Тревор Кокс - Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта

- Название:Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта
- Автор:
- Жанр:
- Издательство:КоЛибри, Азбука-Аттикус
- Год:2020
- Город:М.
- ISBN:978-5-389-17812-0
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Тревор Кокс - Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта краткое содержание
Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Но чтобы у компьютера появилась возможность обнаружить ложь, ему придется научиться понимать слова. Это позволит системе ориентироваться на другие признаки обмана, обнаруженные в научных исследованиях, например, на тот факт, что когда человек врет, он приводит меньше деталей и устанавливает меньше связей с внешними событиями {365} 365 Oberlader V. A., Naefgen C., Koppehele-Gossel J . Validity of content-based techniques to distinguish true and fabricated statements: A meta-analysis // Law and Human Behavior. 2016. Vol. 40 (4). P. 440.
. Но чтобы использовать эти данные, компьютеру нужно уметь распознавать речь и понимать ее семантику.
Одна из первых электронных систем распознавания речи, которая называлась «Одри», была создана в 1952 году К. Дэйвисом и его коллегами из Лабораторий Белла в США. Она могла распознавать отдельные цифры, а при тщательной настройке на конкретного говорящего правильно идентифицировала практически каждое слово. Как и другие первые системы, «Одри», по существу, работала по принципу подбора моделей. На рисунке выше показана запись голоса человека, который считает от одного до пяти. В верхней части — обычный способ представления звука, «виляющий» след, показывающий, как изменяется давление, создаваемое голосом, по мере произнесения пяти цифр. Второе слово, two , показывает два отдельных отрывка, [t] и [oo]. Оно начинается с взрывного [t], при котором воздух сначала блокируется языком, прижатым кверху, к нёбу, а когда язык отрывается, резкий выдох создает звук. За этим быстро следует гласный [oo], который почти пропевается. В нижней части — спектрограмма, показывающая изменение частотной характеристики речи. Для слова two темная линия опускается вниз слева направо, а для слова three видна диагональная темная линия, идущая в обратном направлении. Когда говорящий произносит вторую часть слова three , его интонация создает увеличение частоты, отсюда и идущая вверх линия на спектрограмме.
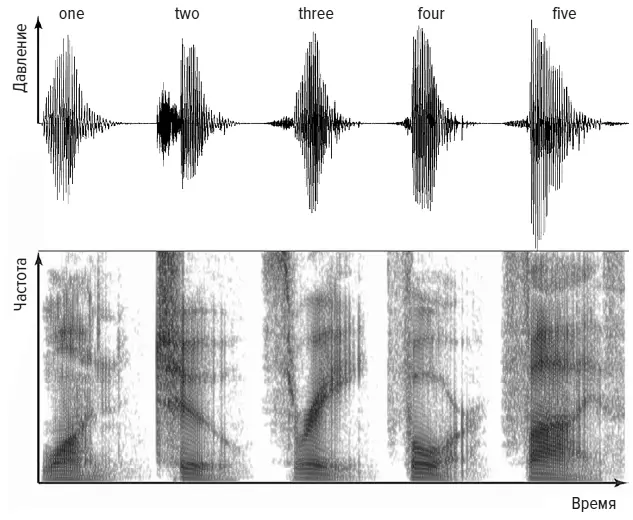
Мужской голос, считающий «one, two, three, four, five»
Спектрограммы подобны отпечаткам пальцев и показывают, что у каждой цифры уникальный рисунок. Задачей «Одри» было подобрать к образцу из произнесенного в микрофон звука пару из ожидаемых рисунков звука для каждой цифры. В 1950-е годы это было сложно реализовать, потому что для создания спектрограмм просто не было компьютеров. Более того, «Одри» была не слишком практичной системой. Джеймс Флэнаган из Лабораторий Белла вспоминал: «Она занимала релейную стойку шести футов (более 1,8 м) высотой, была ужасно дорогой, поглощала солидное количество энергии и создавала мириад проблем обслуживания, связанных со сложной ламповой схемой» {366} 366 Jim Flanagan et al. Techniques for expanding the capabilities of practical speech recognizers // Trends in Speech Recognition. 1980. Больше об Одри см.: Davis K. H., Biddulph R., Balashek S . Automatic recognition of spoken digits // Journal of the Acoustical Society of America. 1952. Vol. 24 (6). P. 637–642.
.
Еще одна проблема, связанная с подобным типом анализа, состоит в том, что человек не всегда одинаково произносит слова. Например, слово, которое обычно произносится с понижающейся частотой, в конце вопросительного предложения может произноситься с повышающейся интонацией. Кроме того, у разных людей произношение может сильно отличаться, так что ваша спектрограмма счета от одного до пяти будет отличаться от моей. Даже лучшие современные системы, которые используют значительно более изощренные технологии, чем «Одри», не срабатывают. Когда в 2011 году iPhone 4S появился на рынке Великобритании, голосовой помощник Siri с трудом понимал сильный шотландский акцент {367} 367 Say what? iPhone has problems with Scots accents // BBC. 2011. http://www.bbc.co.uk/news/uk-scotland-15475989 .
.
В последние годы появление мощных компьютеров и использование машинного обучения вполовину снизили количество ошибок при распознавании речи. Современные системы еще далеки от того, чтобы распознавать речь так же, как это делает человек, но им больше не требуется, чтобы вы говорили медленно и делали паузы между словами. Более того, в эпоху больших объемов данных эти системы обучаются на огромном количестве примеров. Именно так Apple решила проблемы с Siri: компьютер прослушал огромное количество записей шотландского произношения, чтобы его запомнить. Кроме того, большие объемы данных означают, что системы распознавания речи обладают огромным словарем — например, голосовой помощник Google претендует на знание примерно трех миллионов слов. Это значительно превышает возможности человека. Поэтому система распознавания речи будет работать, даже если вы прибегаете к очень узкой теме со своим специализированным набором слов.
В наши дни каждый человек создает огромные массивы цифровых данных, совершая покупки, используя социальные сети или осуществляя поиск в интернете. При этом мы передаем компаниям огромное количество информации о себе — в обмен на бесплатные услуги. То, что мы позволяем компьютерам подслушивать наши голоса, делает эти сведения еще более ценными, потому что, помимо слов, это дает возможность узнать и о наших чувствах.
Однако применение машинного самообучения в больших объемах данных может привести к неожиданным негативным последствиям. Можно подумать, что, поскольку эти системы разработаны на языке математики и алгоритмов, они будут столь же объективны, как доктор Спок из «Звездного пути». Но программное обеспечение усваивает и социальные предрассудки, которые содержатся в используемых им данных. В 2017 году Айлин Калискан и ее коллеги из Принстонского университета проанализировали ассоциации между словами в популярной базе данных, которая использовалась для обучения алгоритмов машинного самобучения {368} 368 Caliskan A., Bryson J. J., Narayanan A . Semantics derived automatically from language corpora contain human-like biases // Science. 2017. Vol. 356 (6334). P. 183–186.
. В этой базе данных содержались миллиарды слов, закачанных из интернета. В одном из тестов Калискан исследовала, какие имена собственные появлялись в предложениях с приятными словами, например «любовь», а какие — в предложениях с неприятными словами, например «уродливый». Результаты показали наличие расовых предрассудков: имена европейцев и белых американцев чаще связывались с приятными словами, чем имена афроамериканцев. Еще в одном тесте проявился гендерный предрассудок: мужские имена чаще ассоциировались со словами, относящимися к работе, например «профессионал» и «зарплата», а женские имена оказались ближе к словам, описывающим семью, например «родители» и «свадьба». Пополняйте алгоритм машинного самообучения примерами из такой базы — и вы рискуете создать сексистское и расистское программное обеспечение.
Подобная предвзятость уже наблюдается в таких популярных инструментах, как переводчик Google. Например, используем его для перевода с турецкого на английский двух фраз: o bir doktor и o bir hemşire . Результат будет такой: he is a doctor («он — врач») и she is a nurse («она — медсестра») {369} 369 Этот пример взят из: Biased bots: Human prejudices sneak into artificial intelligence systems // Science News. 2017. https://www.sciencedaily.com/releases/2017/04/170413141055.htm .
. Но o в турецком языке — это местоимение третьего лица, не указывающее на пол. Представление о том, что врач мужчина, а медсестра — женщина, отражает культурные предрассудки и асимметричное распределение пола в сфере медицины: мы получили сексистский алгоритм. Использование такого алгоритма для просмотра заявлений о приеме на работу усилит существующие культурные предубеждения. Хотя дискуссии вокруг искусственного интеллекта нередко фокусируются на алгоритмах, часто именно данные определяют его работу и могут привести к нежелательным и опасным результатам. В 2015 году компания Flickr выпустила систему распознавания образов, в которой черные люди были неверно обозначены как «обезьяны», а фотографии концентрационных лагерей в Дахау и Аушвице как «конструкция для лазания» и «спорт». Если не соблюдать осторожность, подобные ошибки могут возникать, когда компьютеры будут идентифицировать характеристики людей по их речи. И это будет связано с тем, что в нашем голосе содержится тонкая, но часто противоречивая информация о расе, сексуальности и гендере.
Интервал:
Закладка:









