Алексей Валиков - Технология XSLT

- Название:Технология XSLT
- Автор:
- Жанр:
- Издательство:БХВ-Петербург
- Год:2002
- Город:Санкт-Петербург
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Алексей Валиков - Технология XSLT краткое содержание
Книга посвящена разработке приложений для преобразования XML-документов с использованием XSLT — расширяемого языка стилей для преобразований. Обсуждается применение языков XSLT и XPath в решении практических задач: выводу документов в формате HTML, использованию различных кодировок для интернационализации и, в частности, русификации приложений, вопросам эффективности существующих подходов для решения проблем преобразования. Для иллюстрации материала используется большое количество примеров.
Для начинающих и профессиональных программистов
Технология XSLT - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:

Рис. 3.16. Множество, состоящее из единственного узла
Несмотря на то, что множества узлов неупорядочены, во многих случаях обработка узлов множества производится в порядке просмотра документа. Некоторые элементы, обрабатывающие множества (такие, как xsl:apply-templatesи xsl:for-each) позволяют предварительно выполнять их сортировку при помощи элемента xsl:sort.
Множества узлов можно сравнивать при помощи операторов " =" (равно) и " !=" (не равно). В отличие от равенства математических множеств, равенство множеств узлов Aи Bв XSLT означает то, что найдется узел a , принадлежащий множеству Aи узел b , принадлежащий множеству Bтакие, что их строковые значения будут равны. Неравенство множеств означает наличие в них как минимум пары узлов с различными строковыми представлениями. Такие определения делают возможным при сравнении двух множеств одновременное выполнение равенства и неравенства.
1
2
2
3
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
and
Результатом этого преобразования будет строка:
true and true
Этот пример показывает, что множество дочерних элементов intэлемента numbersодновременно считает как равным, так и неравным множеству дочерних элементов byte.
Приведем еще несколько примеров.
1
2
3
4
Результат:
false and true
1
1
1
Результат:
true and false
С математической точки зрения операции сравнения множеств определены в XSLT, мягко говоря, странно. Например, единственный случай, когда для двух множеств не будет выполняться неравенство (" !=") — это когда все узлы обоих множеств будут иметь одинаковое строковое представление. Вместе с тем, операции сравнения множеств очень часто используются в качестве условий и потому нужно хорошо понимать различия между ними и математическими операциями сравнения.
XSLT определяет единственную операцию над множествами — операцию объединения " |". Выражение " $A | $B" возвратит множество узлов, присутствующих либо в $A, либо в $B, либо и там, и там.
В XSLT нет встроенного оператора, который позволил бы установить принадлежность узла некоторому множеству. Для этой цели используется очень хитроумный прием, основанный на использовании функции count, которая возвращает количество узлов множества. Представим, что множество $nodeсодержит некоторый узел, и мы хотим проверить, входит ли он во множество $nodeset. Сделать это можно при помощи выражения
count($nodeset) = count($node | $nodeset)
которое будет истинным тогда и только тогда, когда $nodeполностью принадлежит $nodeset.
Этот метод позволяет реализовать в XSLT другие операции над множествами — пересечение, разность и симметрическую разность. Подробное описание этих операций приводится в главе 11 .
В XSLT также нет оператора, который позволил бы проверить тождественность двух узлов. Например, если каждое из множеств $Aи $Bсодержит по одному узлу, при помощи простого оператора равенства ( $A = $B) мы не сможем проверить, один и тот же это узел или два разных узла с одинаковыми текстовыми значениями.
Для того чтобы корректно выполнить такое сравнение, можно использовать функцию generate-id, которая для каждого из узлов дерева генерирует уникальный строковый идентификатор, присущий только этому узлу и никакому другому, причем для одних и тех же узлов идентификаторы всегда будут генерироваться одинаковыми. Таким образом, для проверки тождественности двух узлов, содержащихся во множествах $Aи $B, будет достаточно сравнить их уникальные идентификаторы:
generate-id($А) = generate-id($В)
Множества узлов могут быть преобразованы в булевые значения, числа и строки.
При преобразовании в булевый тип пустое множество узлов преобразуется в false, а непустое — в true. Например, чтобы проверить, есть ли у текущего узла атрибут value, можно написать:
Value attribute exists here.
Выражение @valueвозвратит непустое множество, состоящее из узла атрибута value, если он есть в текущем элементе, или пустое множество, если такого атрибута нет. В первом случае логическим эквивалентом будет true, во втором — false, то есть текст будет выведен только в случае наличия атрибута value.
При преобразовании множества узлов в строку, результатом будет строковое значение первого в порядке просмотра узла множества.
A
B
C
D
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
Результат:
A
При преобразовании множества узлов в число, множество сначала приводится к строке, а затем строка преобразуется в численное значение. Проще говоря, численным значением множества узлов будет численное значение первого узла в порядке просмотра документа.
1
1.5
2
2.6
3
3.7
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
Результат:
0.5
Результирующий фрагмент дерева (result tree fragment)
Четыре типа данных, описанных выше, заимствованы языком XSLT из XPath. Вместе с тем, XSLT имеет и свой собственный тип данных, называемый result tree fragment (результирующий фрагмент дерева).
Для того чтобы понять этот тип данных, обратимся к примеру шаблона:
You may visit the following link.
Если мы применим это правило к части документа
http://www.xsltdev.ru
то получим следующий результат:
You may visit the following link.
В терминах деревьев выполнение этого шаблона показано на рис. 3.17.
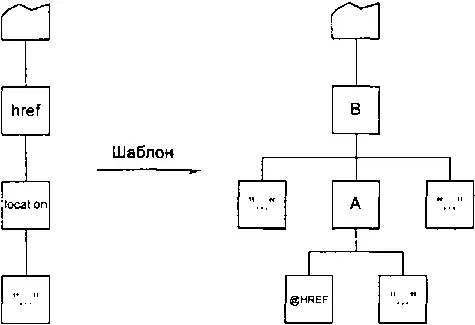
Рис. 3.17. Часть дерева входящего документа и часть дерева сгенерированного документа
Поскольку XSLT оперирует документами, представленными в виде деревьев, уместнее будет сказать, что на самом деле шаблоны обрабатывают фрагменты входящего дерева и создают фрагменты исходящего. Последним и соответствует тип данных, который в XSLT называют результирующим фрагментом дерева . Попросту говоря, все, что создается шаблонами во время выполнения преобразования, является результирующими фрагментами и, в конечном итоге, дерево выходящего документа есть композиция этих фрагментов.
Читать дальшеИнтервал:
Закладка:

