Нихиль Будума - Основы глубокого обучения

- Название:Основы глубокого обучения
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Нихиль Будума - Основы глубокого обучения краткое содержание
Основы глубокого обучения - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
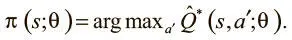
Можно также прибегнуть к техникам семплирования, о которых мы говорили выше, для выработки стохастической стратегии, которая порой отклоняется от рекомендаций Q-функции для варьирования соотношения исследования и использования.
DQN и марковское предположение
DQN — тоже марковский процесс принятия решений, который опирается на марковское предположение , что следующее состояние s_i + 1 зависит только от текущего s_i и действия a_i, а не от какого-либо предыдущего состояния или действия. Это несправедливо во многих средах, где состояние игры не может быть отражено в едином кадре. Например, в пинг-понге скорость шарика (важный фактор успеха) не может быть получена по одному кадру. Марковское предположение делает моделирование принятия решений гораздо проще и надежнее, но часто ценой мощности модели.
Решение проблемы марковского предположения в DQN
DQN решает эту проблему обращением к истории состояний . Вместо обработки одного кадра как игрового состояния DQN считает текущим состоянием четыре последних кадра, что позволяет ей использовать информацию, зависимую от времени. Это своего рода инженерная уловка, и в конце главы мы рассмотрим более эффективные методы работы с последовательностью состояний.
Игра в Breakout при помощи DQN
Сведем воедино всё, что мы узнали в этой главе, и займемся реализацией DQN для игры в Breakout. Начнем с определения нашего DQNAgent.
# DQNAgent
class DQNAgent(object):
def __init__(self, session, num_actions,
learning_rate=1e-3, history_length=4,
screen_height=84, screen_width=84,
gamma=0.98):
self.session = session
self.num_actions = num_actions
self.learning_rate = learning_rate
self.history_length = history_length
self.screen_height = screen_height
self.screen_width = screen_width
self.gamma = gamma
self.build_prediction_network()
self.build_target_network()
self.build_training()
def build_prediction_network(self):
with tf.variable_scope(‘pred_network'):
self.s_t = tf.placeholder(‘float32', shape=[
None,
self.history_length,
self.screen_height,
self.screen_width],
name='state')
self.conv_0 = slim.conv2d(self.s_t, 32, 8, 4,
scope='conv_0')
self.conv_1 = slim.conv2d(self.conv_0, 64, 4, 2,
scope='conv_1')
self.conv_2 = slim.conv2d(self.conv_1, 64, 3, 1,
scope='conv_2')
shape = self.conv_2.get_shape(). as_list()
self.flattened = tf.reshape(
self.conv_2, [-1, shape[1]*shape[2]*shape[3]])
self.fc_0 = slim.fully_connected(self.flattened,
512, scope='fc_0')
self.q_t = slim.fully_connected(
self.fc_0, self.num_actions, activation_fn=None,
scope='q_values')
self.q_action = tf.argmax(self.q_t, dimension=1)
def build_target_network(self):
with tf.variable_scope(‘target_network'):
self.target_s_t = tf.placeholder(‘float32',
shape=[None, self.history_length,
self.screen_height, self.screen_width],
name='state')
self.target_conv_0 = slim.conv2d(
self.target_s_t, 32, 8, 4, scope='conv_0')
self.target_conv_1 = slim.conv2d(
self.target_conv_0, 64, 4, 2, scope='conv_1')
self.target_conv_2 = slim.conv2d(
self.target_conv_1, 64, 3, 1, scope='conv_2')
shape = self.conv_2.get_shape(). as_list()
self.target_flattened = tf.reshape(
self.target_conv_2, [-1,
shape[1]*shape[2]*shape[3]])
self.target_fc_0 = slim.fully_connected(
self.target_flattened, 512, scope='fc_0')
self.target_q = slim.fully_connected(
self.target_fc_0, self.num_actions,
activation_fn=None, scope='q_values')
def update_target_q_weights(self):
pred_vars = tf.get_collection(
tf.GraphKeys.GLOBAL_VARIABLES, scope=
‘pred_network')
target_vars = tf.get_collection(
tf.GraphKeys.GLOBAL_VARIABLES, scope=
‘target_network')
for target_var, pred_var in zip(target_vars, pred_vars):
weight_input = tf.placeholder(‘float32',
name='weight')
target_var.assign(weight_input). eval(
{weight_input: pred_var.eval()})
def build_training(self):
self.target_q_t = tf.placeholder(‘float32', [None],
name='target_q_t')
self.action = tf.placeholder(‘int64', [None],
name='action')
action_one_hot = tf.one_hot(
self.action, self.num_actions, 1.0, 0.0,
name='action_one_hot')
q_of_action = tf.reduce_sum(
self.q_t * action_one_hot, reduction_indices=1,
name='q_of_action')
self.delta = tf.square((self.target_q_t — q_of_action))
self.loss = tf.reduce_mean(self.delta, name='loss')
self.optimizer = tf.train.AdamOptimizer(
learning_rate=self.learning_rate)
self.train_step = self.optimizer.minimize(self.loss)
def sample_action_from_distribution(self,
action_distribution, epsilon_percentage):
# Choose an action based on the action probability
# distribution (Выбираем действие на основе распределения вероятностей действия)
action = epsilon_greedy_action_annealed(
action_distribution, epsilon_percentage)
return action
def predict_action(self, state, epsilon_percentage):
action_distribution = self.session.run(
self.q_t, feed_dict={self.s_t: [state]})[0]
action = self.sample_action_from_distribution(
action_distribution, epsilon_percentage)
return action
def process_state_into_stacked_frames(self, frame,
past_frames, past_state=None):
full_state = np.zeros(
(self.history_length, self.screen_width,
self.screen_height))
if past_state is not None:
for i in range(len(past_state)-1):
full_state[i,] = past_state[i+1,]
full_state[-1,] = imresize(to_grayscale(frame),
(self.screen_width,
self.screen_height))
/255.0
else:
all_frames = past_frames + [frame]
for i, frame_f in enumerate(all_frames):
full_state[i,] = imresize(
to_grayscale(frame_f), (self.screen_width,
self.screen_height))/255.0
full_state = full_state.astype(‘float32')
return full_state
Здесь происходит много интересного, так что разберем это подробнее.
Создание архитектуры
Мы создали две Q-сети: предсказательную и целевую. Определение их архитектуры одинаково, поскольку это, по сути, одна сеть, но у второго варианта есть задержка в обновлении параметров. Поскольку мы учимся играть в Breakout по чистому пиксельному вводу, наше состояние игры — массив пикселей.
Пропускаем это изображение через три сверточных слоя, а затем через два полносвязных, получая на выходе Q-значения для каждого из потенциальных действий.
Занесение кадров в стек
Вы, возможно, заметили, что входные данные состояния имеют размер [None, self.history_length, self.screen_height, self.screen_width]. Для моделирования и включения чувствительных ко времени переменных состояния, таких как скорость, DQN использует не одно изображение, а группу последовательных, которая называется историей . Каждая картинка рассматривается как отдельный канал. Мы создаем объединяемые изображения при помощи вспомогательной функции process_state_into_stacked_frames(self, frame, past_frames, past_state=None).
Задание обучающих операций
Наша функция потерь выводится из выражения цели, приведенного выше в этой главе:

Мы хотим, чтобы предсказательная сеть равнялась целевой плюс выгода на текущем шаге. Это можно выразить в чистом коде TensorFlow в виде разницы между выводами предсказательной и целевой сетей. Этот градиент мы используем для обновления и обучения предсказательной сети с помощью AdamOptimizer.
Обновление целевой Q-сети
Чтобы гарантировать стабильную среду обучения, мы обновляем целевую Q-сеть через каждые четыре пакета. Правило обновления довольно простое: мы приравниваем ее веса к весам предсказательной сети. Для этого используется функция update_target_q_network(self). Можно применить tf.get_collection() для получения переменных областей действия предсказательной и целевой сетей. Мы можем пройти в цикле по этим переменным и запустить операцию tf.assign() для приравнивания весов целевой Q-сети к весам предсказательной.
Реализация повторения опыта
Мы уже говорили, что повторение опыта может помочь устранить корреляцию обновлений градиентных пакетов для повышения качества Q-обучения и выработанной на его основе стратегии. Рассмотрим кратко простой случай реализации повторения опыта. Задействуем метод add_episode(self, episode), который берет весь эпизод (объект EpisodeHistory) и добавляет его в ExperienceReplayTable. Затем он контролирует переполнение таблицы и удаляет оттуда самые старые значения опыта.
Читать дальшеИнтервал:
Закладка:









