Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/1150039/roman-zykov-roman-s-data-science-kak-monetizirova.webp "Обложка книги")
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Жанр:
- Издательство:Издательство Питер
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres] краткое содержание
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
На помощь реляционным базам данных, в которых данные хранятся построчно [35], пришли колоночные базы. И совершили революцию. Вот пример таблицы реляционной базы (табл. 6.1).
Таблица 6.1. Пример данных реляционной таблицы
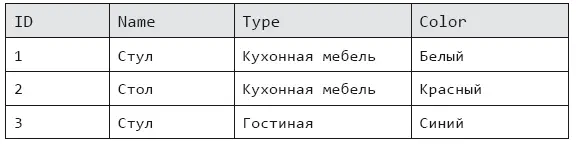
Чтобы найти все товары с типом (колонка Type) «Гостиная», придется прочитать все строки данных (если нет индекса по этому столбцу), что удручает, если их миллиарды и даже триллионы. В колоночной базе данные хранятся по столбцам отдельно, отсюда и название – колоночные:
ID: 1 (1), 2 (2), 3 (3)
Name: Стул (1), Стол (2), Стул (3)
Type: Кухонная мебель (1), Кухонная мебель (2), Гостиная (3)
Color: Белый (1), Красный (2), Синий (3)
Теперь, если делать выборку товаров по типу «Гостиная», придется прочитать только нужный столбец. Но как найти нужные записи? Это не проблема: каждое значение столбца содержит номер записи, к которому оно относится. Дополнительно значения столбцов можно отсортировать и даже сжать, что делает такие базы еще быстрее. В них тоже есть минус – требовательность к «железу» сервера, на котором она работает. Колоночные базы идеально подходят для аналитических задач, которые изобилуют запросами по фильтрации и агрегации данных.
Если нужна «молотилка» для совсем больших данных – то это Hadoop. Она была разработана в компании Yahoo, которая сделала эту технологию общедоступной. Эта система работает на распределенной файловой системе HDFS и не требовательна к оборудованию. Для Hadoop компания Facebook разработала SQL-движок под названием Hive, позволяющий писать запросы к данным на языке SQL. Главное преимущество Hadoop – большая надежность. Минус – медленная скорость, зато там, где обычная БД не справится с каким-то запросом, Hadoop доведет дело до конца, медленно, как черепаха, но верно. Я использовал Hive и был доволен результатом, мне удавалось даже писать на нем простейшие алгоритмы рекомендаций.
Теперь главный вопрос – когда и какие технологии использовать?
Мой рецепт следующий:
• Если данных относительно немного и нет таблиц с миллиардами строк, то проще использовать обычную реляционную базу.
• Если данных больше миллиарда строк или требуется хорошая скорость для аналитических запросов (агрегация и выборки) – то лучше всего использовать колоночную базу данных.
• Если требуется хранить очень большой объем с сотнями миллиардов строк, вы готовы мириться с медленной скоростью или хотите иметь архив исходных данных – то Hadoop.
В Retail Rocket использовался Hive поверх Hadoop для службы технической поддержки, но запросы могли выполняться больше получаса. Поэтому требуемые ими данные были переведены в Clickhouse (колоночная база данных), и обработка запросов ускорилась в сотни раз. А скорость очень важна для интерактивных аналитических задач. Сотрудники Retail Rocket мгновенно полюбили новое решение за его скорость. Hadoop при этом остался в качестве рабочей лошадки для расчета рекомендаций.
Как данные попадают в хранилища
Чтобы данные оставались актуальными, их нужно периодически обновлять. Делать это можно путем полного или инкрементального обновления.
Полное обновление применяют к справочникам и состояниям на определенный момент времени (об этих типах я писал в главе 5). Выглядит оно следующим образом – данные скачиваются из источника в промежуточную таблицу или папку (staging) хранилища, и если операция прошла успешно, эти старые данные меняются на свежие. Плюсом такого типа обновления является полное соответствие данных источнику на момент скачивания. Первым минусом является время для обновления таблиц, которое напрямую зависит от размера исходных данных. Второй минус – потеря изменений после обновления данных. Представьте, что у вас есть справочник с товарами магазина, в исходной системе он всегда актуален, а в хранилище обновляется каждый день в полночь. Если какой-то товар был заведен и удален из справочника – вы этого не заметите в хранилище. Для аналитика это будет выглядеть так, будто такого товара не существовало. Заказы этого товара могли совершаться. Поэтому при анализе заказов возникнет ситуация нарушения целостности данных: в таблице этот заказ есть, в справочнике товаров – нет.
Инкрементальное обновление данных применяется для лога изменений (я писал о нем в главе 5). Конечно, можно его полностью перезагружать, но обычно это нецелесообразно из-за большого объема, а следовательно, медленной скорости обновления. Само инкрементальное обновление выглядит следующим образом: система смотрит в хранилище, какие данные были загружены последними (это может быть время или какой-то идентификатор). Далее делается запрос к источнику: «Отдай мне данные, которые поступили после момента X». После получения эти данные добавляются к старым в хранилище. Плюсом инкрементального обновления является скорость. Минусом – возможна рассинхронизация данных, когда были добавлены лишние записи, которые уже были, или, наоборот, произошла потеря данных.
Принципиально есть два типа инкрементального обновления: пакетный и потоковый.
Пакетный (batch) – данные загружаются большими блоками. Например, таблица с заказами клиентов обновляется раз в сутки в первый час ночи – происходит загрузка данных за последние сутки, и они добавляются в хранилище. Вариантов реализаций таких обновлений много – от специализированного софта до самописных систем. Я использовал оба подхода. В Ozon.ru и Wikimart.ru пользовался Microsoft Integration Services, которые входили в пакет MS SQL Server. В ней просто мышкой рисуются потоки данных между источником и хранилищем, программирования там минимум. В Retail Rocket использовалась самописная утилита без графического интерфейса, которая занималась скачиванием данных из Hadoop в ClickHouse.
Потоковый (stream) – данные загружаются по одной записи или мелкими пакетами по мере их поступления. Обычно это создается для данных, которые нужно поддерживать в «реальном времени». Если обратиться к примеру выше, то в таблицу с заказами клиентов новые заказы будут попадать по мере их появления. В таком случае будет небольшое запаздывание между созданием самого заказа и его появлением в хранилище. Оно может варьироваться от миллисекунд до часов, и это время обязательно контролируется через мониторинг.
Hadoop и MapReduce
Сначала расскажу, как появился Hadoop. К этому приложил руку Google. На мой взгляд, у этой компании есть два великих изобретения: PageRank и MapReduce. Джеффри Дин и Санджай Гемават (Jeffrey Dean и Sanjay Ghemawat) в течение четырех месяцев 2003 года разрабатывали технологию MapReduce [38]. Эта идея пришла к ним, когда они в третий раз переписывали движок Google, отвечающий за скачивание и индексацию страниц. Эти два разработчика решили важную проблему: они нашли способ скоординировать работу огромного числа зачастую ненадежных компьютеров в разных дата-центрах по всему миру. Ведь отказ одного или нескольких компьютеров потребует повторного запуска расчетов, что очень проблематично, когда мы имеем дело с тысячей машин. Но самое замечательное, что Дин и Гемават не просто нашли решение частной проблемы – они создали философию. MapReduce позволил разработчикам Google обращаться к серверам их дата-центров как к одному огромному компьютеру.
Читать дальшеИнтервал:
Закладка:









