Мередит Бруссард - Искусственный интеллект [Пределы возможного] [litres]
![Мередит Бруссард - Искусственный интеллект [Пределы возможного] [litres]](/books/1073206/meredit-brussard-iskusstvennyj-intellekt-predely.webp "Обложка книги")
- Название:Искусственный интеллект [Пределы возможного] [litres]
- Автор:
- Жанр:
- Издательство:Литагент Альпина
- Год:2020
- Город:Москва
- ISBN:978-5-0013-9230-9
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Мередит Бруссард - Искусственный интеллект [Пределы возможного] [litres] краткое содержание
Всеобщий энтузиазм по поводу применения компьютерных технологий, по ее убеждению, уже привел к огромному количеству недоработанных решений в области проектирования цифровых систем. Выступая против техношовинизма и социальных иллюзий о спасительной роли технологий, Бруссард отправляется в путешествие по компьютерному миру: рискуя жизнью, садится за руль экспериментального автомобиля с автопилотом; задействует искусственный интеллект, чтобы выяснить, почему студенты не могут сдать стандартизованные тесты; использует машинное обучение, подсчитывая вероятность выживания пассажиров «Титаника»; как дата-журналист создает программу для поиска махинаций при финансировании кандидатов в президенты США.
Только понимая пределы компьютерных технологий, утверждает Бруссард, мы сможем распорядиться ими так, чтобы сделать мир лучше.
Искусственный интеллект [Пределы возможного] [litres] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Библиотека pandas, которую мы также будем использовать, имеет контейнер DataFrame, который «вмещает» набор данных. Такой тип пакета также называют объектом , как в о бъектно-ориентированном программировании. Объект – это такой же общий термин в программировании, как и в обычной жизни. В программировании объект – концептуальная обертка небольшого набора данных, переменных и кода. Таким образом, маркер объект становится для нас первой точкой опоры. Нам необходимо представить наш набор битов как нечто упорядоченное, о чем можно размышлять и говорить.
Во-первых, разделим наш набор данных пополам: на данные для обучения и на тестовые данные. Мы разработаем и обучим модель на данных для обучения и затем проверим на тестовом наборе. Помните, какой из двух ИИ тут работает – общий или слабый? Слабый. Итак, начнем:
import pandas as pd
import numpy as np
from sklearn import tree, preprocessing
Мы только что импортировали необходимые нам библиотеки. Каждой библиотеке мы дали собственные названия – pd для pandas, np для numpy. Теперь у нас есть доступ ко всем функциям обеих библиотек, и мы можем решить, какие из них нам нужны. Из библиотеки scikit-learn мы возьмем только две: первая называется tree , вторая – preprocessing .
Затем импортируем данные из файла. CSV (comma-separated values), который также можно найти в интернете. В частности, нужный нам. CSV-файл находится на сервере Web Services (AWS), принадлежащем Amazon. Нам это известно потому, что ссылка файла (которая начинается с http://) выглядит как s3.amazonaws.com. Файл. CSV представляет собой структурированные данные, где каждая колонка отделена запятой. Мы скачаем с AWS два файла с данными о «Титанике» – обучающий и тестовый, и они оба будут в формате. CSV. Импортируем их:
train_url =
« http://s3.amazonaws.com/assets.datacamp.com/course/Kaggle/train.csv »
train = pd.read_csv (train_url)
test_url = « http://s3.amazonaws.com/assets.datacamp.com/course/Kaggle/test.csv »
test = pd.read_csv (test_url)
pd.read_csv () означает «Пожалуйста, выполни функцию read_csv (), которая обитает в библиотеке pd (pandas)». Фактически мы только что создали DataFrame (структуру данных) и обратились к одной из встроенных функций. Итак, теперь данные импортированы в виде двух наборов – обучающего и тестового . Мы используем данные переменной train, чтобы создать модель, и затем при помощи переменной test протестируем ее точность.
Посмотрим, что в заголовках первых строк обучающего набора данных:
print (train.head ())
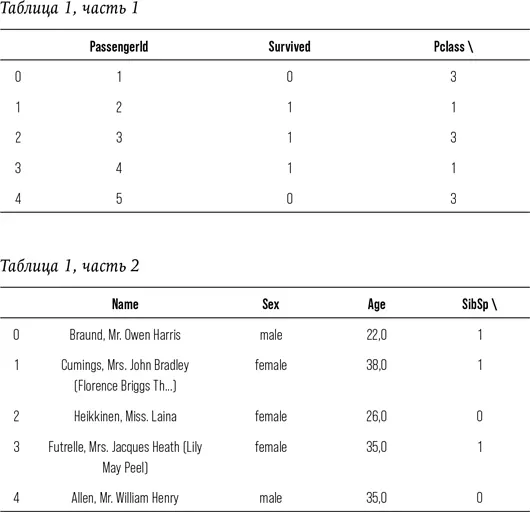
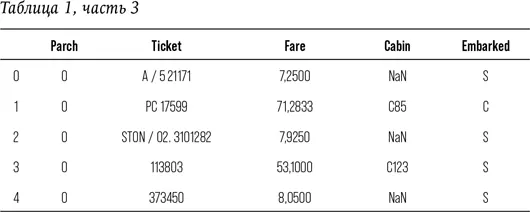
Итак, перед нами данные в 12 колонках: PassengerId, Pclass, Name, Sex, Age, SibSp, Parch, Ticket, Fare, Cabin, и Embarked. Что же это все означает?
Чтобы ответить на этот вопрос, нам понадобится словарь данных, который обычно имеется в каждом пакете данных. Заглянув в него, мы выясняем:
Pclass = пассажирский класс (1 = 1-й; 2 = 2-й; 3 = 3-й)
Survived = выжил (0 = нет; 1 = да)
Name = имя
Sex = пол
Age = возраст (в годах жизни; выражен дробью, если возраст меньше единицы (1), если данные приблизительны, они выражены в виде хх.5)
SibSp = количество родственников / супругов на борту
Parch = количество родителей / детей на борту
Ticket = номер билета
Fare = пассажирский тариф (до 1970-го считались в британских фунтах)
Cabin = номер каюты
Embarked = в каком порту сел (а) на борт корабля (C = Чербург; Q = Квинстаун; S = Саутгемптон)
В большинстве колонок есть информация, в иных – нет. Так, например, у пассажира с идентификатором 1, мистера Оуэна Харриса Брода, в графе «Номер каюты» зафиксировано значение NaN, что означает «нечисленное выражение». NaN также не равняется нулю, поскольку 0 – это число. Таким образом, NaN подразумевает, что для этой переменной отсутствует значение. В обычной жизни разница может быть несущественной, однако она принципиально важна для компьютерных вычислений. Вспомните, насколько точность важна для языка математики. Например, значение NULL – пустое множество, оно не синонимично NaN или нулю.
Посмотрим на первые строки тестового пакета данных:
print (test.head ())
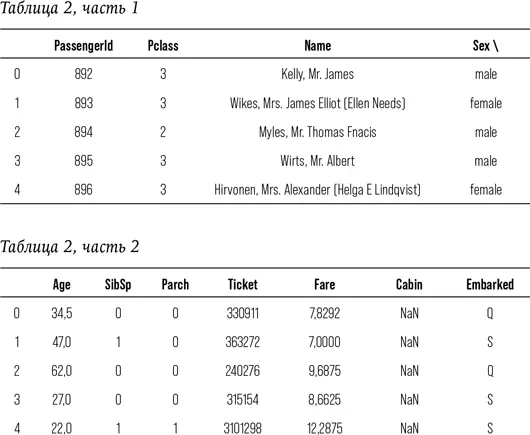
Как мы видим, в пакете тестовых данных все те же графы, что и в обучающем , с той лишь разницей, что нет информации о выживших. Хорошо! Наша задача заключается в том, чтобы создать в тестовом пакете колонку Survived («Выжил»), в которой будут содержаться прогностические данные о каждом пассажире. (Конечно, кому-то уже может быть известен результат, но, если бы у нас на руках уже были ответы, это не было бы похоже на упражнение, не так ли?)
Итак, теперь нам предстоит запустить на обучающем наборе сводную статистическую обработку – это позволит лучше понять имеющуюся информацию. Интервьюирование данных – так мы это называем в дата-журналистике. По сути, мы «опрашиваем» данные так же, как опрашивали бы человека, у которого есть имя, возраст, собственная история. В свою очередь, у пакета с данными есть размер и набор колонок. Выяснение среднего значения колонки с данными напоминает ситуацию, в которой мы попросили бы человека написать его фамилию.
Ближе познакомиться с нашими данными мы можем при помощи функции под названием describe – она собирает сводные данные и формирует их в удобную таблицу:
train.describe ()
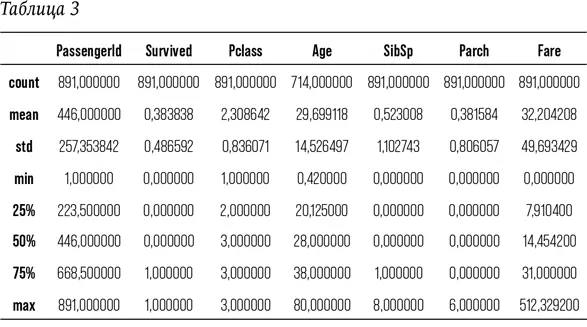
В пакете тренировочных данных содержится 891 запись. В 714 из них содержатся данные о возрасте пассажира. Согласно имеющимся у нас данным, средний возраст пассажира – 29,699118 лет; обычный человек сказал бы, что средний возраст пассажира составляет около 30.
Некоторые представленные данные требуют дополнительного пояснения: минимальное значение в колонке Survived составляет 0, максимальное – 1. Другими словами, это булевы значения: либо кто-то выжил (1), либо нет (0). Таким образом мы можем посчитать среднее значение – 0,38. Мы также можем посчитать среднее значение Pclass, пассажирского класса. Также цены билетов для 1-го, 2-го и 3-го класса. Здесь среднее значение не означает буквально, что кто-то путешествовал классом 2,308.
Выяснив кое-что о данных, которыми мы располагаем, обратимся к анализу. Посчитаем прежде всего количество пассажиров: для этого мы можем воспользоваться функцией value_counts. Она покажет, каково количество значений переменных для каждой категории в колонках. Иначе говоря, мы выясним, сколько пассажиров путешествовало каждым классом. Выясним:
Читать дальшеИнтервал:
Закладка:


![Джон Будро - Реинжиниринг бизнеса [Как грамотно внедрить автоматизацию и искусственный интеллект] [litres]](/books/1078415/dzhon-budro-reinzhiniring-biznesa-kak-gramotno-vned.webp)






