Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/1150039/roman-zykov-roman-s-data-science-kak-monetizirova.webp "Обложка книги")
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Жанр:
- Издательство:Издательство Питер
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres] краткое содержание
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Администрирование пользователей удобно, когда есть единая система учета. В таком случае пользователям не нужно помнить множество паролей, а администраторам легко регулировать доступ. По своему опыту скажу, что если компания использует, например, G Suite для бизнеса от Google, то система отчетности, которая может использовать ту же самую авторизацию, будет удобнее, чем не использующая. Например, тот же Metabase [47] позволяет авторизоваться через Google, а SuperSet [48] нет.
Рассылка отчетов бывает периодической, когда она происходит по часам или определенным дням, и триггерной – в ответ на появление какого-либо события или изменения показателя. Триггерные рассылки часто используются в ИТ, например, чтобы поймать момент, когда падает какая-либо система или критически поднимается нагрузка. Для этого на определенный показатель системы выставляется пороговое значение, при превышении которого высылается соответствующее письмо. В бизнесе сложнее – там показатели не так быстро меняются: в интернет-магазине, например, можно поставить пороговые значения на количество заказов за последний час или трафик, чтобы как можно быстрее узнать о проблеме и избежать большой потери выручки. Отчеты могут присылаться в теле письма, что удобнее (вы сразу увидите результат), в приложенных файлах, например в формате Excel, или краткий отчет в теле письма, а расширенный доступен по ссылке. Удобство отчетов по электронной почте зависит от задач: если нужно быстро взглянуть на графики в мобильном телефоне, то лучше, когда отчет в теле письма; если с цифрами нужно будет работать – файл с электронной таблицей будет идеальным вариантом.
Что будет, если отчет запустить несколько раз подряд? Например, несколько пользователей с разницей в одну минуту запросят один и тот же отчет. Ждать очередные пять минут, пока он считается? Это зависит от схемы кэширования – в хорошей системе она есть. При публикации отчета выставляется период кэширования или сохранения прошлых результатов. Например, если выставить период в 30 минут, то после расчета данные отчета будут сохранены для последующих запросов ровно на 30 минут. И все последующие отчеты будут уже использовать их. Это очень полезно для тяжелых вычислений, пусть при кэшировании данные в отчете могут отставать от хранилища. В Ozon.ru одно время в системе back-office был отчет с текущими результатами дня. Отчет очень часто обновляли сотрудники из азарта. Это привело к DoS (Denial of Service – отказ в обслуживании) – атаке, которая ухудшила производительность. Кэширование отчета на определенное время остудило пыл азартных любителей цифр и разгрузило систему приема заказов.
Интерактивный анализ – это когда вы исследуете данные, проваливаясь вглубь цифр и метрик; он де-факто считается стандартом любой аналитической системы. Есть графический тип анализа, хороший пример – Google Analytics: практически все тут можно сделать мышью. Второй тип – сводные таблицы. Я больше склонен именно к такому типу анализа. Делаю выборку данных, копирую ее в любую электронную таблицу, включаю анализ сводных таблиц (pivot table), а далее уже в интерфейсе «кручу» данные. На самом деле почти всегда, когда мы работаем с интерактивным анализом данных, мы работаем со сводными таблицами.
Если вкратце, то мои минимальные требования к отчетной системе такие:
• авторизация пользователей, желательно завязанная на корпоративную систему доступа;
• тонкий клиент, доступ через веб-браузер;
• возможность просмотра отчета, полученного по электронной почте, сразу на экране;
• несложная параметризация большого отчета, состоящего из множества блоков;
• кэширование результатов.
Сводные таблицы
Сводные таблицы (pivot tables) – это самое лучшее, что было изобретено в разведочном анализе данных. Если аналитик хорошо владеет сводными таблицами, он всегда заработает на хлеб с маслом. Сводная таблица избавляет нас от огромного числа бесполезных запросов к данным, когда нужно просто найти хоть какую-то зацепку. Я уже писал выше про свой личный шаблон интерактивного анализа данных: сделать выборку данных, скопировать данные в электронные таблицы, построить сводную таблицу и работать с ней. Этот способ сэкономил мне годы по сравнению с прямыми методами – подсчетом описательных статистик, построением простых графиков, то есть стандартными операциями анализа данных для любых аналитических инструментов. А теперь разберем по пунктам, как работать со сводными таблицами.
Во-первых, нужно подготовить данные. Они должны выглядеть как таблица фактов (fact table), которая делается на основе таблиц состояния на определенный момент или лога изменений данных (вспоминаем главу про данные). Если в таблице используются непонятные обычному человеку идентификаторы и у вас есть справочники на них, то лучше расшифровать это поле, присоединив (join или merge) данные справочника к таблице фактов. Поясню на примере. Мы ищем причину падения продаж. Пусть у нас есть таблица состояния заказов на определенный момент, у нее есть следующие поля:
• Дата и время создания заказа (например, 10 ноября 2020 года 12:35:02).
• ID типа клиента, который совершил заказ (1, 2).
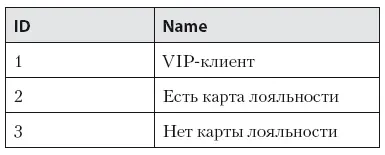
• ID статуса клиента в программе лояльности (1, 2, 3).
• ID заказа (2134, 2135, …).
• ID клиента (1, 2, 3, 4…).
• Сумма заказа в рублях (102, 1012…).
Эта таблица будет таблицей фактов, так как в ней записаны факты появления заказов. Аналитик хочет увидеть, как заказывали клиенты разных типов и статусов в программе лояльности. У него есть гипотеза, что там находится основная причина изменения продаж. ID-поля нечитаемы и созданы для нормализации таблиц в учетной базе данных, но у нас есть справочники (табл. 7.1–7.2), которые полностью расшифровывают их.
Таблица 7.1. Справочник типа клиента
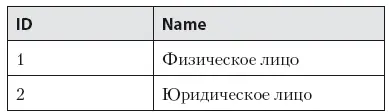
Таблица 7.2. Статусы клиента в программе лояльности
После соединения (join или merge) таблицы фактов со справочниками мы получим обновленную таблицу (табл. 7.3) фактов:
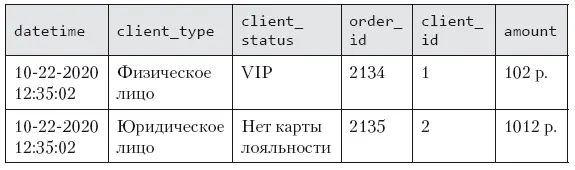
• datetime – дата и время создания заказа (например, 10 ноября 2020 года 12:35:02).
• client_type – тип клиента, который совершил заказ (физическое или юридическое лицо).
• client_status – статус клиента в программе лояльности (VIP, есть карта лояльности, нет карты лояльности).
• order_id – ID заказа (2134, 2135, …).
• client_id – ID клиента (1, 2…).
• amount – cумма заказа в рублях (102, 1012…).
Таблица 7.3.Пример объединения данных
Что в этой таблице фактов хорошо – нет id полей, кроме двух – заказов и клиентов, но это полезные поля, они, возможно, понадобятся, чтобы посмотреть более подробно какие-то заказы во внутренней учетной системе. Аналитик получил выборку данных в указанном выше виде, поместил ее в электронную таблицу, например Microsoft Excel или Google Sheets. Построил над этой таблицей сводную (pivot table). Приступим к ее анализу.
Читать дальшеИнтервал:
Закладка:









