Джулиан Бакнелл - Фундаментальные алгоритмы и структуры данных в Delphi

- Название:Фундаментальные алгоритмы и структуры данных в Delphi
- Автор:
- Жанр:
- Издательство:ДиаСофтЮП
- Год:2003
- ISBN:ISBN 5-93772-087-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Джулиан Бакнелл - Фундаментальные алгоритмы и структуры данных в Delphi краткое содержание
Книга "Фундаментальные алгоритмы и структуры данных в Delphi" представляет собой уникальное учебное и справочное пособие по наиболее распространенным алгоритмам манипулирования данными, которые зарекомендовали себя как надежные и проверенные многими поколениями программистов. По данным журнала "Delphi Informant" за 2002 год, эта книга была признана сообществом разработчиков прикладных приложений на Delphi как «самая лучшая книга по практическому применению всех версий Delphi».
В книге подробно рассматриваются базовые понятия алгоритмов и основополагающие структуры данных, алгоритмы сортировки, поиска, хеширования, синтаксического разбора, сжатия данных, а также многие другие темы, тесно связанные с прикладным программированием. Изобилие тщательно проверенных примеров кода существенно ускоряет не только освоение фундаментальных алгоритмов, но также и способствует более квалифицированному подходу к повседневному программированию.
Несмотря на то что книга рассчитана в первую очередь на профессиональных разработчиков приложений на Delphi, она окажет несомненную пользу и начинающим программистам, демонстрируя им приемы и трюки, которые столь популярны у истинных «профи». Все коды примеров, упомянутые в книге, доступны для выгрузки на Web-сайте издательства.
Фундаментальные алгоритмы и структуры данных в Delphi - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Таблица 11.4. Коды Шеннона-Фано для примера предложения

Сейчас мы можем вычислить код для всей фразы. Он начинается с
11100011110000111110100010101100...
и содержит всего 131 бит. Если мы предполагаем, что исходная фраза закодирована кодом ASCII, т.е. один байт на символ, то оригинальная фраза заняла бы 256 байт, т.е. мы получаем коэффициент сжатия 54%.
Для декодирования сжатого потока битов мы строим то же дерево, которое было построено на этапе сжатия. Мы начинаем с корневого узла и выбираем из сжатого потока битов по одному биту. Если бит является нулевым, мы перемещаемся влево, если единичным - вправо. Мы продолжаем этот процесс до тех пор, пока не достигнем листа, т.е. символа, после чего выводим символ в поток восстановленных данных. Затем мы снова начинаем процесс с корневого узла дерева с целью извлечения следующего бита. Обратите внимание, что поскольку символы расположены только в листьях дерева, код одного символа не образует первую часть кода другого символа. Благодаря этому, неправильное декодирование сжатых данных невозможно. (Бинарное дерево, в котором данные размещены только в листьях, называется префиксным деревом (prefix tree).)
Однако при этом возникает небольшая проблема: как распознать конец потока битов? В конце концов, внутри класса мы будем объединять восемь битов в байт, после чего выполнять запись байта. Маловероятно, чтобы поток битов содержал количество битов строго кратное 8. Существует два возможных решения этой дилеммы. Первое - закодировать специальный символ, отсутствующий в исходных данных, и назвать его символом конца файла. Второе - записать в сжатый поток длину несжатых данных перед тем, как приступить к сжатию самих данных. Первое решение вынуждает нас найти отсутствующий в исходных данных символ и использовать его (это предполагает передачу этого символа в составе сжатых данных программе восстановления, чтобы она знала, что следует искать). Или же можно было бы принять, что хотя символы данных имеют размер, равный размеру одного байта, символ конца файла имеет длину, равную длину слова (и заданное значение, например 256). Однако мы будем использовать второе решение. Перед сжатыми данными мы будем сохранять длину несжатых данных, и таким образом во время восстановления будет в точности известно, сколько символов нужно декодировать.
Еще одна проблема применения кодирования Шеннона-Фано, на которую до сих пор мы не обращали внимания, связана с деревом. Обычно сжатие данных выполняется в целях экономии объема памяти или уменьшения времени передачи данных. Как правило, сжатие и восстановление данных разнесено во времени и пространстве. Однако алгоритм восстановления требует использования дерева. В противном случае невозможно декодировать закодированный поток. Нам доступны две возможности. Первая - сделать дерево статическим. Иначе говоря, одно и то же дерево будет использоваться для сжатия всех данных. Для некоторых данных результирующее сжатие будет достаточно оптимальным, для других - весьма далеким от приемлемого. Вторая возможность состоит в том, чтобы тем или иным способом присоединить само дерево к сжатому потоку битов. Конечно, присоединение дерева к сжатым данным ведет к снижению коэффициента сжатия, но с этим ничего нельзя поделать. Вскоре, при рассмотрении следующего алгоритма сжатия, мы покажем, как можно добавить дерево к сжатым данным.
Кодирование Хаффмана
Алгоритм кодирования Хаффмана очень похож на алгоритм сжатия Шеннона-Фано. Этот алгоритм был изобретен Девидом Хаффманом (David Huffman) в 1952 году ("A method for the Construction of Minimum-Redundancy Codes" ("Метод создания кодов с минимальной избыточностью")), и оказался еще более удачным, чем алгоритм Шеннона-Фано. Это обусловлено тем, что алгоритм Хаффмана математически гарантированно создает наименьший по размеру код для каждого из символов исходных данных.
Аналогично применению алгоритма Шеннона-Фано, нужно построить бинарное дерево, которое также будет префиксным деревом, где все данные хранятся в листьях. Но в отличие от алгоритма Шеннона-Фано, который является нисходящим, на этот раз построение будет выполняться снизу вверх. Вначале мы выполняем просмотр входных данных, подсчитывая количество появлений значений каждого байта, как это делалось и при использовании алгоритма Шеннона-Фано. Как только эта таблица частоты появления символов будет создана, можно приступить к построению дерева.
Будем считать эти пары символ-количество "пулом" узлов будущего дерева Хаффмана. Удалим из этого пула два узла с наименьшими значениями количества появлений. Присоединим их к новому родительскому узлу и установим значение счетчика родительского узла равным сумме счетчиков его двух дочерних узлов. Поместим родительский узел обратно в пул. Продолжим этот процесс удаления двух узлов и добавления вместо них одного родительского узла до тех пор, пока в пуле не останется только один узел. На этом этапе можно удалить из пула один узел. Он является корневым узлом дерева Хаффмана.
Описанный процесс не очень нагляден, поэтому создадим дерево Хаффмана для предложения "How much wood could a woodchuck chuck?" Мы уже вычислили количество появлений символов этого предложения и представили их в виде таблицы 11.1, поэтому теперь к ней потребуется применить описанный алгоритм с целью построения полного дерева Хаффмана. Выберем два узла с наименьшими значениями. Существует несколько узлов, из которых можно выбрать, но мы выберем узлы "m" и Для обоих этих узлов число появлений символов равно 1. Создадим родительский узел, значение счетчика которого равно 2, и присоединим к нему два выбранных узла в качестве дочерних. Поместим родительский узел обратно в пул. Повторим цикл с самого начала. На этот раз мы выбираем узлы "а" и "Д.", объединяем их в мини-дерево и помещаем родительский узел (значение счетчика которого снова равно 2) обратно в пул. Снова повторим цикл. На этот раз в нашем распоряжении имеется единственный узел, значение счетчика которого равно 1 (узел "Н") и три узла со значениями счетчиков, равными 2 (узел "к" и два родительских узла, которые были добавлены перед этим). Выберем узел "к", присоединим его к узлу "H" и снова добавим в пул родительский узел, значение счетчика которого равно 3. Затем выберем два родительских узла со значениями счетчиков, равными 2, присоединим их к новому родительскому узлу со значением счетчика, равным 4, и добавим этот родительский узел в пул. Несколько первых шагов построения дерева Хаффмана и результирующее дерево показаны на рис. 11.2.
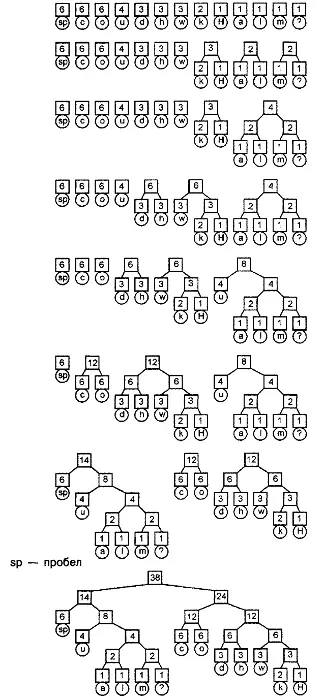
Рисунок 11.2. Построение дерева Хоффмана
Читать дальшеИнтервал:
Закладка:

