необходимо предварительно сообщить транслятору об этом, для чего используют специальную директиву ASSUME, имеющую формат, показанный на рис. 18. Эта директива сообщает транслятору о том, какой сегмент к какому сегментному регистру привязан. В свою очередь, это позволит транслятору корректно связывать символические имена, определенные в сегментах. Привязка сегментов к сегментным регистрам осуществляется с помощью операндов этой директивы, в которых имя_сегмента должно быть именем сегмента, определенным в исходном тексте программы директивой SEGMENT или ключевым словом nothing. Если в качестве операнда используется только ключевое слово nothing, то предшествующие назначения сегментных регистров аннулируются, причем сразу для всех шести сегментных регистров. Но ключевое слово nothing можно использовать вместо аргумента имя сегмента; в этом случае будет выборочно разрываться связь между сегментом с именем имя сегмента и соответствующим сегментным регистром (см. рис. 18).
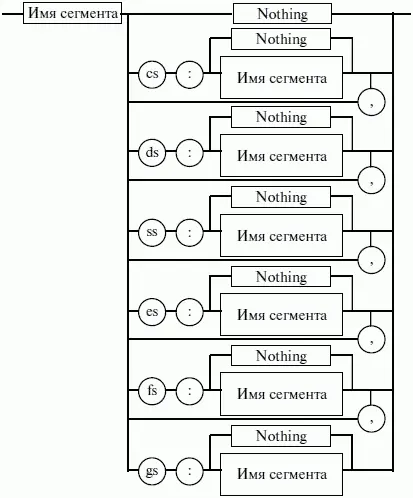
Рис. 18. Директива ASSUME
Для простых программ, содержащих по одному сегменту для кода, данных и стека, хотелось бы упростить ее описание. Для этого в трансляторы MASM и TASM ввели возможность использования упрощенных директив сегментации. Но здесь возникла проблема, связанная с тем, что необходимо было как-то компенсировать невозможность напрямую управлять размещением и комбинированием сегментов. Для этого совместно с упрощенными директивами сегментации стали использовать директиву указания модели памяти MODEL, которая частично стала управлять размещением сегментов и выполнять функции директивы ASSUME (поэтому при использовании упрощенных директив сегментации директиву ASSUME можно не использовать). Эта директива связывает сегменты, которые в случае использования упрощенных директив сегментации имеют предопределенные имена, с сегментными регистрами (хотя явно инициализировать ds все равно придется).
Синтаксис директивы MODEL показан на рисунке 19.
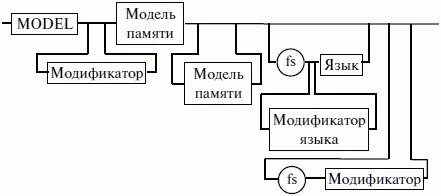
Рис. 19. Синтаксис директивы MODEL
Обязательным параметром директивы MODEL является модель памяти. Этот параметр определяет модель сегментации памяти для программного модуля. Предполагается, что программный модуль может иметь только определенные типы сегментов, которые определяются упомянутыми нами ранее упрощенными директивами описания сегментов. Эти директивы приведены в таблице 5.
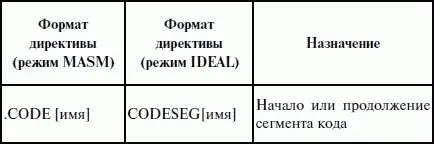
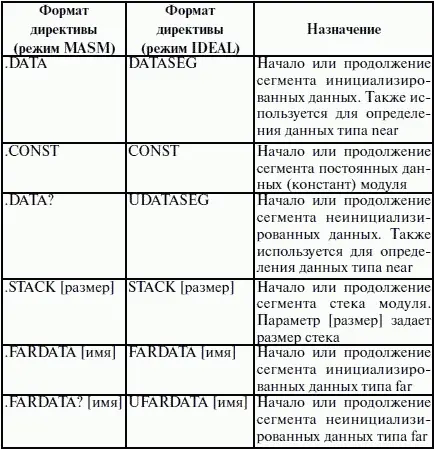
Наличие в некоторых директивах параметра [имя] говорит о том, что возможно определение нескольких сегментов этого типа. С другой стороны, наличие нескольких видов сегментов данных обусловлено требованием обеспечить совместимость с некоторыми компиляторами языков высокого уровня, которые создают разные сегменты данных для инициализированных и неинициализированных данных, а также констант.
При использовании директивы MODEL транслятор делает доступными несколько идентификаторов, к которым можно обращаться во время работы программы, с тем, чтобы получить информацию о тех или иных характеристиках данной модели памяти (табл. 7). Перечислим эти идентификаторы и их значения (табл. 6).
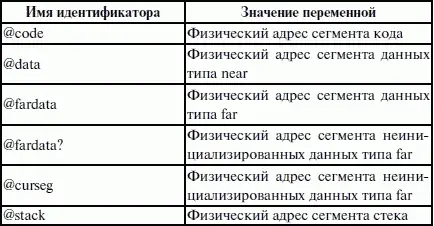
Теперь можно закончить обсуждение директивы MODEL. Операнды директивы MODEL используют для задания модели памяти, которая определяет набор сегментов программы, размеры сегментов данных и кода, способ связывания сегментов и сегментных регистров. В таблице 7 приведены некоторые значения параметра «модель памяти» директивы MODEL.
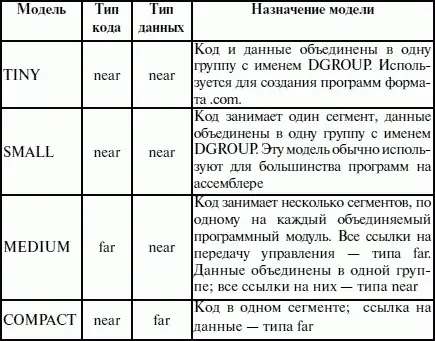
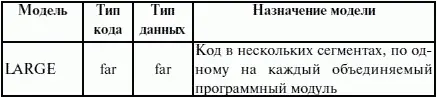
Параметр «модификатор» директивы MODEL позволяет уточнить некоторые особенности использования выбранной модели памяти (табл. 8).
Читать дальшеИнтервал:
Закладка:








