Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/1150039/roman-zykov-roman-s-data-science-kak-monetizirova.webp "Обложка книги")
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Жанр:
- Издательство:Издательство Питер
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres] краткое содержание
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Выбросы – это данные, которые не укладываются в нашу картину мира, а точнее в распределение, которое мы обычно наблюдаем: кто-то совершил очень крупную покупку в магазине, поступили странные данные от одного из избирательных участков, зачислена аномально большая сумма на счет. Все это выбросы, но удалять их из анализа просто так нельзя. Часто удаление выброса может привести к изменению выводов и решений на полностью противоположные. Считаю, что работа с выбросами данных является искусством. Более подробно это рассмотрим в главе 10.
Теперь поговорим про данные, которые невозможно восстановить повторным чтением из источника. Выше я писал, почему это может произойти, – в системе существует ошибка интеграции или разработчики не сделали сбор и отправку необходимых данных. Таким источникам данных необходимо уделять самое пристальное внимание, например, написать специальные тесты, чтобы как можно раньше заметить проблему. А вот с невнимательностью разработчиков лучше работать на уровне управления проектом внедрения или внося изменения в их культуру разработки. Об этом я писал в разделе «Много данных не бывает».
Типы данных
Вот основные типы данных, с которыми приходится работать:
1. Состояние на определенный момент времени.
2. Лог изменений данных.
3. Справочники.
Разберем каждый тип отдельно на примере с банковским счетом. Итак, у вас есть счет, туда приходит зарплата, скажем, первого числа каждого месяца. Вы пользуетесь картой, привязанной к этому счету, для оплаты покупок. Так вот, остаток средств на вашем счете прямо сейчас – это состояние счета на определенный момент времени. Движение средств по счету – это так называемый лог изменений состояния счета (лог изменения данных). А справочником могут выступать категории покупок, которые банк проставляет в онлайн-приложении для каждой покупки, например: продукты, авиабилеты, кинотеатр, ресторан. А теперь подробнее о каждом типе данных.
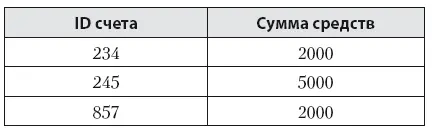
Состояние на определенный момент времени. Все мы имеем дело с разными объектами, как физическими, так и виртуальными. Эти объекты имеют свойства или атрибуты, которые могут изменяться во времени. Например, координаты вашего местонахождения на карте, остаток средств на счете, цвет волос, который может измениться после посещения парикмахерской, рост и вес, которые меняются со временем, статус заказа в онлайн-магазине, ваша должность на работе. Это все объекты с каким-то свойством. Чтобы отследить изменения этих свойств, нужно их периодически запоминать, например, сделав «слепок» (snapshot) всех счетов клиентов в банке (табл. 5.1). Имея на руках два таких слепка, можно легко посчитать изменения. Но есть альтернативный способ отслеживать изменения.
Таблица 5.1. Пример «слепка» счетов клиентов
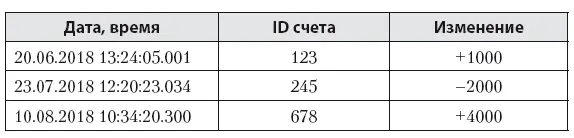
Если запоминать, в какой момент времени какое свойство/атрибут объекта менялось, включая информацию о его новом значении, то мы получим так называемый лог изменений данных. Когда речь идет о таком типе данных, я обычно представляю себе таблицу (табл. 5.2), непременными атрибутами которой являются следующие столбцы:
• Дата и время изменения свойства – точность может быть очень высокой, вплоть до наносекунд.
• Указание на объект, который изменился. Например, номер банковского счета.
• Новое значение свойства или его изменение. Например, в этом поле можно сохранить новое значение суммы на счете, но обычно там находится сумма списания или зачисления на счет со знаком «плюс» или «минус».
Иногда может быть еще несколько необязательных полей: название атрибута, если их несколько, например вес или рост; старое значение атрибута, это может потребоваться для проверки целостности данных (табл. 5.2).
Таблица 5.2. Изменения счетов клиентов
Что касается справочников, то они, как правило, содержат информацию, которая не изменяется часто и позволяет «расшифровать» или обобщить данные. Например, в таблице лога изменений или состояния может храниться не имя клиента, а его номер или идентификатор (ID), тогда в справочнике будет храниться соответствие этого идентификатора и имени клиента. Обобщение может быть нужно, чтобы агрегировать данные, например, по типу клиента – юридическое или физическое лицо. Для магазина это может быть категория товаров или даже дерево категорий, оформленное в специальной структуре. Сам справочник тоже может изменяться, и его тоже возможно представить и в виде таблицы состояния, и в виде лога изменений, если такое потребуется.
Большая часть данных в мире представлена вышеупомянутыми типами, их достаточно для выполнения подавляющего большинства задач анализа данных.
Форматы хранения данных
Аналитики в основном работают с двумя типами данных: файлы и базы данных.
Самый распространенный формат для анализа данных – файлы. Практически во всех открытых источниках публикуются именно они. Также системы хранения больших данных, как Hadoop, тоже используют файловый формат хранения. Вообще файл – это вариант передачи данных. Когда вы сохраняете что-то в файл из программы, вы «сериализуете» данные в нули и единицы (биты), которые будут храниться на диске. Когда вы читаете файл в программе, чтобы транслировать его в память, происходит «десериализация», то есть превращение последовательных нулей и единиц (битов) в структуры данных, понятных для обработки в программе. Запомните эти термины, они вам пригодятся при чтении литературы и статей про данные.
Формат файлов бывает текстовым и бинарным. Текстовый для обычных данных, главный признак – возможность его посмотреть через обычный текстовый редактор. Этот формат используется тогда, когда все данные можно представить в виде текста и букв. Бинарный формат используется уже для данных, которые нельзя представить в виде цифр и букв, например картинки и звук. Хотя есть способ представить бинарные данные в текстовом виде, например, закодировать специальными кодеками, такими как Base64. Тогда бинарные данные можно хранить и в текстовых файлах. Есть один недостаток – размер данных увеличивается примерно на 36 %, что может быть существенным для больших данных.
Среди текстовых форматов файлов наиболее распространены три:
• CSV (comma-separated values) или TSV (tab-separated values).
• JSON (Java Script Object Notation).
• XML (eXtensible Markup Language).
Файлы CSV самые удобные и простые, выглядят они как обычная таблица, где разделитель между столбцами запятая (хотя это может быть табуляция, точка с запятой и т. д.), разделитель между строками (записями) – перенос строки. Парсить (прочитать и разметить поля в собственной программе) такие файлы одно удовольствие. Их очень легко просмотреть в любом редакторе или консоли. Есть у них только пара минусов. Если используется символ разделителя (запятая или иной), то в полях этот символ нужно экранировать, например, обернув все поле кавычками. В то же время в самом поле тоже могут быть кавычки. Придется это поддержать в парсере (программа или код, которая будет читать это файл). Это усложняет работу с такими файлами и иногда приводит к появлению битых записей, которые не удалось распарсить. Второй недостаток – то, что таблица плоская, поэтому невозможно использовать данные со сложной структурой или же придется упаковывать их в сложный формат, например JSON, и размещать в полях как обычный текст.
Читать дальшеИнтервал:
Закладка:









