Дэвид Шпигельхалтер - Искусство статистики. Как находить ответы в данных

- Название:Искусство статистики. Как находить ответы в данных
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2021
- Город:Москва
- ISBN:9785001692508
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Дэвид Шпигельхалтер - Искусство статистики. Как находить ответы в данных краткое содержание
Эта книга предназначена как для студентов, которые хотят ознакомиться со статистикой, не углубляясь в технические детали, так и для широкого круга читателей, интересующихся статистикой, с которой они сталкиваются на работе и в повседневной жизни. Но даже опытные аналитики найдут в книге интересные примеры и новые знания для своей практики. На русском языке публикуется впервые.
Искусство статистики. Как находить ответы в данных - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
поперечное исследование:исследование, в котором анализ основан исключительно на текущем состоянии участников, без какого-либо последующего наблюдения в течение долгого времени;
поправка/стратификация:включение в регрессионную модель известных возмущающих факторов, которые не представляют прямого интереса, но позволяют провести более сбалансированное сравнение между группами; при этом можно надеяться, что оцененные эффекты, связанные с объясняющими переменными, должны быть ближе к причинной связи;
последовательное тестирование:когда какая-либо статистическая проверка повторно проводится на накапливающихся данных, что повышает вероятность появления в какой-то момент ошибки первого рода. Если процесс продолжается достаточно долго, гарантируется «значимый результат»;
правдоподобие:мера подтверждения, обеспечиваемая данными для конкретных значений параметра. Когда вероятностное распределение какой-либо случайно величины зависит от параметра, например θ, то после наблюдения данных x правдоподобие для θ пропорционально p ( x |θ);
практическая значимость:когда какой-нибудь результат имеет реальную важность. Масштабные исследования могут давать результаты, которые статистически значимы, но не имеют практической значимости;
предсказательная аналитика:использование данных в целях создания алгоритмов для прогнозов;
проверка гипотезы:формальная процедура для оценки подтверждения гипотезы имеющимися данными. Обычно представляет собой сочетание классических фишеровских критериев для проверки нулевой гипотезы с помощью P-значения и конструкции Неймана – Пирсона, где фигурируют нулевая и альтернативная гипотезы и ошибки первого и второго рода;
проспективное когортное исследование:когда выбирается множество испытуемых, измеряются фоновые факторы, а затем за ними следят и наблюдают за соответствующими результатами. Такие исследования – продолжительные и дорогостоящие и могут не идентифицировать многие редкие события;
процентиль (выборки):если взять упорядоченный набор данных (вариационный ряд), то, например, 70-й процентиль – это такая величина, что 70 % наблюдений будут меньше ее. В частности, медиана – это 50-й процентиль. При необходимости используется интерполяция;
процентиль (генеральной совокупности):например, 70-й процентиль – это такая величина, что с вероятностью 70 % ваше случайное наблюдение будет меньше ее;
Пуассона распределение:случайная величина X имеет пуассоновское распределение с параметром μ>0, если 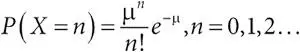 Математическое ожидание E ( X ) = μ, дисперсия D ( X ) = μ;
Математическое ожидание E ( X ) = μ, дисперсия D ( X ) = μ;
размах (выборки):разность между максимальным и минимальным значением, то есть x ( n ) − x ( 1 );
размер критерия:величина ошибки первого рода в каком-либо статистическом критерии, обычно обозначается α;
рандомизированное контролируемое исследование (РКИ):эксперимент, в котором люди или иные объекты случайным образом распределяются по различным вмешательствам, и такая случайность гарантирует, что группы будут сбалансированы в отношении известных и неизвестных факторов. Если в дальнейшем группы демонстрируют различные результаты, то либо вмешательство дало эффект, либо произошло какое-то удивительное событие, вероятность которого выражается через P-значение;
распределение выборки:закономерность в наборе числовых или категорийных наблюдений. Также именуется эмпирическим распределением, или распределением данных;
распределение генеральной совокупности (распределение популяции): когда она реально существует – закономерность, описывающая потенциальные наблюдения во всей популяции. Также так называется распределение порождающей случайной величины;
регрессия к среднему (регресс к среднему):когда в процессе естественных изменений наблюдается возврат от очень больших или малых наблюдений к более умеренным. Это происходит в силу того, что первоначальные экстремальные величины получались случайным образом, поэтому повторение в той же степени маловероятно;
регрессия Кокса:см. отношение рисков ;
ретроспективное когортное исследование:исследование, в рамках которого набор испытуемых определяется в какой-то момент в прошлом, а их характеристики прослеживаются вплоть до сегодняшнего дня. Такое исследование не требует продолжительного периода наблюдения, но зависит от надлежащих объясняющих переменных, измеренных в прошлом;
сигнал и шум:идея, согласно которой наблюдаемые данные включают два компонента: детерминистский сигнал, который нас действительно интересует, и случайный шум, включающий остаточные ошибки. Задача статистики – правильно идентифицировать оба компонента и не принять шум за сигнал;
Симпсона парадокс:когда при учете возмущающего фактора видимое направление взаимосвязи становится обратным;
систематическая ошибка установки:происходит, когда вероятность включения в выборку человека или наблюдаемой характеристики зависит от какого-то фактора, например, когда в каком-нибудь рандомизированном испытании наблюдение за людьми в испытуемой группе оказывается более тщательным, чем наблюдение за контрольной группой;
скрытый фактор:в эпидемиологии – воздействие, которое не определялось, но может быть возмущающим фактором, ответственным за часть наблюдаемой связи. Например, когда в исследовании изучается связь рациона и заболевания, но не учитывается социально-экономическое положение;
слепой метод:чтобы избежать предвзятости в оценивании результатов, участвующие в клиническом исследовании не обладают всей информацией. При слепом методе пациенты не знают, какое лечение получают. При двойном слепом методе люди, наблюдающие за больными, тоже не знают, какое лечение те получают. При тройном слепом методе распределение по методам лечения не знают также и статистики, анализирующие данные;
случайная величина:переменная величина, принимающая различные значения с какими-то вероятностями. Случайные величины обычно обозначаются прописными буквами, например X , в то время как наблюдаемые значения обозначаются x ;
случайный разброс:неизбежные различия, возникающие при измерениях и наблюдениях; некоторый из них могут объясняться известными факторами, а оставшиеся приписываются случайному шуму;
Читать дальшеИнтервал:
Закладка:







