Нихиль Будума - Основы глубокого обучения

- Название:Основы глубокого обучения
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Нихиль Будума - Основы глубокого обучения краткое содержание
Основы глубокого обучения - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
empty_at = tf.TensorArray(tf.float32, N)
full_at = empty_at.scatter(free_list, out_of_location_at)
a_t = full_at.pack()
Последняя часть реализации, где необходимо введение циклов, — собственно цикл контроллера, который проходит по каждому шагу входной последовательности, обрабатывая ее. Поскольку векторизация работает только при поэлементном определении операций, цикл контроллера векторизовать нельзя. К счастью, TensorFlow снова дает нам возможность избежать циклов for в Python, что существенно отразилось бы на производительности; это метод символического цикла . Он работает так же, как большинство символических операций: вместо разворачивания настоящего цикла в граф определяется узел, который пройдет как цикл при выполнении самого графа.
Задать символический цикл можно при помощи tf.while_loop(cond, body, loop_vars). Аргумент loop_vars — список изначальных значений тензоров и/или их массивов, которые проходят по каждой итерации цикла; он может быть и вложенным. Два других аргумента — вызываемые объекты (функции или лямбда выражения), которые передаются в этот список переменных цикла при каждой итерации. Первый аргумент cond представляет условие цикла. Пока этот вызываемый объект возвращает значение true, цикл будет продолжать работу. Второй аргумент body — тело цикла, которое исполняется при каждой итерации. Этот вызываемый объект и отвечает за модификацию переменных цикла и возвращение их на следующей итерации. Такие перемены, однако, не должны затрагивать форму тензора, которая на каждой итерации остается неизменной. После выполнения цикла возвращается список его переменных с их значениями после последней итерации.
Чтобы лучше понять, как используются символические циклы, приведем простой пример. Допустим, нам дан вектор значений, и мы хотим получить их кумулятивную сумму. Это достигается с помощью tf.while_loop, как в следующем коде:
values = tf.random_normal([10])
index = tf.constant(0)
values_array = tf.TensorArray(tf.float32, 10)
cumsum_value = tf.constant(0.)
cumsum_array = tf.TensorArray(tf.float32, 10)
values_array = values_array.unpack(values)
def loop_body(index, values_array, cumsum_value, cumsum_array):
current_value = values_array.read(index)
cumsum_value += current_value
cumsum_array = cumsum_array.write(index, cumsum_value)
index += 1
return (index, values_array, cumsum_value, cumsum_array)
_, _, _, final_cumsum = tf.while_loop(
cond= lambda index, *_: index < 10,
body= loop_body,
loop_vars= (index, values_array, cumsum_value, cumsum_array)
)
cumsum_vector = final_cumsum.pack()
Сначала мы используем unpack(values) массива тензоров, чтобы распаковать значения тензора по первому измерению по массиву. В теле цикла мы получаем значение текущего индекса методом read(index) из массива. Затем высчитываем кумулятивную сумму и добавляем ее к массиву кумулятивной суммы методом write(index, value), который записывает заданное значение в массив на заданном индексе. Наконец, после полного выполнения цикла, мы получаем итоговый массив кумулятивной суммы и упаковываем его в тензор. Примерно так же реализуется цикл DNC по шагам входной последовательности.
Обучение DNC чтению и пониманию
Ранее в этой главе, когда мы говорили о нейронных н-граммах, мы упомянули, что ИИ в данном случае еще не может отвечать на вопросы по прочитанному тексту. Теперь мы достигли точки, когда можем построить систему, которая делает то же, что DNC, в применении к набору данных bAbI.
bAbI — синтетический набор данных, который состоит из 20 наборов историй, вопросов по ним и ответов. Любая группа данных представляет отдельную задачу, касающуюся рассуждений и выводов на основании текста. В той версии, которую будем использовать мы, для каждой задачи есть 10 тысяч вопросов для обучения и 1000 для тестирования. Например, следующая история (из которой адаптирован уже известный нам отрывок) взята из задачи «списки и наборы», в которой ответы на вопросы — списки или наборы предметов, упомянутых в истории:
1 Мэри взяла там молоко.
2 Мэри пошла в офис.
3 Что несет Мэри? молоко1
4 Мэри взяла там яблоко.
5 Сандра пошла в спальню.
6 Что несет Мэри? молоко, яблоко1 4
Этот пример взят непосредственно из набора данных. История описана в пронумерованных предложениях, начиная с 1. Каждый вопрос заканчивается вопросительным знаком, а слова, которые за ним следуют, — ответы. Если ответ состоит более из двух или более слов, те разделены запятыми. Числа за ответами — контрольные сигналы, указывающие на предложения, которые содержат слова из ответа.
Усложняя задачу, мы откажемся от контрольных сигналов, чтобы система научилась читать текст и сама находить ответы. В соответствии с исходной работой по DNC проведем предварительную обработку набора данных, убрав все числительные и знаки препинания, за исключением"?" и".", переведя все слова в нижний регистр, а все слова в ответе заменив дефисами "-" во входящей последовательности. Получим 159 уникальных слов и знаков (лексиконов) по всем заданиям. Преобразуем каждый лексикон в прямой унитарный вектор размера 159; никаких плотных векторных представлений, только слова. Наконец, мы сочетаем все 200 тысяч тренировочных вопросов для обучения модели на них в совокупности, при этом тестовые вопросы каждого задания отделяем друг от друга, чтобы далее проверять обученную модель на каждом задании отдельно. Весь этот процесс реализован в файле репозитория кода preprocess.py .
Мы случайным образом выбираем историю из закодированных обучающих данных, пропускаем ее через DNC на контроллер LSTM и получаем соответствующую выходную последовательность. Затем измеряем потери между выходной последовательностью и желаемой с помощью функции потерь мягкого максимума перекрестной энтропии, но только для шагов, которые содержат ответы. Все остальные игнорируются: мы назначаем вектору весов значения 1 на шагах с ответами и значения 0 в остальных местах. Этот процесс реализован в файле train_babi.py .
После того как модель обучена, тестируем ее работоспособность на оставшихся тестовых вопросах. Нашей метрикой будет процент вопросов, на которые модель не смогла ответить в рамках каждого задания. Ответ — слово с наибольшим значением функции мягкого максимума на выходе, то есть наиболее вероятное слово. Считается, что ответ верный, если все слова в нем правильные. Если модель не смогла ответить более чем на 5% вопросов в задании, считается, что она не справилась. Процедуру тестирования можно найти в файле test_babi.py .
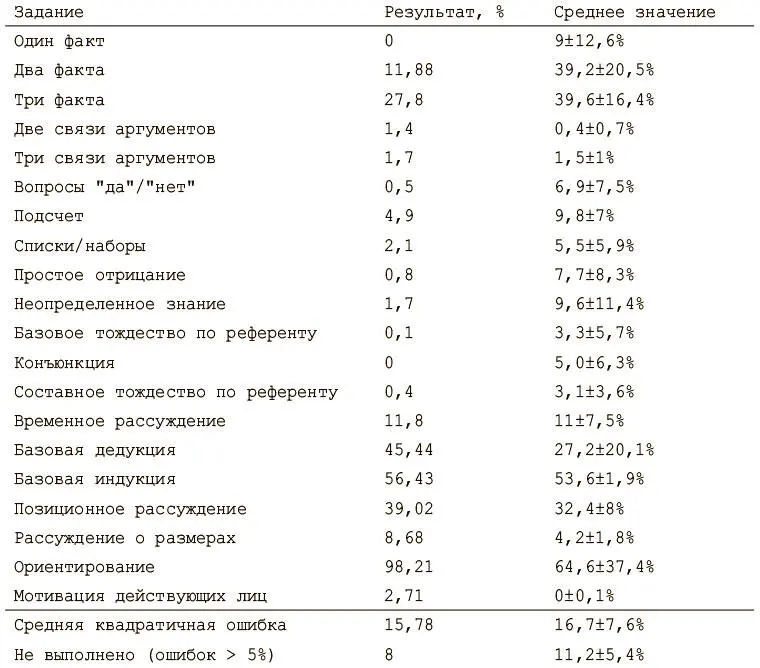
После обучения модели на примерно 500 тысяч итераций (это может занять очень много времени!) оказывается, что с большинством заданий она справилась очень хорошо. Но она плохо выполняет более сложные задачи, такими как ориентирование , где надо отвечать на вопросы о том, как попасть из одного места в другое. В нижеследующем отчете сравниваются результаты нашей модели со средними значениями из первой работы по DNC.
Резюме
Интервал:
Закладка:









