Александр Чесалов - Глоссариум по искусственному интеллекту и информационным технологиям

- Название:Глоссариум по искусственному интеллекту и информационным технологиям
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:неизвестен
- ISBN:9785005589576
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Александр Чесалов - Глоссариум по искусственному интеллекту и информационным технологиям краткое содержание
Глоссариум по искусственному интеллекту и информационным технологиям - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Машинный разум (Machine intelligence) – это общий термин, охватывающий машинное обучение, глубокое обучение и классические алгоритмы обучения.
Машины опорных векторов или сети опорных векторов (Support-vector machines, Support-vector networks) – это контролируемые модели обучения с соответствующими алгоритмами обучения, которые анализируют данные для классификации и регрессионного анализа. Разработаны в AT&T Bell Laboratories Владимиром Вапником с коллегами в 1992 году. Машины опорных векторов являются одним из самых надежных методов прогнозирования, основанным на статистическом обучении или теории теории Вапника – Червоненкиса, предложенной Вапником (1982, 1995) и Червоненкисом (1974). Учитывая набор обучающих примеров, каждый из которых помечен как принадлежащий к одной из двух категорий, алгоритм обучения машины опорных векторов строит модель, которая относит новые примеры к той или иной категории, превращая ее в невероятностный двоичный линейный классификатор (хотя методы такие как масштабирование Платта, существуют для использования машин опорных векторов в вероятностной классификации). Машины опорных векторов сопоставляют обучающие примеры с точками в пространстве, чтобы максимизировать ширину разрыва между двумя категориями. Затем новые примеры сопоставляются с тем же пространством, и их принадлежность к категории определяется в зависимости от того, на какую сторону разрыва они попадают. В дополнение к выполнению линейной классификации SVM могут эффективно выполнять нелинейную классификацию, используя так называемый трюк ядра, неявно отображая свои входные данные в многомерные пространства признаков. Когда данные не размечены, обучение с учителем невозможно, и требуется подход к обучению без учителя, который пытается найти естественную кластеризацию данных в группы, а затем сопоставляет новые данные с этими сформированными группами. Алгоритм кластеризации опорных векторов, созданный Хавой Зигельманн и Владимиром Вапником, применяет статистику опорных векторов, разработанную в алгоритме машин опорных векторов, для категоризации неразмеченных данных.
Мероприятия по информатизации (Informatization activities) – это предусмотренные мероприятия программ цифровой трансформации государственных органов, направленные на создание, развитие, эксплуатацию или использование информационно-коммуникационных технологий, а также на вывод из эксплуатации информационных систем и компонентов информационно-телекоммуникационной инфраструктуры.
Мероприятия программы цифровой трансформации, осуществляемые государственным органом (Measures of the digital transformation program carried out by a state body) – это объединенная единой целью совокупность действий государственного органа, в том числе мероприятий по информатизации, направленных на выполнение задач по оптимизации административных процессов предоставления государственных услуг и (или) исполнения государственных функций, созданию, развитию, вводу в эксплуатацию, эксплуатации или выводу из эксплуатации информационных систем или компонентов информационно-коммуникационных технологий, нормативно-правовому обеспечению указанных процессов или иных задач, решаемых в рамках цифровой трансформации.
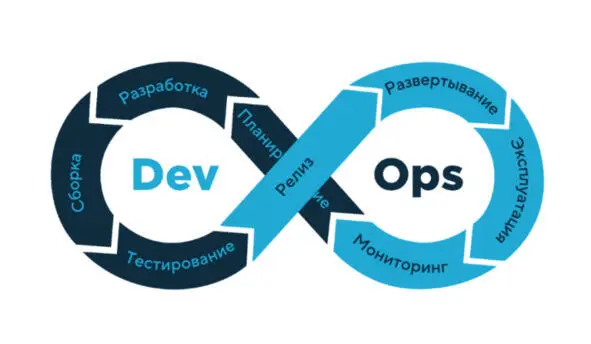
Методология разработки и операции (DevOps development & operations) – это набор методик, инструментов и философия культуры, которые позволяют автоматизировать и интегрировать между собой процессы команд разработки ПО и ИТ-команд. Особое внимание в DevOps уделяется расширению возможностей команд, их взаимодействию и сотрудничеству, а также автоматизации технологий. Под термином DevOps также понимают особый подход к организации команд разработки. Его суть в том, что разработчики, тестировщики и администраторы работают в едином потоке – не отвечают каждые за свой этап, а вместе работают над выходом продукта и стараются автоматизировать задачи своих отделов, чтобы код переходил между этапами без задержек. В DevOps ответственность за результат распределяется между всей командой [ 28 28 .Методология разработки и операции [Электронный ресурс] www.atlassian.com URL: https://www.atlassian.com/ru/devops (дата обращения: 07.07.2022)
, 29 29 .Методология разработки и операции [Электронный ресурс] //mcs.mail.ru URL: https://mcs.mail.ru/blog/chto-takoe-metodologiya-devops (дата обращения: 07.07.2022)
].
Методы эвристического поиска (Heuristic search techniques) – это методы, которые сужают поиск оптимальных решений проблемы за счет исключения неверных вариантов
Механизм внимания (Attention mechanism) – это одно из ключевых нововведений в области нейронного машинного перевода. Внимание позволило моделям нейронного машинного перевода превзойти классические системы машинного перевода, основанные на переводе фраз. Основным узким местом в sequence-to-sequence обучении является то, что все содержимое исходной последовательности требуется сжать в вектор фиксированного размера. Механизм внимания облегчает эту задачу, так как позволяет декодеру оглядываться на скрытые состояния исходной последовательности, которые затем в виде средневзвешенного значения предоставляются в качестве дополнительных входных данных в декодер.
Минимизация структурных рисков (Structural risk minimization, SRM) – это индуктивный принцип использования в машинном обучении. Обычно в машинном обучении обобщенная модель должна быть выбрана из конечного набора данных, что приводит к проблеме переобучения – модель становится слишком строго адаптированной к особенностям обучающего набора и плохо обобщается для новых данных. Принцип SRM решает эту проблему, уравновешивая сложность модели с ее успехом в подборе обучающих данных. Этот принцип был впервые изложен в статье 1974 года Владимира Вапника и Алексея Червоненкиса.
Многозадачное обучение (Multitask learning) – это общий подход, при котором модели обучаются выполнению различных задач на одних и тех же параметрах. В нейронных сетях этого можно легко добиться, связав веса разных слоев. Идея многозадачного обучения была впервые предложена Ричем Каруаной в 1993 году и применялась для прогнозирования пневмонии, а также для создания системы следования дороге на беспилотных устройствах (Каруана, 1998). Фактически при многозадачном обучении модель стимулируют к созданию внутри себя такого представления данных, которые позволяет выполнить сразу много задач. Это особенно полезно для обучения общим низкоуровневым представлениям, на базе которых потом происходит «концентрация внимания» модели или в условиях ограниченного количества обучающих данных. Многозадачное обучение нейросетей для обработки естественного языка было впервые применено в 2008 году Коллобером и Уэстоном (Collobert & Weston, 2008).
Читать дальшеИнтервал:
Закладка:









