Алексей Валиков - Технология XSLT

- Название:Технология XSLT
- Автор:
- Жанр:
- Издательство:БХВ-Петербург
- Год:2002
- Город:Санкт-Петербург
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Алексей Валиков - Технология XSLT краткое содержание
Книга посвящена разработке приложений для преобразования XML-документов с использованием XSLT — расширяемого языка стилей для преобразований. Обсуждается применение языков XSLT и XPath в решении практических задач: выводу документов в формате HTML, использованию различных кодировок для интернационализации и, в частности, русификации приложений, вопросам эффективности существующих подходов для решения проблем преобразования. Для иллюстрации материала используется большое количество примеров.
Для начинающих и профессиональных программистов
Технология XSLT - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
создаст текстовый узел, значение которого будет равно текстовому значению элемента text. В первом случае выражение "text"являлось строкой, литералом, во втором — путем выборки.
Определенную сложность создает одновременное использование в литералах двойных и одинарных кавычек — некоторые процессоры будут воспринимать их как окончание значения атрибута. Такие строки проще всего будет задавать при помощи переменных, например:
'An author of "One Flew Over Cookoo's Nest"'
Следует особым образом отметить, что в XSLT, как XML-языке, символы могут быть заменены сущностями. Например, вместо символа " "" (двойные кавычки) можно использовать сущность ", а вместо символа " '" (одинарные кавычки) — '. Это позволяет использовать внутри атрибутов такие конструкции, как
'this is a string'
что эквивалентно
'this is a string'
На практике следует избегать таких приемов — они сильно запутывают текст программы. Сущности следует использовать только тогда, когда это действительно необходимо.
Строки можно сравнивать при помощи операторов " =" (равно) или " !=" (не равно). При сравнении строки проверяются на посимвольное совпадение. Различные процессоры могут по-разному реализовывать процедуру сравнения, например, рассматривать разные символы с одним начертанием как одинаковые, но в одном можно быть точно уверенными — в случае, если на одних и тех же местах будут стоять символы с одинаковыми Unicode-кодами, строки будут равны.
'not' = 'noх74;'→ true
Не следует также забывать, что один символ в строке — это необязательно один байт. Более того, это необязательно некое фиксированное число байт, ведь модель символов Unicode позволяет использовать для записи символа коды переменной длины.
Строка может быть приведена к булевому и численному типу.
В булевом представлении пустой строке соответствует false, непустой — true. Содержимое непустой строки при этом никакой роли не играет. Булевое значение строки " false" будет "истиной", равно, как и булевое значение строки " true".
'То be' or 'not to be'→ true
'Full' and ''→ false
'true' and 'false'→ true
При приведении к численным значениям строки разбираются как числа в десятичном формате. Если строка не является представлением числа, ее численным значением будет NaN. В свою очередь, результатом любых вычислений, в которых участвует NaN, будет также NaN.
'2' * '2'→ 4
'one' + 'two'→ NaN
'2/3' + '5/6'→ NaN
'2' div '3' + '5' div '6'→ 1.5
При работе с численными значениями можно использовать следующие операторы:
□ -, унарный оператор, который выполняет отрицание своего единственного операнда — эта операция равносильна вычитанию числа из нуля;
□ +, бинарный оператор сложения, возвращает сумму своих операндов;
□ -, бинарный оператор вычитания, возвращает разность своих операндов;
□ *, бинарный оператор умножения, возвращает произведение своих операндов;
□ div, бинарный оператор деления, возвращает частное от деления первого операнда на второй;
□ mod, бинарный оператор, возвращающий остаток от деления первого операнда на второй.
Обратим внимание на то, что оператор divв отличие от его трактовки в языке Pascal, выполняет нецелое деление. Результатом вычисления выражения 3 div 2будет 1.5, а не 1.
Динамическая типизация в XSLT позволяет использовать в выражениях значения разных типов — например, складывать строки и булевые значения или производить логические операции над числами. В тех случаях, когда тип данных значения отличается от типа данных, который требуется для операции, значения будут неявным образом приведены к требуемому типу, если это, конечно, возможно.
Множество узлов (node-set)
Несмотря на то, что XSLT оперирует логической моделью XML-документа как деревом с узлами, в XSLT нет типа данных, который соответствовал бы одному узлу. Вместо этого используется гораздо более мощный и гибкий тип данных, называемый множеством узлов (англ. node-set).
Множество узлов — это чистое математическое множество, состоящее из узлов дерева: оно не содержит повторений и не имеет внутреннего порядка элементов. Множества узлов выбираются особым видом XPath-выражений, которые называются путями выборки (англ. location path).
<���А>
<���В/>
<���С>
Предположим, что в этом документе мы хотим выбрать все узлы, являющиеся потомками элемента C, который находился бы в элементе A, который находится в корне документа. Соответствующее XPath-выражение будет записано в виде /A/C//node().
Для наглядности представим наш документ в виде дерева (рис. 3.12) и выделим в нем соответствующее множество узлов.
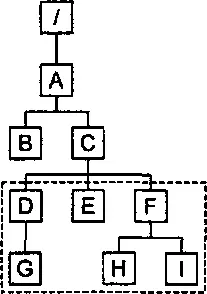
Рис. 3.12. Выбор множества узлов
Выбранное множество состоит из узлов элементов D, G, E, F, H, I (рис. 3.13):

Рис. 3.13. Выбранное множество
Выбор множества не означает "клонирования", создания копий узлов, которые в него входят. Это просто выбор из всех узлов входящего документа некоторого набора, удовлетворяющего критериям, заданным путем выборки. С точки зрения программиста, множество узлов может быть представлено, как неупорядоченный список ссылок на узлы. При этом практическая реализация зависит от разработчиков конкретного процессора.
В общем случае, во множество узлов не входят дети узлов, содержащихся в нем. В нашем примере узлы элементов G, Hи Iвошли в выбранное множество только потому, что они соответствовали пути выборки /A/C//node(). Если бы путь выборки имел вид /A/C/node()(то есть, выбрать всех детей узла C, содержащегося в узле A, находящемся в корне документа), результат (рис. 3.14) был бы иным.

Рис. 3.14. Другой путь выборки
Выбранное множество узлов имело бы вид (рис. 3.15):

Рис. 3.15. Выбранное множество
Для представления одного узла дерева в XSLT используется множество, состоящее из единственного узла. В предыдущем примере результатом выборки /A(выбрать узел A, находящийся в корне документа) было бы множество, состоящее из единственного узла (рис. 3.16).
Интервал:
Закладка:

