Денис Соломатин - Основы статистической обработки педагогической информации

- Название:Основы статистической обработки педагогической информации
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:2020
- ISBN:978-5-532-04389-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Денис Соломатин - Основы статистической обработки педагогической информации краткое содержание
Основы статистической обработки педагогической информации - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Это, однако, вносит некоторое дублирование в код. Представите, что хотите изменить ось y для отображения успеваемости по теме 3 вместо темы 2, нужно будет менять переменную в дух местах, при этом можно забыть про обновление в одном из них.
Дабы избежать подобного сценария, набор значений аргумента mapping передается непосредственно в функцию ggplot(). ggplot2 будет рассматривать эти значений как глобальные и применять их к каждой функции вызываемой внутри. Другими словами, следующий код создаёт ту же иллюстрацию, что и предыдущий, но более лаконичен:
ggplot (data = My_table, mapping = aes (x = `№№`, y = Тема2)) +
geom_point() + geom_smooth()
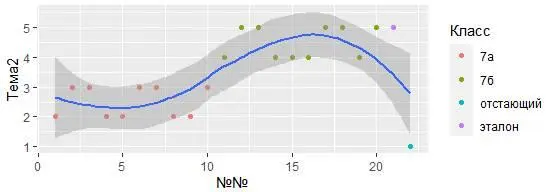
Если же размещаете параметры mapping внутри каждой функции geom, то ggplot2 будет рассматривать их как локальные настройки для слоя. Будет использоваться параметр mapping для расширения или перезаписи глобальных настроек слоя. Это позволяет настраивать различную эстетику внутри индивидуальных слоёв:
ggplot (data = My_table, mapping = aes (x = `№№`, y = Тема2)) +
geom_point (mapping = aes (color = Класс)) + geom_smooth()
Можно использовать подобную идею, чтобы выбирать разные данные для каждого слоя:
ggplot (data = My_table, mapping = aes (x = `№№`, y = Тема2)) +
geom_point (mapping = aes (color = Класс)) +
geom_smooth (data = My_table[My_table$Класс == "7а", ], se = FALSE)
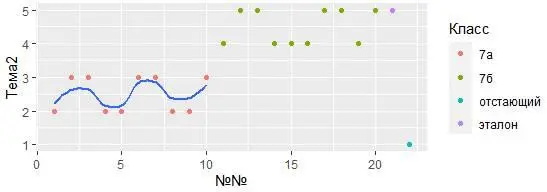
В приведенном примере, гладкая линия охватывает только подмножество исходного набора данных. Локальный аргумент в geom_smooth() переопределяет глобальный аргумент отбора данных в ggplot().
Разберем как работает фильтрация чуть позже, на данный момент достаточно понять, что эта команда выбирает только учеников 7а класса, а опция se = FALSE отключает подсветку доверительного интервала.
Упражнения
1. Какую функцию из категории geom_ вы бы использовали для построения линейного графика? А для круговой, лепестковой диаграммы, гистограммы?
2. Что меняет опция show.legend = FALSE? Что происходит если её убрать? Как думаете, почему она использовалась ранее в примере?
3. Что делает аргумент se для функции geom_smooth ()?
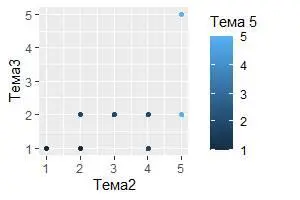
4. Воссоздайте код R, необходимый для создания следующего рисунка и дайте ему соответствующую интерпретацию:
Подробнее остановимся на гистограммах, – так называемых прямоугольных диаграммах. Они кажутся простыми, но интересны тем, что открывают потенциальные закономерности в наблюдаемой статистике. Рассмотрим базовую линейчатую диаграмму, построенную следующим образом с помощью функции geom_bar(). Принимая во внимание, как Роберт Грин Ингерсолл (1833-1899) за оффлайн-школой закрепил хлёсткое определение: «Школа – это место, где шлифуют булыжники и губят алмазы», – медленно, но верно приобщаясь к принципиально иной онлайн-школе попробуем всё же научиться правильному обращению с алмазами. На диаграмме ниже будет показано общее количество обработанных алмазов – бриллиантов, хранящихся в предустановленной с пакетом ggplot2 базе данных, сгруппированных по огранке.
База данных о бриллиантах (diamonds) поставляется в комплекте ggplot2 и содержит информацию о ~54 000 дорогостоящих украшениях, включая цену, размер в каратах, цвет, прозрачность и огранку каждого из них. Несомненно, онлайн-учителю любой по карману. Диаграмма показывает, что бриллиантов с идеальной огранкой имеется гораздо больше, чем с черновой обработкой:
ggplot (data = diamonds) +
geom_bar (mapping = aes (x = cut, colour = diamonds$color))
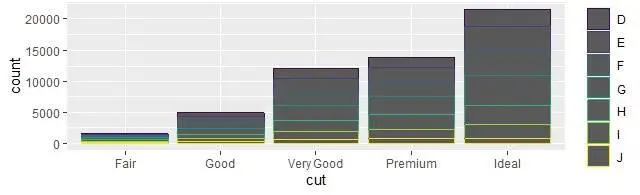
На оси x диаграмма показывает огранку (cut) алмазов. На оси y с учетом цвета отображается их общее количество (count), но в базе данных не хранится поле count. Откуда же берется информация о количестве? Одни алгоритмы графопостроителей, например диаграммы рассеяния, формируют изображение по необработанным значениям исходного набора данных. Другие, например гистограммы, вычисляют новые вспомогательные значения при построении. Гистограммы, как частотные диаграммы, преобразуют ваши данные, осуществляют подсчеты числа записей определенного типа, будто раскладывая их по ящикам. При масштабировании последних диаграмма адаптируется к объему исходных данных, а затем строятся прямоугольники нужного размера. Вычисляется статистическая сводка выборки и после этого рисуется специально отформатированный прямоугольник. Алгоритм, используемый при вычислении новых значений для графиков, определяется параметром stat, сокращенно от «статистическое преобразование». В примере ниже показано, как это работает с geom_bar(). Вы можете узнать, какое статистическое преобразование использует та или иная функция, проверив значение по умолчанию аргумента stat. Например, в документации по функции ?geom_bar сказано, что её значение по умолчанию для аргумента stat это count, то есть geom_bar() использует функцию stat_count(), описанную на той же странице, что и geom_bar(), и если прокрутить вниз, то можно найти раздел «вычисляемые переменные», в котором сказано, что вычисляются две новые вспомогательные переменные: count и prop.
Как правило, префиксы geom_ и stat_ взаимозаменяемы. Например, можно запустить предыдущий пример с использованием stat_count() вместо geom_bar(). Это работает, потому что каждая функция категории geom_ имеет параметр stat по умолчанию, а каждая функция категории stat_ имеет двойственный параметр geom по умолчанию. Это означает, что можно используйте функции построения графиков, не беспокоясь о лежащих в их основе статистических преобразованиях данных. Есть три причины, по которым может потребоваться использовать параметр stat в явном виде:
1) Возможно, захотите переопределить используемое по умолчанию статистическое преобразование. В коде ниже, заменено значение аргумента stat в geom_bar() с count (принятого по умолчанию) на identity. Это позволяет сопоставить высоту баров с необработанным значением переменной. Когда говорят о столбцевой диаграмме, можно иметь ввиду такой тип гистограммы, в котором высота столбика уже присутствует в данных, либо предыдущую диаграмму, на которой высота генерируется с помощью подсчет строк.

Историческая справка.
Как известно, из всех систем оценивания знаний в России поныне жива 5-балльная, которая была в 1837 году официально установлена Министерством народного просвещения. Положим, что продемонстрированные воспитанницами на одном из уроков математики в Серпуховской женской гимназии результаты были занесены в следующую демонстрационную таблицу.
Читать дальшеИнтервал:
Закладка:









