Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/1150039/roman-zykov-roman-s-data-science-kak-monetizirova.webp "Обложка книги")
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Жанр:
- Издательство:Издательство Питер
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres] краткое содержание
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
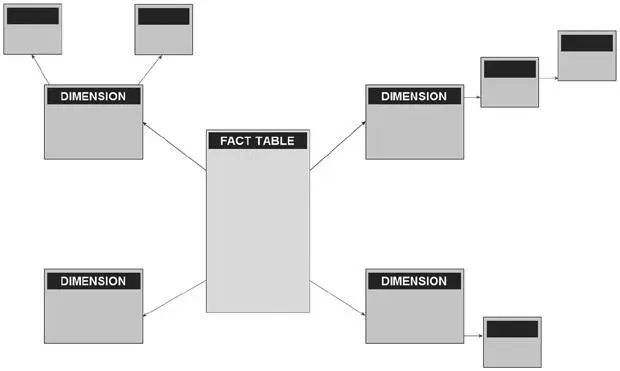
Рис. 7.4.Соединение таблиц по схеме «звезда»
Но что делать, если появились новые данные? Нужно обновить данные в нашей «звезде» – хранилище – и обновить куб на их основе. Обновление данных для уже обработанного рабочего куба заключается в полном прочтении всех измерений (справочников): если появляются новые элементы или они переименовываются – все обновится. Поэтому справочники измерений для OLAP-кубов нужно сохранять и обновлять в первозданном виде – данные оттуда удалять нельзя. Обновление таблицы фактов интереснее – можно выбрать полное обновление и пересчет куба, а можно стереть старые данные из таблицы фактов и залить туда новые, которых нет в кубе, и только после этого обновить куб. Схема с инкрементальным обновлением выгоднее с точки зрения времени обработки куба. В Ozon.ru полный процессинг куба мог занимать у меня четыре дня, а инкрементальное обновление всего двадцать минут.
Существует несколько популярных вариантов хранения и обработки данных в OLAP-кубах:
• MOLAP – та схема хранения, которую я описал выше. Данные хранятся в специальных структурах, которые очень быстро вычисляют сводные таблицы.
• ROLAP – данные никуда не помещаются, они находятся в хранилище. OLAP-куб транслирует запросы из сводных таблиц в запросы к хранилищу и отдает результат.
• HOLAP – данные частично находятся в MOLAP-, частично в ROLAP-схемах. Например, это может быть полезно для уменьшения времени отставания куба от реального времени. Куб обновляется раз в день по схеме MOLAP, а новые данные, которых там пока нет, существуют в схеме ROLAP.
Я всегда предпочитал пользоваться MOLAP-схемой, как наиболее быстрой. Хотя в связи с развитием быстрых колоночных баз данных ROLAP могут оказаться проще. Ведь ROLAP-схема не требует тщательного дизайна куба, как MOLAP, что сильно упрощает техническую поддержку OLAP-куба.
Самый идеальный клиент для OLAP-кубов – это электронные таблицы Microsoft Excel, где работа с кубами от Microsoft реализована очень удобно. Любые тонкие клиенты не обеспечивают того удобства и гибкости, которые предлагает Excel: возможность использования MDX, гибких формул, построения отчетов из отчетов. К сожалению, эта функциональность поддерживается только в операционной системе Windows. Версия Excel для OS X (Apple) не поддерживает ее. Вы даже не представляете себе, сколько руководителей и специалистов шлют проклятья разработчикам MS за это. Ведь им приходится держать отдельные ноутбуки с Windows или удаленные машины в облаке только для того, чтобы работать с кубами Microsoft. Я считаю, что это самая большая ошибка Microsoft в нашей области.
Корпоративные и персональные BI-системы
В построении аналитики в компании есть два подхода – корпоративный и персональный (self-service BI). О персональных средствах мы уже поговорили. Теперь посмотрим на системы корпоративного уровня. Обычно в корпоративную систему принятия решений входит ряд компонент, о которых уже написано выше:
• хранилище данных;
• система обновления данных в хранилище (ETL);
• система интерактивного анализа и отчетности.
Примером такой системы может быть Microsoft SQL Server: хранилищем выступает сам SQL-сервер, Integration Services – это ETL, Analysis Services – OLAP-кубы для интерактивных и статичных отчетов, Reporting Services – система отчетности через тонкий клиент. Подобная схема продуктов есть у многих вендров BI-систем, в том числе у облачных.
С моей точки зрения, главное отличие корпоративных систем от персональных – их разработка осуществляется централизованно. Например, если нужно внести изменения в отчет или другую компоненту, то самостоятельно это не сделать и придется обратиться к разработчику. Часто доходит до крайности, когда становится невозможным что-то изменить в системе без участия разработчика.
Полностью персональные системы автономны: данные берутся напрямую из источников данных и складируются в виде локальных файлов на компьютере аналитика. Им не нужен разработчик – аналитик может сделать все самостоятельно. Это другая крайность. Давайте сравним эти два подхода.
Скорость изменений – персональные системы выигрывают у корпоративных. Любое изменение в корпоративной системе даст изменения у всех конечных пользователей. Такие изменения необходимо согласовывать и ждать, пока их внесут. В персональных системах пользователь просто вносит нужные ему изменения.
Качество данных выше у корпоративных систем. Тут их консервативность играет нам на руку: практики разработки и дизайна системы позволяют следить за качеством данных. У персональных систем с этим плохо – они очень зависимы от навыков и внимательности пользователя, что повышает вероятность ошибок.
Производительность – корпоративные системы сразу проектируют под нужную нагрузку, а если они не справляются, то есть технологии их масштабирования. С персональными системами вероятность столкнуться с плохой производительностью намного выше.
Смена вендора решения : корпоративные системы – это деревья с сильными корнями, которые потом будет очень тяжело выкорчевать. Персональные намного проще.
С моей точки зрения, оба варианта имеют право на жизнь. Лучшие результаты можно получить, объединив два подхода. Ничто не мешает вам построить хранилище (или озеро данных), а затем использовать гибкие персональные инструменты для работы в «последней миле». Часть вопросов снимается, вероятность ошибки пользователя остается, но она становится меньше.
Мой опыт
Я работал с разными системами: от файлов электронных таблиц до распределенных систем Hadoop/Spark с петабайтами данных. Могу только сказать: всему свое время. Архитектура аналитических систем – это искусство, требующее недюжинных талантов. В этой главе я рассказал о своих наработках, которые были проверены на практике. У любых решений есть плюсы и минусы, и знать их лучше до создания системы, а не после.
Вы всегда будете балансировать между скоростью и качеством, между стоимостью сейчас и потом. Но всегда полезно думать о пользователе. Чем быстрее и интуитивнее он сможет работать с данными, тем меньше эта работа будет вызывать отторжение и тем эффективнее он будет принимать решения. Я считаю, что именно скорость, даже при средних гарантиях качества, обеспечивает успех компаний. Выиграет та, которая приняла больше решений.
Аналитические системы позволяют ориентироваться в данных, но они не принимают решения – это делают пользователи. Давайте сделаем их жизнь лучше, упростив для них путь принятия решений.
Глава 8
Алгоритмы машинного обучения
Интервал:
Закладка:









