Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/1150039/roman-zykov-roman-s-data-science-kak-monetizirova.webp "Обложка книги")
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Жанр:
- Издательство:Издательство Питер
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres] краткое содержание
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
До изобретения MapReduce любой разработчик должен был придумывать схему, как разделить и распределить данные, запускать расчет и самостоятельно разбираться с отказом оборудования. MapReduce предложил новый принцип решения задач. Алгоритм требовал разбивать задачу на два этапа. Этап «Map» (предварительная обработка) – программист сообщает каждой машине, какую предобработку данных выполнить, например, посчитать, сколько раз слово «котик» встретилось на веб-странице. Затем нужно написать инструкции для этапа «Reduce» (свертка), например, заставить машины вычислить суммарное количество «котиков» на всех веб-страницах мира.
В 2004 году индексирующий движок Google был переведен на MapReduce. Затем эту технологию стали использовать для обработки видео и рендеринга карт Google Maps. Она была настолько проста, что ее стали использовать для широкого круга проблем. В том же году со стороны Google был заявлен патент [36] на MapReduce. Тогда же Джеффри и Санджай подумали, что было бы полезно познакомить астрономов, генетиков и других ученых, у которых очень много данных, c MapReduce. Они написали и опубликовали статью: «MapReduce: упрощенная обработка данных на больших кластерах» [37].
Статья произвела эффект разорвавшейся бомбы. Дешевое железо, рост числа веб-сервисов и подключенных устройств к Сети привели к «потопу» данных. На рынке было только несколько компаний с программными технологиями, которые могли справиться с этим. Дуг Каттинг и Майк Кафарелла (Mike Cafarella and Doug Cutting) работали над масштабированием своего поискового движка Nutch. Они были так впечатлены статьей, что на ее основе с нуля написали проект Hadoop. Затем Yahoo приглашает Каттинга продолжать работу над проектом внутри компании. В 2008 году начинается широкое применение Hadoop технологическими компаниями. Apache Hadoop сейчас распространяется под свободной лицензией [39].
Hadoop используется в большинстве технологических компаний, работающих с большими данными. Если не дистрибутив Apache, то какой-нибудь коммерческий от Mapr, Cloudera или другого вендора. Некоторые пошли своим путем и сделали собственную реализацию, например Яндекс.
Понять, как работает MapReduce, поможет иллюстрация (рис. 6.3).
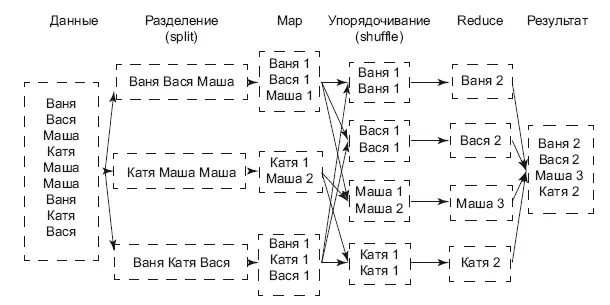
Рис. 6.3.Подсчет числа слов в тексте
Слева у нас есть исходный текст, в каждой строке которого встречаются имена людей. Первая операция, Split, разрезает текст по строкам, каждая строка обрабатывается независимо от других. Вторая операция, Map, считает количество упоминаний каждого имени в строке. Ее мы можем проводить параллельно на разных машинах, так как строки независимы друг от друга. Третья операция, Shuffle, раскидывает одинаковые имена в группы. Четвертая операция, Reduce, считает сумму упоминаний каждого имени в разных строках. На выходе мы получаем число упоминаний каждого имени в тексте. Этот пример написан на трех строках, но с триллионом строк все операции были бы такими же.
MapReduce – это концепция. Hadoop – это программное обеспечение, которое реализует эту концепцию. Сам Hadoop состоит из двух главных компонент: распределенной файловой системы HDFS и планировщика ресурсов Yarn.
Файловая система HDFS (Hadoop Distributed File System) для пользователя выглядит как обычная файловая система с папками и файлами, которую вы привыкли видеть в своих компьютерах. Сама система располагается как минимум на одном компьютере. В ней есть две главные роли – name node (центральный узел имен) и data node (узел данных). Когда пользователь хочет записать файл в HDFS, происходит разбиение файла на блоки (размер блока зависит от настройки системы), name node возвращает data node, в который нужно сохранить блок. Клиент отправляет данные на data node, после записи данные реплицируются – копируются на другие ноды. По умолчанию коэффициент репликации составляет 3, то есть один блок данных будет на трех узлах данных. Как только процесс завершится и все блоки будут записаны, name node сделает соответствующую запись в своих таблицах (где какой блок хранится и к какому файлу относится). Это дает защиту от ошибок, например, когда сервер выходит из строя. С коэффициентом репликации 3 мы можем безболезненно потерять две ноды. Кстати, в таком случае HDFS самостоятельно обнаружит такие ноды и начнет реплицировать данные между «живыми» нодами, чтобы снова достичь нужного уровня репликации. Так мы достигаем устойчивости расчетов с точки зрения данных.
Планировщик ресурсов YARN отвечает за распределение вычислительных ресурсов на кластере Hadoop. Благодаря ему мы можем запускать на одном кластере несколько задач параллельно. Сами вычисления происходят, как правило, там же, где находятся данные, на тех же самых нодах с данными. Это экономит много времени, так как скорость чтения данных с диска гораздо выше, чем скорость копирования их по сети. При запуске задачи через Yarn ему явно нужно указать, сколько ресурсов для расчета вам нужно: сколько машин (executors) из кластера, сколько ядер процессора (cores) на каждой машине и сколько памяти. Сам Yarn также предоставляет отчет в реальном времени о выполнении задачи.
Про Hadoop мне рассказали в офисе Netflix в 2011 году. Я сразу стал искать и читать документацию по этому сервису, смотрел на YouTube конференции о том, как с ним работать. В качестве эксперимента я развернул Hadoop на своем рабочем ноутбуке, выбрав в качестве дистрибутива версию от Cloudera. Удобство Hadoop в том, что его можно поставить хоть на ноутбуке – все сервисы будут крутиться на нем. По мере увеличения объема данных можно легко добавлять сервера, причем даже используя самые дешевые. Именно так я и поступил, когда начал писать рекомендательный движок Retail Rocket. Начал я с одного или двух серверов, пять лет спустя кластер Hadoop вырос до 50 машин и содержит порядка двух петабайт сжатых данных.
В начале пути я пользовался двумя языками программирования для Hadoop – Pig и Hive. На них была написана первая версия рекомендательного движка, затем мы перешли на Spark и стали писать на Scala.
Не пренебрегайте принципами MapReduce. Однажды мне они пригодились, когда я участвовал в одном из соревнований Kaggle. Датасет был очень большой, он не помещался полностью в память, пришлось писать предварительную обработку на чистом Python, используя подход MapReduce. Тогда у меня это заняло много времени, сейчас я бы поставил локально фреймворк Spark и не изобретал бы велосипед. Это сработает, ведь MapReduce-операции можно выполнять как параллельно на разных машинах, так и последовательно. Сами вычисления займут много времени, но они хотя бы посчитаются, и у вас не будет болеть голова, хватит ли памяти для расчетов.
Spark
С фреймворком Spark я познакомился в 2012 году, когда приобрел для корпоративной библиотеки Ostrovok.ru видеозаписи конференции по анализу данных Strata. Эту конференцию организует издательство O’Reilly в США. На одной из лекций я увидел, как Матей Захария (основной автор Spark) рассказывает о преимуществах Spark над чистой реализацией MapReduce на Hadoop. Самое главное преимущество в том, что Spark загружает данные в память, в так называемые отказоустойчивые распределенные датасеты RDD (resilient distributed dataset), и позволяет работать с ними в памяти итеративно. Чистый Hadoop же полагается на дисковую память – для каждой пары операций MapReduce-данные читаются с диска, затем сохраняются. Если алгоритм требует применения еще нескольких операций, то для каждой из них придется читать данные с диска и сохранять обратно. Spark же, совершив первую операцию, сохраняет данные в памяти, и последующие операции MapReduce будут работать с этим массивом, пока программа не прикажет явно сохранить их на диск. Это очень важно для задач машинного обучения, где используются итеративные алгоритмы поиска оптимального решения. Все это дало огромный прирост производительности, иногда в 100 раз быстрее классического Hadoop.
Читать дальшеИнтервал:
Закладка:









