Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/1150039/roman-zykov-roman-s-data-science-kak-monetizirova.webp "Обложка книги")
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Жанр:
- Издательство:Издательство Питер
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres] краткое содержание
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
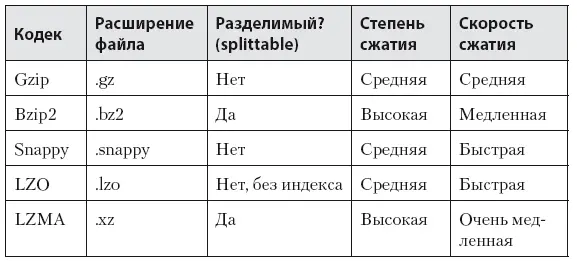
Второй способ – использование кодеков сжатия (табл. 6.2) [43]. Это очень актуально и эффективно работает в Hadoop и Spark. Сжатие данных убивает двух зайцев – мы уменьшаем объем занимаемого места на дисках и ускоряем работу с данными: они в разы быстрее гоняются по сети между серверами кластера и быстрее читаются с диска. Чудес не бывает – чем сильнее жмет кодек, тем больше ему нужно ресурсов процессора для сжатия данных.
Мы на своем кластере используем кодеки: gzip, bzip2 и lzma. Lzma имеет самую высокую компрессию и используется для архивируемых данных. Gzip используется для всех остальных данных, поступающих в кластер. От конкретного кодека сжатия зависит возможность «разрезания» (split) файла для операции Map без его распаковки. Как уже писалось ранее, для операции Map данные «нарезаются» на блоки размером не больше заданного в настройках Hadoop (block size). Если сжатый файл больше этого размера, то в случае разделимого кодека (splittable codec) его можно разрезать и распаковать по частям на разных нодах кластера параллельно. В противном случае придется распаковывать этот огромный файл целиком – а это уже будет гораздо медленнее.
Таблица 6.2. Сравнение кодеков сжатия
Мониторинг хранилищ данных
Пользователи вашей аналитической системы могут принимать очень важные решения на основе данных, поэтому важно обеспечить их надежными данными.
Однажды у меня произошел нехороший случай: в пятницу вечером я произвел изменения в системе пополнения данных в хранилище в Ozon.ru. И ушел в отпуск. Конечно, на выходных все упало. Ребята-аналитики получили в понедельник письмо от генерального директора на английском, которое начиналось словами: «I’m fed up…» (Я сыт по горло…). Они, конечно, нашли причину проблемы и исправили. Как следовало мне поступить? Во-первых, не делать никаких изменений в пятницу, тем более перед отпуском. Если бы я это сделал хотя бы в четверг, то в пятницу утром изменения «сломали» бы систему и у меня было бы время все исправить. Во-вторых, если бы была полноценная система мониторинга, то разработчики первыми получили бы сообщения о проблеме. У них была бы возможность предупредить пользователей до того, как те ее сами заметят.
Когда я проверял задачи по анализу данных или делал их сам, то периодически мучился вопросом: «А все ли в порядке с данными?» Иногда эти сомнения оправданны, и проблема действительно существует. Это заставляет нас первым шагом делать проверку. Но она не всегда бывает простой и может занять приличное время. Есть второй путь – автоматизация проверок данных и мониторинг. Вот об этом и поговорим.
Есть два параметра, которые нужно проверить:
• доступность всех данных, которые есть в источнике;
• целостность.
Доступность данных проверяется легче всего. Во-первых, проверяется дата последнего обновления, например файла или таблицы. А еще лучше воспользоваться полем с датой/временем – например датой и временем заказа. Во-вторых, можно посчитать и сравнить количество записей в хранилище данных и в источнике. Если есть поле с датой и временем, можно сделать такое сравнение по дням. Конечно, в момент проверки данные источника и хранилища будут расходиться, потому что всегда есть дельта времени изменения данных в источнике и отражения этих изменений в хранилище. Если вы уверены, что с данными все в порядке, можно опытным путем найти допустимые пороговые значения относительной разницы в процентах. Для одних данных это может быть полпроцента, для других – все пять. Этот тип проверки закроет 80 % проблем с данными в хранилище. Это как раз те 20 % усилий по Парето, которые дают 80 % результата. Методика недорогая, доступна всем и нравится мне своей простотой.
Второй параметр – целостность данных – проверить сложнее. Под целостностью я подразумеваю наличие в одной таблице тех данных, которые есть во второй. Простейший пример – есть две таблицы, одна с клиентами, вторая с заказами. В таблице с заказами есть поле «клиент». Целостность таблицы с заказами будет означать, что все клиенты из этой таблицы должны быть также и в таблице – справочнике клиентов. Если это соответствие не соблюдается, то при соединении (join) двух таблиц либо возникнут «битые» данные (если соединение было сделано с учетом этой особенности – left join, right join, full outer join), либо эти данные просто исчезнут и эти продажи выпадут из отчетов (если соединение сделано через inner join). Оба этих результата потенциально могут привести к неверным решениям. Хорошо бы это контролировать через независимые тесты, например проверять относительный объем продаж клиентов, которых нет в таблице с клиентами.
Личный опыт
Не надо бояться. Свое первое хранилище я стал собирать в 2004 году в Ozon.ru. Мне в работе очень помогло обучение «MS SQL Server» в «Софтлайне», когда я еще работал в StatSoft. Этот сертификат хранится у меня до сих пор. Я ничего практически не знал об этом, но знакомство с SQL Server и опора на здравый смысл сделали свое дело – я создал своего первого «паука», который закачивал данные в наспех собранное хранилище. Мне никто не помогал в этом, но никто и не мешал, что очень важно. Схема хранилища модифицировалась, но ее концепт, заложенный в самом начале, остался прежним. В Wikimart.ru я, работая два дня в неделю, собрал первую версию аналитической системы с полной внутренней веб-аналитикой всего за два месяца. Если вы хотите лучше узнать принципы построения хранилищ, рекомендую обратиться к трудам Ральфа Кимбалла – я в них почерпнул много полезного.
А теперь о сложностях. К моменту моего ухода из Ozon.ru расхождение данных о продажах в хранилище с бухгалтерией составляло 4–5 %. При этом бухгалтерия закрывала период в течение месяца, а данные в кубах аналитической системы были уже в первый день следующего месяца. После ухода из Ozon.ru я встречался с операционным директором «Связного» – целая небольшая команда пришла пообщаться со мной по поводу «строительства кубов». Они очень удивились тому, что я сделал весь основной движок в одиночку. Это не я такой крутой, это вопрос допустимой погрешности системы. Чем меньшего процента расхождения с бухгалтерией мы хотим достичь, тем сложнее его получить. Допустим, нужно уменьшить расхождение с 4 до 3 %. Это потребует большего вовлечения меня, найма одного-двух человек, усложнения системы, а следовательно, увеличения управленческой «энтропии». Если мы хотим продолжать дальше – спуститься до двух процентов, это потребует уже на порядок больше усилий. Каждое уменьшение будет требовать усложнения и удорожания по экспоненте. Но что мы теряем? Мы теряем гибкость, мы теряем маневренность. Не нужно молиться на нулевую погрешность, ее никогда не будет. Помните про правило Парето – 20 % усилий дают 80 % результата, и не факт, что остальные 80 % усилий стоит затрачивать. Возможно, стоит потратить их на что-то другое, что сделает нас ближе к цели, а не стремиться к идеально вылизанным цифрам.
Читать дальшеИнтервал:
Закладка:









