Дэвид Шпигельхалтер - Искусство статистики. Как находить ответы в данных

- Название:Искусство статистики. Как находить ответы в данных
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2021
- Город:Москва
- ISBN:9785001692508
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Дэвид Шпигельхалтер - Искусство статистики. Как находить ответы в данных краткое содержание
Эта книга предназначена как для студентов, которые хотят ознакомиться со статистикой, не углубляясь в технические детали, так и для широкого круга читателей, интересующихся статистикой, с которой они сталкиваются на работе и в повседневной жизни. Но даже опытные аналитики найдут в книге интересные примеры и новые знания для своей практики. На русском языке публикуется впервые.
Искусство статистики. Как находить ответы в данных - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
специфичность:доля «отрицательных» случаев, которые правильно определены при классификации или тестировании. Единица минус специфичность – это доля ложноположительных наблюдений (ошибка первого рода);
Спирмена ранговый коэффициент корреляции:ранг наблюдения – это его номер в вариационном ряду (упорядоченном наборе), причем равным величинам приписывается одинаковый средний ранг. Например, если у нас есть набор данных (3, 2, 1, 0, 1), то соответствующий набор рангов – (5, 4, 2,5, 1, 2,5). Ранговый коэффициент корреляции Спирмена – это просто коэффициент корреляции Пирсона, в котором наборы x и y заменены их соответствующими рангами;
среднее (выборки):1) в широком смысле – общий термин для какой-то одной величины, характеризующей набор чисел, например среднее арифметическое, медиана или мода; 2) в узком смысле – то же, что среднее арифметическое (также говорят выборочное среднее). Предположим, что у нас есть выборка (набор чисел) x 1, x 2,…, x n . Тогда их выборочное среднее определяется формулой m = ( x 1 + x 2 +…+ x n )/ n , что можно записать в виде 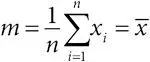 . Например, если пять человек сообщили о количестве своих детей и получилась выборка 3, 2, 1, 0, 1, то среднее число детей равно (3 + 2 + 1 + 0)/5 = 7/5 = 1,4;
. Например, если пять человек сообщили о количестве своих детей и получилась выборка 3, 2, 1, 0, 1, то среднее число детей равно (3 + 2 + 1 + 0)/5 = 7/5 = 1,4;
среднее (популяции):см. математическое ожидание ;
среднеквадратичная ошибка:мера качества прогноза; если спрогнозированы значения t 1, t 2,…, t n , а сделаны наблюдения x 1, x 2,…, x n , то среднеквадратичная ошибка равна 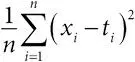 ;
;
среднеквадратичное (стандартное) отклонение:квадратный корень из дисперсии выборки или распределения. Для хорошо себя ведущих разумно симметричных распределений без длинных хвостов можно ожидать, что подавляющее большинство наблюдений будут лежать в пределах двух стандартных отклонений от выборочного среднего;
стандартная ошибка:стандартное отклонение выборочного среднего, когда оно рассматривается как случайная величина. Предположим, что X 1, X 2,…, X n – это независимые одинаково распределенные случайные величины, взятые из распределения со средним μ и среднеквадратичным отклонением σ. Тогда их среднее Y = ( X 1 + X 2 +…+ X n )/ n имеет среднее μ и дисперсию σ 2/ n . Стандартное отклонение для Y равно σ/√ n и известно как стандартная ошибка. Оценкой будет s /√ n , где s – выборочное стандартное отклонение для наблюдаемых величин X ;
статистика:1) дисциплина, занимающаяся изучением мира на основе данных; как правило, включает цикл решения проблем наподобие PPDAC; 2) какая-либо функция от данных. Например, наибольшее значение выборки, выборочное среднее, интерквартильный размах, выборочная дисперсия – различные статистики;
статистическая значимость:наблюдаемый эффект считается статистически значимым, когда P-значение, соответствующее нулевой гипотезе, меньше некоторого заранее установленного уровня, например 0,05 или 0,001. Это означает, что такой экстремальный результат маловероятен при справедливости нулевой гипотезы и всех прочих предположениях при моделировании;
статистическая модель:математическое представление вероятностного распределения какого-либо набора случайных величин, содержащее неизвестные параметры;
статистическое заключение:процесс использования данных выборки, для того чтобы что-либо узнать о неизвестных параметрах, лежащих в основе статистической модели;
стохастическая неопределенность:неизбежная непредсказуемость будущего, также известная как случайность, случай и так далее;
судебная эпидемиология:использование знаний о причинах заболеваний в популяциях при вынесении суждений о случаях болезни у отдельных людей;
счетные переменные:переменные, которые могут принимать целочисленные значения 0, 1, 2 и так далее или быть взаимнооднозначно сопоставлены с такими значениями;
тест перестановки/рандомизации:форма критерия для проверки гипотезы, когда распределение тестовой статистики при нулевой гипотезе получается не с помощью детальной статистической модели для случайных величин, а путем перестановки «меток» данных. Предположим, что нулевая гипотеза такова: какая-то «метка» (например, мужчина это или женщина) не связана с результатом обследования. Тесты рандомизации исследуют все возможные способы перестановки таких меток для отдельных элементов данных, при этом при нулевой гипотезе все они равновероятны. Для каждой перестановки вычисляется тестовая статистика, а P-значение определяется как доля тех перестановок, где получаются более экстремальные значения тестовой статистики, нежели реально наблюдаемые;
уровень ложноположительных результатов:при проверке многих гипотез доля положительных утверждений, которые оказываются ложноположительными;
фрейминг:выбор способа подачи информации, влияющего на впечатление аудитории;
центральная предельная теорема:общее название нескольких теорем, утверждающих, что при определенных условиях выборочное среднее для множества случайных величин сходится к нормальному распределению вне зависимости (за некоторыми исключениями) от исходного распределения этих случайных величин. Если у нас есть n независимых наблюдений с математическим ожиданием μ и дисперсией σ 2, то при широких условиях их выборочное среднее является оценкой для μ и приближенно имеет нормальное распределение со средним μ, дисперсией σ 2/ n и среднеквадратичным отклонением σ√ n (также известным как стандартная ошибка оценки);
цикл PPDAC:предлагаемая структура «цикла данных», куда входят проблема, планирование, сбор данных, анализ (поисковый или подтверждающий), заключение и коммуникация ;
чувствительность:доля «положительных» случаев, которые правильно определены при классификации или тестировании; часто называется долей истинно положительных наблюдений. Единица минус чувствительность – это доля ложноотрицательных наблюдений (ошибка второго рода);
шансы, отношения шансов:если вероятность какого-то события равна p , то шансы для такого события определяются как 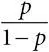 . Если шансы для какого-то события в группе с воздействием равны , а шансы в группе без воздействия –
. Если шансы для какого-то события в группе с воздействием равны , а шансы в группе без воздействия – 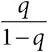 , то отношение шансов составит
, то отношение шансов составит 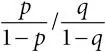 . Если p и q малы, то отношение шансов близко к относительному риску p/q , но если абсолютные риски значительно превышают 20 %, то отношения шансов и относительные риски начинают различаться;
. Если p и q малы, то отношение шансов близко к относительному риску p/q , но если абсолютные риски значительно превышают 20 %, то отношения шансов и относительные риски начинают различаться;
Интервал:
Закладка:







