Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/1150039/roman-zykov-roman-s-data-science-kak-monetizirova.webp "Обложка книги")
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Жанр:
- Издательство:Издательство Питер
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres] краткое содержание
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Неизменяемость уже загруженных данных в хранилище гарантирует, что ваши аналитические отчеты не будут меняться. Я буду лукавить, если скажу, что так не бывает. Бывает, но обычно из-за технических ошибок или расширения перечня хранимых данных. Такие инциденты нужно минимизировать по двум причинам. Во-первых, перезагрузка данных бывает очень длительной и блокирующей аналитическую систему. Например, у нас в Retail Rocket такая операция между Hadoop и Clickhouse могла занимать дни и даже недели. Во-вторых, доверие пользователей к вашей системе будет подорвано из-за изменения данных, а значит, отчетов и решений, которые были сделаны на их основе. Легко ли вам будет доверять данным, которые изменяются задним числом?
Я всегда стараюсь хранить данные в том виде, в котором они хранятся в источнике. Есть другой подход – делать преобразование данных при их копировании в хранилище. С моей точки зрения, второй подход имеет существенный недостаток: никто не может гарантировать, что преобразование или фильтрация пройдут без ошибок. Как минимум, данные в источнике изменятся, и преобразование «устареет». В какой-то момент вы заметите, что данные расходятся. Вам придется лезть в источник, возможно, скачивать их (а их может быть очень много) и построчно сравнивать. Такие ошибки крайне сложно искать. Поэтому удобно, когда исходные данные хранятся в сыром виде. Безусловно, преобразования нужны, но хранить измененные данные лучше в отдельных таблицах или файлах (в отдельном слое хранилища). Тогда сверка с источником будет заключаться лишь в сравнении числа строк между таблицами, а ошибки преобразований легко отыщутся внутри самого хранилища, так как исходники у вас имеются. Этот вывод был сделан мной на основе инцидентов по исправлению данных во всех компаниях, на которые я работал. Да, данных в хранилище может стать чуть ли не в два раза больше, но, учитывая сегодняшнюю низкую стоимость хранения и принцип «много данных не бывает», это все окупится.
В главе 5 я уже писал про связность данных, что самые интересные инсайты находятся на стыке их разных источников. Данные объединяются через ключи. Сама операция называется соединением данных (join). Она очень ресурсоемкая, разработчики баз данных постоянно работают над ее ускорением. На одной из лекций в компании Microsoft я услышал, что для больших данных количество таких операций нужно минимизировать, а для этого нужно сразу соединить данные в хранилище и в таком виде хранить. Это было около десяти лет назад. Сейчас уже есть системы, которые это могут делать лучше традиционных баз данных, об этом позже в этой главе.
Однажды у меня был разговор с разработчиком из компании Netflix. Я рассказывал ему про хранилища данных, а он остановил меня и сказал: «А не проще ли восстановить базу из бэкапа и с ней работать?» Во-первых, если вы не пользуетесь облачными сервисами, как это делает Netflix, то восстанавливать данные из бэкапа не так легко. Во-вторых, хранилища часто содержат свои агрегаты (о них расскажу позже), которые нужно поддерживать. В-третьих, если источников несколько и это разные базы данных или хранилища файлов, то будет невозможно делать запросы с соединением этих источников.
Слои хранилища данных
Само хранилище может состоять из нескольких слоев (рис. 6.1) [34]:
• Данные из источников «как есть» (Первичный слой данных), или по-другому – сырых данных. Как я уже писал выше, лучше их хранить в виде, максимально совпадающем с источником.
• Данные, приведенные в целостную форму, независимую от источника (Центральный слой). Это означает, что мы уже можем работать с логической схемой, человеко-понятными терминами. Аналитику не придется думать, как соотносятся термины в разных источниках, все уже сделано в этом слое.
• Данные, представленные в виде витрин для определенного круга пользователей (Витрины данных). Деление происходит по предметной области: маркетинг, продажи, склад… Лучшим примером будет подготовка данных для OLAP-кубов. Данные для них приходится специально готовить. Подробней об этом поговорим в следующей главе об инструментах анализа данных.
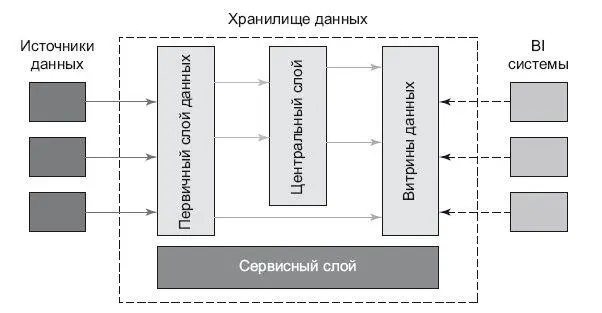
Рис. 6.1.Слои хранилища данных
Эти слои – логические, и они весьма условны; физически они могут размещаться как в разных системах, так и в одной.
В Retail Rocket я много работал с данными активности пользователей. Данные приходят в кластер в режиме реального времени в формате JSON и складируются в одну папку. Это первый слой – сырые данные. Сразу же делаем преобразование данных, чтобы было удобно работать с ними в формате CSV, складируем их во вторую папку. Это второй слой. Далее данные из второго слоя отправляются в аналитическую базу данных ClickHouse, где уже построены специальные таблицы для каких-либо задач – например, для отслеживания эффективности алгоритмов рекомендаций. Это третий слой витрины данных.
Какие бывают хранилища
Если распределить все созданные хранилища по популярности использования, то я бы их расставил так:
1. Реляционные базы данных – Postgre, Oracle, MS SQL Server и т. д.
2. «Колоночные» базы данных – Vertica, Greenplum, ClickHouse; облачные – Google BigQuery, Amazon Redshift.
3. Файловые – Hadoop.
Я не стал включать в список большие энтерпрайзные системы от IBM, Teradata и других вендоров, у них своя ниша, в которой я не работал.
Лично я работал с Microsoft SQL Server в Ozon.ru и Wikimart.ru, Postgres в Ostrovok.ru, Hadoop в Wikimart.ru и Retail Rocket, Clickhouse в Retail Rocket. У меня остались только положительные впечатления об этих технологиях. В последнее время я предпочитаю экономить и пользоваться открытыми технологиями (open-source).
Итак, реляционные базы данных (рис. 6.2) – рабочая лошадка многих бизнесов. Они все еще популярны, несмотря на атаку NoSQL-технологий. Данные в них хранятся в таблицах с колонками и строками, между таблицами есть «отношения», также можно выставлять логику при операциях с полями и т. д. Оптимизация производительности делается с помощью настройки индексов
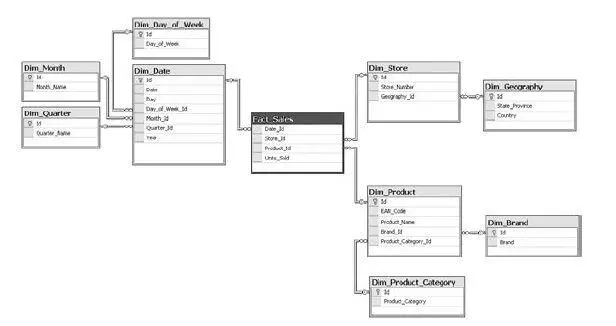
Рис. 6.2.Таблицы реляционной базы данных
и различных хаков, которые у каждого вендора свои. Они популярны, с ними умеют работать множество специалистов. Самое главное, что базы этого типа привнесли в мир, – это язык программирования SQL (Structured Query Language). Этот язык может использоваться как для внесения изменений, так и для получения данных. Минус реляционных баз – низкая производительность, когда идет работа с большими данными. И в Ozon.ru, и в Wikimart.ru я держал данные по статистике посещения сайтов в обычной таблице, а это миллиарды строк. Можно было сходить на обед, пока считался нужный запрос.
Читать дальшеИнтервал:
Закладка:









