Нихиль Будума - Основы глубокого обучения

- Название:Основы глубокого обучения
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Нихиль Будума - Основы глубокого обучения краткое содержание
Основы глубокого обучения - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
A3C использует функцию преимущества вместо чистой дисконтированной будущей выгоды. При обучении стратегии мы хотим, чтобы агент получал штраф, выбирая действие, которое ведет к плохому подкреплению. A3C стремится к тому же, но критерием считает не вознаграждение, а преимущество, то есть разницу между предсказанным моделью и реальным качеством совершенного действия. Преимущество можно выразить так:
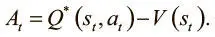
У A3C есть функция ценности, V(t), но она не выражает Q-функцию. Она оценивает преимущество, используя дисконтирование будущей выгоды как приближение Q-функции:
A t = R t − V ( s t ).
Три этих метода, как оказалось, обеспечивают A3C преимущество перед большинством аналогов в сфере глубокого обучения с подкреплением. Агенты A3C могут научиться играть в Atari Breakout меньше чем за 12 часов, а агентам DQN на это может потребоваться три-четыре дня.
Подкрепление без учителя и вспомогательное обучение (unsupervised reinforcement and auxiliary learning, unreal)
UNREAL — улучшение A3C, представленное в работе Макса Ядерберга и коллег «Обучение с подкреплением со вспомогательными заданиями без учителя» [111]. Эти авторы, как вы, наверное, уже догадались, тоже из DeepMind.
UNREAL решает проблему недостаточности вознаграждения. Обучение с подкреплением так сложно, поскольку агент просто получает вознаграждения, а определить, почему именно они увеличиваются или уменьшаются, сложно. Кроме того, мы должны обучить модель и хорошему представлению мира, и хорошей стратегии — только это обеспечит вознаграждение. Если же обратная связь окажется слабой, как в случае с недостаточными вознаграждениями, это будет особенно сложно.
UNREAL задается вопросом о том, что можно освоить без вознаграждений, и ставит себе целью обучиться полезному представлению мира без учителя. Для этого оно добавляет несколько вспомогательных задач без учителя к общей цели.
Первое задание связано с обучением агента тому, как его действия влияют на среду. Он получает задачу контролировать значения пикселов на экране. Чтобы выработать набор значений в следующем кадре, агент должен выполнить определенное действие в текущем. Так он узнает, как его действия влияют на окружающий мир. Это помогает научиться представлению мира, которое учитывает и его действия.
Второе задание связано с обучением агента UNREAL предсказанию вознаграждения. Он получает последовательность состояний и задачу предсказать значение следующего вознаграждения. Если агент способен верно назвать его, то, возможно, у него уже есть хорошая модель будущего состояния окружающей среды, что будет полезно при выработке стратегии.
После выполнения этих вспомогательных задач без учителя UNREAL оказывается способен в 10 раз быстрее, чем A3C, обучаться в среде игры Labyrynth. Для UNREAL особенно важно обучение хорошим представлениям мира и тому, как освоение навыков без учителя может помочь в условиях слабой обратной связи или при решении проблем обучения с низкими ресурсами, например в модели с подкреплением.
Резюме
В этой главе мы поговорили об основах обучения с подкреплением, включая марковские процессы принятия решений, максимальное дисконтирование будущих вознаграждений и соотношение исследования и использования. Также мы рассказали о подходах к глубокому обучению с подкреплением, в том числе градиентах по стратегиям и глубоких Q-сетях, и осветили последние улучшения DQN и новые разработки в сфере глубокого обучения с подкреплением.
Обучение с подкреплением необходимо для создания агентов, которые могут не только воспринимать и интерпретировать мир, но и предпринимать действия и взаимодействовать с ним. Глубокое обучение с подкреплением уже сделало большие шаги к этой цели, создав успешных агентов, которые умеют играть в игры Atari, безопасно водят автомобили, выгодно торгуют на бирже, управляют роботами и способны на многое другое.
Благодарности
Благодарим тех, кто помогал нам в работе над книгой. В первую очередь спасибо Мостафе Самиру и Сурье Бхупатираджу, которые внесли значительный вклад в главу 7и главу 8. Мы очень признательны Мохамеду (Хассану) Кане и Анише Аталье, которые создавали первые варианты образцов кода в репозитории Github для этой книги.
Книга не состоялась бы без постоянной поддержки и опыта нашего издателя Шеннона Катта. Мы признательны за комментарии рецензентам — Айзеку Хоудзу, Дэвиду Анджеевски и Аарону Шумахеру, которые дали нам ценные и глубокие замечания еще на этапе черновиков. Наконец, мы благодарим за поддержку и советы во время работы над чистовиком всех наших друзей и членов семьи: Джеффа Дина, Нитина Будуму, Венката Будуму, а также Уильяма и Джека.
Несколько слов об обложке
Животное на обложке «Основ глубокого обучения» — рыба-единорог (Lophotus capellei). Она относится к семейству лофотовых и живет в глубоких водах Атлантического и Тихого океанов. Рыбы скрываются от исследователей, и о них мало что известно. Но некоторые из пойманных экземпляров достигали в длину почти двух метров.
Многие животные на обложках издательства O’Reilly относятся к видам, находящимся под угрозой; все они важны для мира. Узнать, как им помочь, можно на animals.oreilly.com. Изображение на обложке выполнено Карен Монтгомери на основе черно-белой гравюры из книги Ричарда Лидеккера Royal Natural History.
Об авторе
Нихиль Будума— один из основателей и главный научный сотрудник Remedy, компании из Сан-Франциско, которая создает новую систему управляемой данными первичной медицинской помощи. Уже в 16 лет он руководил лабораторией по созданию новых лекарственных средств в Университете Сан-Хосе и разрабатывал новые недорогие методы обследования для районов с ограниченными ресурсами. К 19 годам он имел уже две золотые медали Международной олимпиады по биологии. Затем он учился в Массачусетском технологическом университете, где занимался разработкой масштабных систем данных для оказания медицинской помощи, поддержания психического здоровья и медицинских разработок. В MIT он основал Lean On Me — национальную некоммерческую организацию, предоставляющую анонимную текстовую горячую линию в кампусах колледжей и использующую данные для поддержания психического и физического здоровья. Сейчас Нихиль в свободное время инвестирует в компании в сфере материальных технологий и данных в рамках своего венчурного фонда Q Venture Partners и руководя командой анализа данных бейсбольной команды Milwaukee Brewers.
МИФ Бизнес
Все книги по бизнесу и маркетингу: mif.to/business mif.to/marketing
Читать дальшеИнтервал:
Закладка:









