Нихиль Будума - Основы глубокого обучения

- Название:Основы глубокого обучения
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Нихиль Будума - Основы глубокого обучения краткое содержание
Основы глубокого обучения - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
В этой главе мы рассмотрели проблемы переднего края науки о глубоком обучении — работу с NTM и DNC, завершив реализацией модели, которая может решать задачу понимания чтения.
В последней главе мы начнем изучать иную сферу: обучение с подкреплением. Мы познакомимся с новым классом задач и подготовим алгоритмические основы решения при помощи уже созданных нами инструментов глубокого обучения.
Глава 9. Глубокое обучение с подкреплением
* * *
[102]
В этой главе мы рассмотрим обучение с подкреплением — раздел машинного обучения, требующего взаимодействия и обратной связи. Это необходимо для создания агентов, которые будут не просто воспринимать и интерпретировать мир, но и взаимодействовать с ним. Мы расскажем, как внедрить глубокие нейронные сети в структуру обучения с подкреплением, и обсудим последние достижения и улучшения в этой области.
Глубокое обучение с подкреплением и игры Atari
Применение глубоких нейронных сетей к обучению с подкреплением стало важным прорывом в 2014 году, когда лондонский стартап DeepMind поразил специалистов по машинному обучению, представив глубокую нейронную сеть, которая справлялась с играми компании Atari лучше, чем люди. Эта сеть, получившая название Deep Q-Network (DQN), стала первым масштабным успешным применением обучения с подкреплением с глубокими нейронными сетями. Она оказалась особенно примечательной, потому что одна и та же архитектура без изменений смогла освоить 49 разных игр, различающихся правилами, целями и стратегиями. Создатели DeepMind свели воедино многие традиционные идеи обучения с подкреплением, разработав и несколько новаторских методов, которые оказались ключевыми для успеха. В этой главе мы рассмотрим реализацию DQN, как она представлена в публикации в журнале Nature под названием «Управление на уровне человека с помощью глубокого обучения с подкреплением» [103]. Но сначала подробнее рассмотрим суть метода (рис. 9.1).
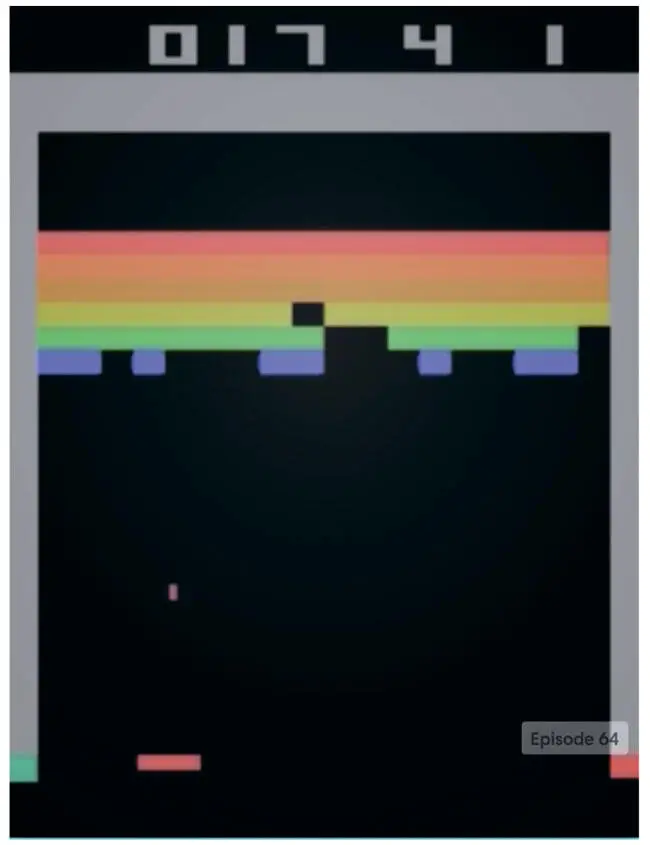
Рис. 9.1. Агент глубокого обучения с подкреплением играет в Breakout. Изображение из агента DQN OpenAI Gym [104], который будет реализован в этой главе
Что такое обучение с подкреплением?
По сути, это обучение путем взаимодействия со средой. Процесс включает агента, среду и сигнал вознаграждения. Агент решает совершить действие в среде и за это получает соответствующее вознаграждение. Способ, которым он выбирает, что совершить, называется стратегией . Агент хочет увеличить вознаграждение, так что он должен научиться оптимальной стратегии взаимодействия со средой (рис. 9.2).
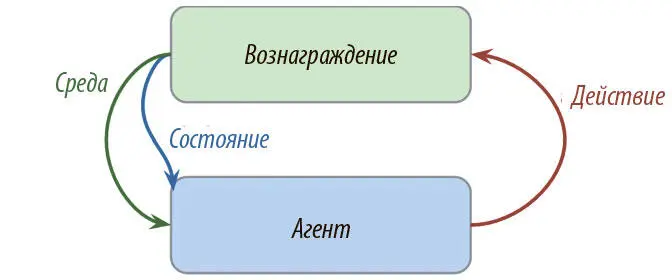
Рис. 9.2. Схема обучения с подкреплением
Обучение с подкреплением отличается от остальных типов, о которых мы говорили ранее. При традиционном подходе с учителем у нас есть данные и метки, а задача — предсказывать последние на основании данных. В освоении навыков без учителя у нас есть только данные, а задача — поиск структур в их основе. В обучении же с подкреплением нет ни данных, ни меток. Сигнал поступает от вознаграждений, получаемых от среды.
Обучение с подкреплением сейчас интересно многим причастным к работе над искусственным интеллектом, поскольку это общая структура создания разумных агентов. Агент учится взаимодействовать со средой, чтобы увеличить общее вознаграждение. Это лучше соответствует модели развития человека. Да, мы можем построить очень хорошую и точную модель классификации изображений кошек и собак, обучив ее на тысячах рисунков. Но такой подход не используется в начальных школах. Люди взаимодействуют со средой, усваивая представления о мире, на основе которых смогут позже принимать решения. Практическое применение обучения с подкреплением обнаруживаются во многих передовых технологиях: автомобилях без водителя, роботизированном управлении двигателем, играх, контроле кондиционирования воздуха, оптимизации рекламы и стратегиях торговли на фондовом рынке.
В качестве иллюстрации рассмотрим простой пример для решения проблемы управления — балансировку шеста. В задаче есть тележка с шестом, который прикреплен к нему на шарнире и может раскачиваться. Есть также агент, который управляет тележкой, — двигает ее влево или вправо. Есть среда, которая вознаграждает агента, если шест направлен вверх, и штрафует, если тот падает вниз (рис. 9.3).
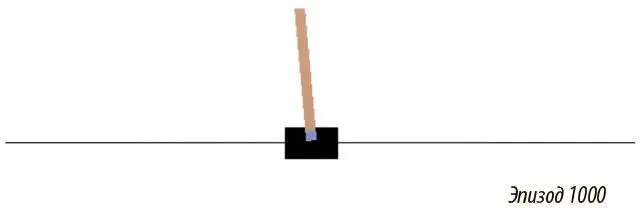
Рис. 9.3. Простой агент обучения с подкреплением, балансирующий шест. Изображение из агента OpenAI Gym Policy Gradient, который будет создан в этой главе
Марковские процессы принятия решений (MDP)
* * *
В нашем примере с балансировкой шеста есть несколько важных элементов, которые можно формализовать как марковские процессы принятия решений (MDP). Вот они.
Состояние
У тележки есть ряд возможных положений на оси х . У шеста — ряд возможных углов.
Действие
Агент может совершить действие — сдвинуть тележку влево или вправо.
Переход состояний
Когда агент действует, среда меняется: тележка двигается, шест изменяет угол и скорость.
Вознаграждение
Если агент хорошо балансирует шест, он получает позитивное вознаграждение. Если шест падает, следует негативное подкрепление.
MDP определяется следующим:
• S , конечное множество возможных состояний;
• A , конечное множество действий;
• P ( r, s ′| s, a ), функция перехода между состояниями;
• R , функция вознаграждения.
MDP дают математическую структуру для моделирования принятия решений в заданной среде (рис. 9.4).
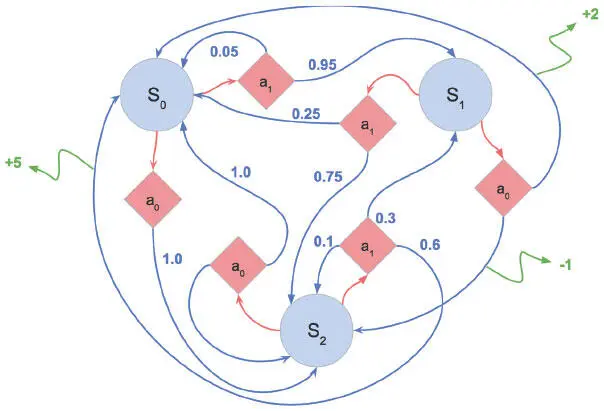
Рис. 9.4. Пример марковского процесса принятия решений. Голубые кружки обозначают состояния среды. Красные ромбы соответствуют возможным действиям. Стрелки от ромбов к кругам отображают переход из одного состояния в другое. Числа при них соответствуют вероятности действия. Числа в конце зеленых стрелок показывают вознаграждение, которое выдается агенту за выполнение соответствующего перехода
Когда агент совершает действие в структуре MDP, образуется эпизод . Он состоит из серии кортежей состояний, действий и вознаграждений. Эпизоды сменяются, пока среда не достигает конечного состояния: например, экрана Game Over в играх Atari или падения шеста в примере с тележкой и шестом. Следующее уравнение показывает все переменные эпизода:
Читать дальшеИнтервал:
Закладка:









