Нихиль Будума - Основы глубокого обучения

- Название:Основы глубокого обучения
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Нихиль Будума - Основы глубокого обучения краткое содержание
Основы глубокого обучения - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
def epsilon_greedy_action_annealed(action_distribution,
percentage,
epsilon_start=1.0,
epsilon_end=1e-2):
annealed_epsilon = epsilon_start*(1.0-percentage) + epsilon_end*percentage
if random.random() < annealed_epsilon:
return np.argmax(np.random.random(
action_distribution.shape))
else:
return np.argmax(action_distribution)
Изучение стратегии и ценности
* * *
Мы определили архитектуру обучения с подкреплением, поговорили о дисконтировании будущей выгоды и рассмотрели компромиссы использования и исследования. Но пока мы не упоминали о том, как собираемся научить агента максимизировать выгоду.
Подходы к вопросу делятся на две большие категории: изучение стратегии и изучение ценности. В первом случае мы непосредственно обучаем стратегии, которая доводит выгоду до максимума. Во втором мы изучаем ценность каждой пары «состояние + действие». Для осваивающего велосипед изучение стратегии соответствует мыслям о том, как нажатие на правую педаль при падении влево восстановит равновесие. Если же действовать методом изучения ценности, нужно определять ценности для различных положений машины и действий, которые вы можете предпринять в этих условиях. Мы поговорим об обоих подходах, а начнем с изучения стратегии.
Изучение стратегии при помощи градиента по стратегиям
В обычном освоении навыков с учителем можно использовать стохастический градиентный спуск для обновления параметров и минимизации потерь, вычисленных на основе выходных данных сети и правильной метки. Оптимизируем выражение:
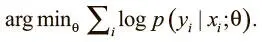
В обучении с подкреплением правильной метки нет — только сигналы вознаграждения. Но и здесь можно применить стохастический градиентный спуск для оптимизации весов, использовав градиенты по стратегиям [105]. Мы можем воспользоваться действиями, которые совершает агент, и выгодами, связанными с ними, чтобы веса модели принимали действия, которые приводят к высоким наградам, и отвергали ведущие к негативному подкреплению. Оптимизируем выражение:
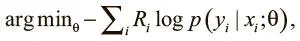
где y i — действие агента на шаге t , а R i — дисконтированная будущая выгода. Мы умножаем потери на значение выгоды, так что, если модель выбирает действие, ведущее к отрицательному результату, то потери возрастают. Если модель продолжает упорствовать, она получит еще больший штраф, ведь мы учитываем вероятность того, что она выберет это действие. Определив функцию потерь, мы можем применить стохастический градиентный спуск для их минимизации и обучения грамотной стратегии.
Тележка с шестом и градиенты по стратегиям
* * *
Сейчас мы реализуем агент градиента по стратегиям для решения проблемы тележки с шестом — классической задачи в обучении с подкреплением. Мы воспользуемся средой из OpenAi Gym, созданной как раз для этого задания.
OpenAI Gym
OpenAI Gym — инструментальная библиотека Python для разработки агентов с подкреплением. Она предлагает простой в использовании интерфейс для взаимодействия с рядом сред и содержит более сотни открытых реализаций самых распространенных сред для обучения с подкреплением. OpenAI Gym ускоряет разработку агентов обучения с подкреплением, беря на себя всю работу по симуляции среды и позволяя исследователям сосредоточиться на агенте и алгоритмах. Еще одно преимущество OpenAI Gym в том, что исследователи могут сравнивать свои результаты с другими, поскольку все получают одну и ту же стандартизированную среду для решения задачи. Мы воспользуемся задачей тележки с шестом для создания агента, который сможет легко взаимодействовать с этой средой.
Создание агента
Чтобы создать агента, который сможет взаимодействовать со средой OpenAI, определим класс PGAgent, который будет содержать архитектуру модели, ее веса и гиперпараметры:
class PGAgent(object):
def __init__(self, session, state_size, num_actions,
hidden_size, learning_rate=1e-3,
explore_exploit_setting=
‘epsilon_greedy_annealed_1.0->0.001'):
self.session = session
self.state_size = state_size
self.num_actions = num_actions
self.hidden_size = hidden_size
self.learning_rate = learning_rate
self.explore_exploit_setting = explore_exploit_setting
self.build_model()
self.build_training()
def build_model(self):
with tf.variable_scope(‘pg-model'):
self.state = tf.placeholder(
shape=[None, self.state_size],
dtype=tf.float32)
self.h0 = slim.fully_connected(self.state,
self.hidden_size)
self.h1 = slim.fully_connected(self.h0,
self.hidden_size)
self.output = slim.fully_connected(
self.h1, self.num_actions,
activation_fn=tf.nn.softmax)
# self.output = slim.fully_connected(self.h1,
self.num_actions)
def build_training(self):
self.action_input = tf.placeholder(tf.int32,
shape=[None])
self.reward_input = tf.placeholder(tf.float32,
shape=[None])
# Select the logits related to the action taken (Выбираем логиты, относящиеся к данному действию)
self.output_index_for_actions = (tf.range(
0, tf.shape(self.output)[0]) *
tf.shape(self.output)[1]) +
self.action_input
self.logits_for_actions = tf.gather(
tf.reshape(self.output, [-1]),
self.output_index_for_actions)
self.loss = — \
tf.reduce_mean(tf.log(self.logits_for_actions) *
self.reward_input)
self.optimizer = tf.train.AdamOptimizer(
learning_rate=self.learning_rate)
self.train_step = self.optimizer.minimize(self.loss)
def sample_action_from_distribution(
self, action_distribution,
epsilon_percentage):
# Choose an action based on the action probability
# distribution and an explore vs exploit (Выбираем действие на основании распределения вероятностей действий и соотношения исследования и использования)
if self.explore_exploit_setting == ‘greedy':
action = greedy_action(action_distribution)
elif self.explore_exploit_setting == ‘epsilon_greedy_0.05':
action = epsilon_greedy_action(action_distribution, 0.05)
elif self.explore_exploit_setting == ‘epsilon_greedy_0.25':
action = epsilon_greedy_action(action_distribution, 0.25)
elif self.explore_exploit_setting == ‘epsilon_greedy_0.50':
action = epsilon_greedy_action(action_distribution, 0.50)
elif self.explore_exploit_setting == ‘epsilon_greedy_0.90':
action = epsilon_greedy_action(action_distribution, 0.90)
elif self.explore_exploit_setting == ‘epsilon_greedy_annealed_1.0->0.001':
action = epsilon_greedy_action_annealed(
action_distribution, epsilon_percentage, 1.0, 0.001)
elif self.explore_exploit_setting == ‘epsilon_greedy_annealed_0.5->0.001':
action = epsilon_greedy_action_annealed(
action_distribution, epsilon_percentage, 0.5, 0.001)
elif self.explore_exploit_setting == ‘epsilon_greedy_annealed_0.25->0.001':
action = epsilon_greedy_action_annealed(
action_distribution, epsilon_percentage, 0.25, 0.001)
return action
def predict_action(self, state, epsilon_percentage):
action_distribution = self.session.run(
self.output, feed_dict={self.state: [state]})[0]
action = self.sample_action_from_distribution(
action_distribution, epsilon_percentage)
return action
Создание модели и оптимизатора
Разберем некоторые важные функции. В build_model() мы определяем архитектуру модели как трехслойную нейронную сеть. Модель возвращает слой из трех узлов, каждый из которых представляет распределение вероятностей действия. В build_training() мы реализуем оптимизатор градиента по стратегии. Выражаем целевые потери так, как уже говорили, умножая предсказание вероятности действия на вознаграждение за него и суммируем все результаты, формируя мини-пакет. Определив цели, можно использовать tf.AdamOptimizer, который обновит веса в соответствии с градиентом для минимизации потерь.
Семплирование действий
Интервал:
Закладка:









