Мередит Бруссард - Искусственный интеллект [Пределы возможного] [litres]
![Мередит Бруссард - Искусственный интеллект [Пределы возможного] [litres]](/books/1073206/meredit-brussard-iskusstvennyj-intellekt-predely.webp "Обложка книги")
- Название:Искусственный интеллект [Пределы возможного] [litres]
- Автор:
- Жанр:
- Издательство:Литагент Альпина
- Год:2020
- Город:Москва
- ISBN:978-5-0013-9230-9
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Мередит Бруссард - Искусственный интеллект [Пределы возможного] [litres] краткое содержание
Всеобщий энтузиазм по поводу применения компьютерных технологий, по ее убеждению, уже привел к огромному количеству недоработанных решений в области проектирования цифровых систем. Выступая против техношовинизма и социальных иллюзий о спасительной роли технологий, Бруссард отправляется в путешествие по компьютерному миру: рискуя жизнью, садится за руль экспериментального автомобиля с автопилотом; задействует искусственный интеллект, чтобы выяснить, почему студенты не могут сдать стандартизованные тесты; использует машинное обучение, подсчитывая вероятность выживания пассажиров «Титаника»; как дата-журналист создает программу для поиска махинаций при финансировании кандидатов в президенты США.
Только понимая пределы компьютерных технологий, утверждает Бруссард, мы сможем распорядиться ими так, чтобы сделать мир лучше.
Искусственный интеллект [Пределы возможного] [litres] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
train [“Age”] = train [“Age”].fillna (train [“Age”].median ())
Алгоритм не работает при отсутствующих значениях. Поэтому придется исправить ситуацию. Создатели упражнения на DataCamp советуют воспользоваться медианой.
Посмотрим на данные.
# Напечатать данные, чтобы увидеть доступные признаки
print (train)
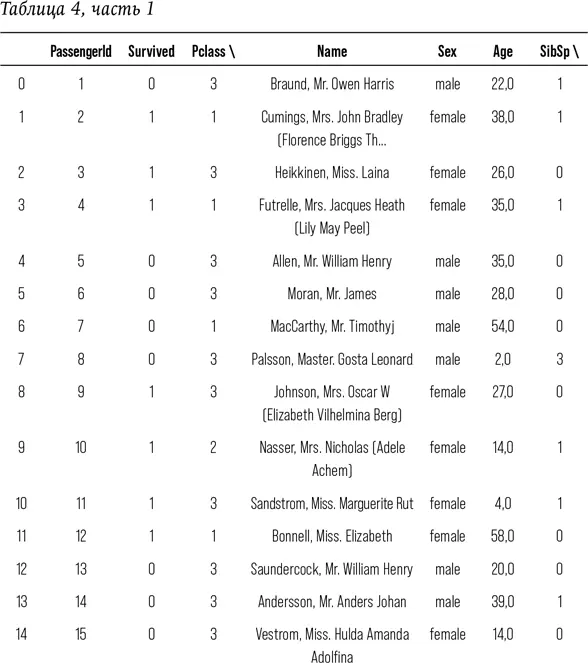
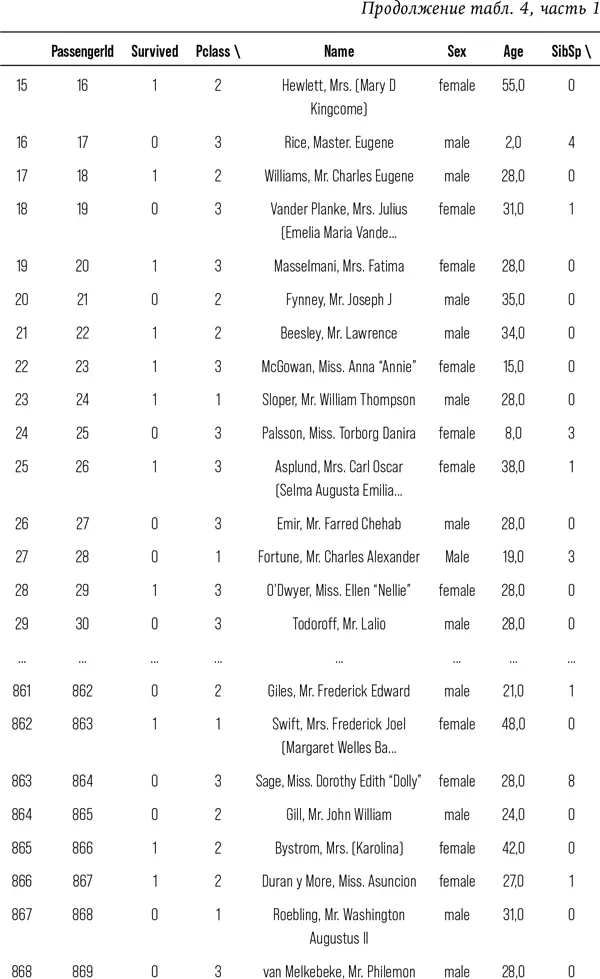
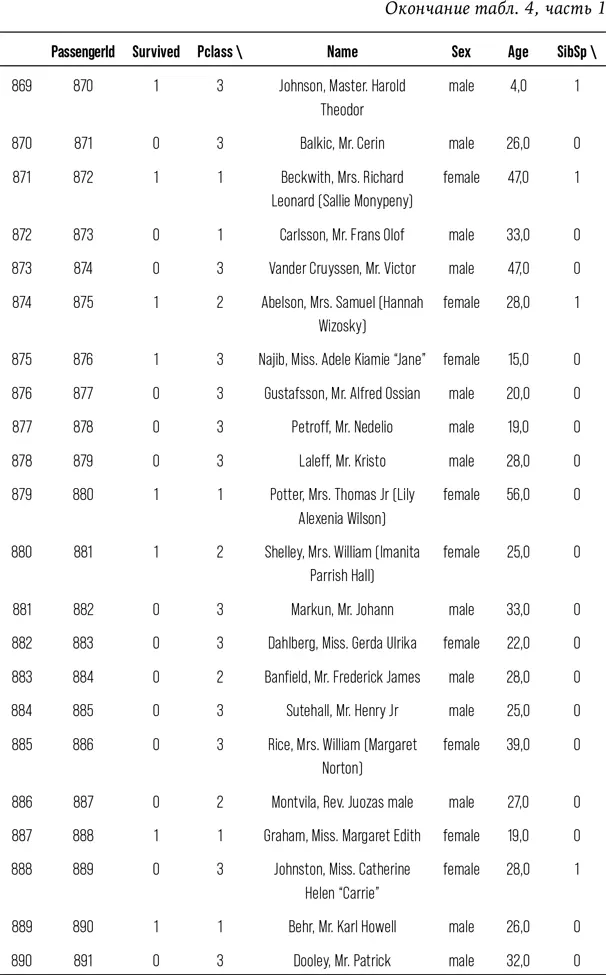
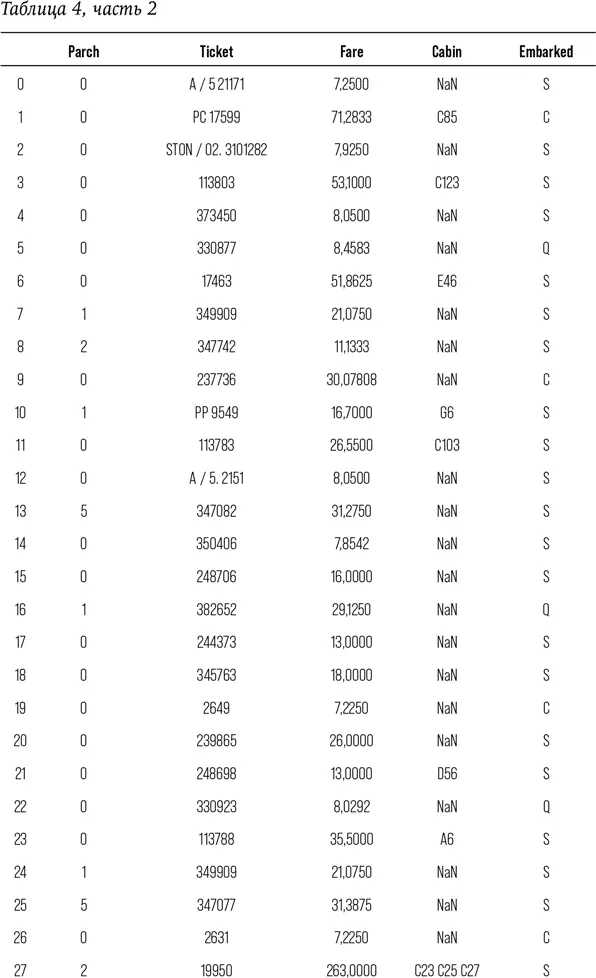
Если вы прочли все эти сотни строк – браво; если же вы их попросту пропустили, то я не удивлена. Я вывела вам столько строк данных специально, чтобы показать, каково это, быть аналитиком данных. Работа с колонками чисел кажется бессмысленной и иногда весьма утомительной. Есть в работе с данными что-то антигуманное. Непросто каждую секунду помнить о том, что за этим массивом цифр скрываются реальные люди с собственными надеждами, мечтами, семьями и историей.
Итак, мы познакомились с сырыми данными, теперь приступим к их обработке. Превратим их в массивы , структуры, которыми компьютер может манипулировать:
# Задать цели и свойства массивов: target, features_one
target = train [ «Survived»].values
# Предварительная обработка
encoded_sex = preprocessing.LabelEncoder ()
# Преобразование
train.Sex = encoded_sex.fit_transform (train.Sex)
features_one = train [[“Pclass,” “Sex,” “Age,” “Fare”]].values
# Подобрать первое дерево решений: my_tree_one
my_tree_one = tree.DecisionTreeClassifier () my_tree_one = my_tree_one.fit (features_one, target)
Мы только что запустили функцию под названием fit (подборка) на классификаторе, основанном на дереве принятия решений под названием my_tree_one. Признаки, которые мы ходим принять в расчет: Pclass, Sex, Age и Fare. Мы просим алгоритм выяснить, какая существует взаимосвязь между этими четырьмя факторами и целевым полем Survived:
# Посмотрим на значимость и оценку включенных признаков
print (my_tree_one.feature_importances_)
[0.12315342 0.31274009 0.22675108 0.3373554]
Переменная feature_importances показывает статистическую значимость каждого прогностического фактора.
Наибольшее число указывает на наивысшее значение из всей группы:
Pclass = 0, 1269655
Sex = 0, 31274009
Age = 0, 23914906
Fare = 0, 32114535
Fare (пассажирский тариф) – самое большое число. Можно сделать вывод, согласно которому стоимость билета была наиболее весомым фактором, повлиявшим на выживание пассажиров во время крушения «Титаника».
На этом этапе работы с данными мы проверим, насколько верны наши оценки с точки зрения математики. Воспользуемся функцией score:
print (my_tree_one.score (features_one, target))
0.977553310887
Ух ты, 97 %! Выглядит впечатляюще. Если бы я получила 97 % на экзамене, я была бы счастлива. Можно сказать, что наша модель точна на 97 %. Машина только что «выучила» процесс создания математической модели. А сама модель хранится в объекте под названием my_tree_one .
Теперь попробуем применить эту модель к тестовому пакету данных. Обратим внимание, что в нем нет колонки с данными о выживших. Наша задача заключается в том, чтобы при помощи созданной модели попытаться выяснить, выжил пассажир либо нет. Нам известно, что наибольшее влияние на результат имеет стоимость билетов, однако пассажирский класс (Pclass), пол (Sex) и возраст (Age) также имеют значение. Применим данные к тестовому пакету и посмотрим, что получится:
# Возместим отсутствующие данные о тарифе с помощью медианных значений
test [ «Fare»] = test [ «Fare»].fillna (test [ «Fare»].median ())
# Возместим отсутствующие данные о возрасте с помощью медианных значений
test [ «Age»] = test [ «Age»].fillna (test [ «Age»].median ())
# Предварительная обработка
test_encoded_sex = preprocessing.LabelEncoder () test.Sex = test_encoded_sex.fit_transform (test.Sex)
# Извлечем необходимые признаки Pclass, Sex, Age, и Fare из тестового набора данных:
test_features = test [[ «Pclass,» «Sex,» «Age,» «Fare»]].values
print (‘These are the features: \ n’)
print (test_features)
# Составим прогноз, используя тестовый набор данных, и выведем результат
my_prediction = my_tree_one.predict (test_features)
print (‘This is the prediction: \ n’)
print (my_prediction)
# Выведем данные в две колонки: PassengerId и прогноз выживания
PassengerId =np.array (test [ «PassengerId»]). astype (int) my_solution = pd.DataFrame (my_prediction, PassengerId, columns = [ «Survived»])
print (‘This is the solution in toto: \ n’)
print (my_solution)
# Проверим, что у нас 418 строк данных
print (‘This is the solution shape: \ n’)
print (my_solution.shape)
# Записать результаты в. CSV-файл my_solution.csv
my_solution.to_csv (“my_solution_one.csv,” index_label = [“PassengerId”])
А вот и результат:
These are the features:
[[3. 1. 34.5 7.8292]
[3. 0. 47. 7.]
[2. 1. 62. 9.6875] …,
[3. 1. 38.5 7.25]
[3. 1. 27. 8.05]
[3. 1. 27. 22.3583]]
This is the prediction:
[0011100010001111011001101011100010100001010110001110111000110001001001100010010110000011111110001110100010000000111011011010010100100100100000000110101001001101111101100001010110110010101000001010100001010000101101001010101110010001001001111110001010100000001000110000000010110000011010001010100010000000110110010011000000011010001011000001000101000110001010010111100010010011000100010100000110010100101000001111001000]
This is the solution in toto:
Survived
892 0
893 0
894 1
895 1
896 1
897 0
898 0
899 0
900 1
901 0
902 0
903 0
904 1
905 1
906 1
907 1
908 0
909 1
910 1
911 0
912 0
913 1
914 1
915 0
916 1
917 0
918 1
919 1
920 1
921 0
…..
1280 0
1281 0
1282 0
1283 1
1284 1
1285 0
1286 0
1287 1
1288 0
1289 1
1290 0
1291 0
1292 1
1293 0
1294 1
1295 0
1296 0
1297 0
1298 0
1299 0
1300 1
1301 1
1302 1
1303 1
1304 0
1305 0
1306 1
1307 0
1308 0
1309 0
[418 rows x 1 columns]
This is the solution shape:
(418, 1)
Новая колонка с информацией о выживших содержит прогностические данные о 418 пассажирах из тестового массива. Можем сохранить полученные результаты в. CSV-файле под названием my_solution_one.csv, загрузить файл на DataCamp и выяснить, что точность наших прогнозов составляет 97 %. Ура! Мы только что обучили машину. И, когда кто-то говорит, что пользовался «искусственным интеллектом для принятия решения», обычно это означает «пользовался машинным обучением» и сделал примерно то же, что и мы сейчас.
Читать дальшеИнтервал:
Закладка:


![Джон Будро - Реинжиниринг бизнеса [Как грамотно внедрить автоматизацию и искусственный интеллект] [litres]](/books/1078415/dzhon-budro-reinzhiniring-biznesa-kak-gramotno-vned.webp)






