Денис Соломатин - Основы статистической обработки педагогической информации

- Название:Основы статистической обработки педагогической информации
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:2020
- ISBN:978-5-532-04389-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Денис Соломатин - Основы статистической обработки педагогической информации краткое содержание
Основы статистической обработки педагогической информации - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
library(tidyverse)
demo <���– tribble( ~оценка, ~количество,
"слабо", 1,
"посредственно", 1,
"достаточно", 3,
"хорошо", 2,
"отлично", 3 )
ggplot(data = demo) +
geom_bar(mapping = aes(x = оценка, y = количество), stat = "identity")
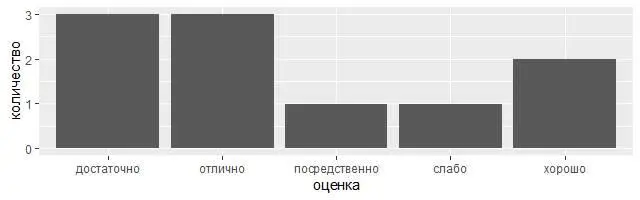
Не волнуйтесь, что не видели <���– tribble раньше. Из контекста понятно назначение этих операторов, но что именно они делают в общем случае, будет подробно рассказано чуть позже.
2) Возможно, потребуется переопределить сопоставление по умолчанию от трансформированных переменных. Например, можете чтобы отобразить линейчатую диаграмму частот, а не количества:
library(tidyverse)
demo <���– tribble( ~оценка, "слабо", "посредственно",
"достаточно", "достаточно", "достаточно",
"хорошо", "хорошо",
"отлично", "отлично", "отлично" )
ggplot (data = demo) +
geom_bar (mapping = aes (x = оценка, y = stat (prop), group = 1))
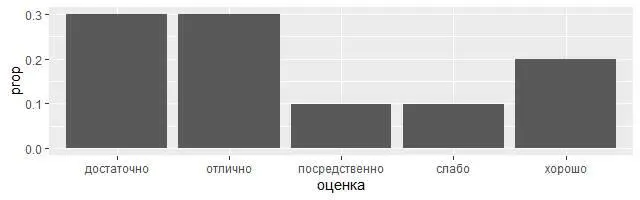
Чтобы найти полный список переменных, вычисляемых в статистике, достаточно заглянуть в раздел справки, озаглавленный как «вычисляемые переменные».
3) Возможно, захотите извлечь больше статистической информации в вашем коде. Например, если использовать функцию stat_summary(), то будет получена дополнительная описательная статистика, которую можно показать на диаграмме. Следующий фрагмент кода выберет из тестовой базы успеваемость обучающихся в 7а или 7б классах по теме 2, найдет наименьшую оценку в каждом классе, наибольшую и медианное значение. После этого найденные статистики будут отображены на диаграмме соответствующими линиями:
ggplot(data = My_table[My_table$Класс == "7а" | My_table$Класс == "7б",]) +
stat_summary(
mapping = aes(x = Класс, y = Тема2),
fun.ymin = min,
fun.ymax = max,
fun.y = median
)
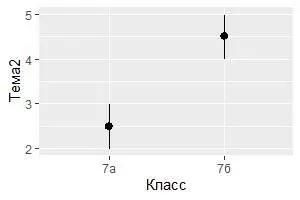
На данном этапе развития проекта, пакет ggplot2 предоставляет пользователям более 20 статистик. Каждое значение параметра stat является функцией, поэтому получить справку по ним можно обычным способом, например, введя ?stat_bin в консоли.
Упражнения
1. Что такое geom по умолчанию, связанный с stat_summary()? Как переписать код из примеров, чтобы использовать функцию начинающуюся с geom_ вместо stat_?
2. Что делает функция geom_col()? Чем она отличается от geom_bar()?
3. Большинство значений параметров geom и stat парные, и почти всегда используется вместе. Ознакомьтесь с документацией и составьте список всех пар, что у них общего?
4. Какие вспомогательные переменные вычисляет функция stat_smooth()? Какие параметры контролируют её поведение?
5. В диаграмме частот из примера установлено значение group = 1. Зачем? Другими словами, что будет нарисовано без указания этого параметра?
Есть еще одна интересная опция, связанная с гистограммами. Можно раскрасить её элементы с помощью любого цвета, указав значения параметров цвета границы (color) и заливки (fill). Обратите внимание, что произойдет, если сопоставите настройки заливки с отдельной переменной: каждый цветной прямоугольник будет представлять комбинированную информацию из двух параметров.
Регулировка положения прямоугольников задается соответствующим аргументом (position). Если его не менять, то построится столбчатая диаграмма, но можете использовать один из трех других вариантов: используемый по умолчанию (identity), развернутый по горизонтали (dodge) или с заполнением прямоугольников до равной высоты (fill). Указание position = "identity" будет размещать каждый объект ровно там, где он попадает в контекст графика. Это не очень полезно в случае детализированных прямоугольников, потому что фрагменты могут перекрываться между собой внутри одного прямоугольного столбика. Чтобы увидеть это перекрытие, можно сделать заливку полупрозрачной, придав уровню прозрачности (alpha) небольшое значение, либо использовав настройку fill = NA. Такое расположение прямоугольников полезно для 2d-примитивов, в виде точек. Указание position = "fill" работает как штабелирование, оно сделает каждый набор прямоугольников одинаковой суммарной высоты. Такой подход значительно облегчает сравнение пропорций внутри групп. И наконец position = "dodge" нарисует перекрывающиеся объекты непосредственно рядом друг с другом, что облегчает сравнение индивидуальных значений.
Заключительный тип регулировки является не очень полезным для гистограмм, но может быть очень полезен для диаграмм рассеяния. Вспомните примеры из первой главы. неужели не заметили, что график отображает только 126 точек, хотя в базе данных об автомобилях записано 234 значения. Как в известном письме на Балабановскую спичечную фабрику: «Я 11 лет считаю спички у вас в коробках – их то 59, то 60, иногда 58. Вы там сумасшедшие что ли все???». Источник обозначенной проблемы в том, что значения x и y округлены. В результате, многие точки появляясь на сетке перекрывают друг друга. Эта проблема известна как «overplotting». Такое расположение делает график трудным для понимания, когда на нём находится много данных. Распределены ли точки данных поровну на всем графике, или есть комбинация координат x и y , которая содержит 109 значений одновременно? Проблемы можно избежать, переключив регулировку положения в режим дрожания (jitter). Настройка position = "jitter" добавляет небольшое количество случайных шумов в каждую точку. Это распространяется на всю поверхность и поэтому не окажется двух точек, которые, вероятно, получат одинаковое количество случайных шумов. Добавление случайности кажется странным способом улучшения изображения, но несмотря на то, что график получится менее точным на малом масштабе, в больших масштабах график становится более иллюстративным. Поскольку это такая полезная опция, в ggplot2 внесена отдельная краткая форма записи выражения geom_point(position = "jitter"), вместо него лучше использовать geom_jitter().
Чтобы узнать больше о регулировке положения, загляните в раздел справки, посвященный каждой из перечисленных настроек.
Упражнения
1. Какие параметры функции geom_jitter() регулируют количество дрожаний?
2. Примените geom_jitter() и geom_count(), сравните полученные результаты.
3. Какая настройка положения используется в функции geom_boxplot() по умолчанию? Создайте на её основе визуализацию своего набора данных.
Заключительной частью настоящей главы рассмотрим настройку систем координат для построения графиков. Система координат, пожалуй, имеет самый сложный функционал в ggplot2. Естественно, по умолчанию используется прямоугольная декартова система координат, в которой значения x и y позволяют однозначно определить местоположение каждой точки. Но есть и другие системы координат, которые иногда полезны. Функция coord_flip() меняет местами оси x и y . Это пригодится, если хотите нарисовать горизонтальные боковые диаграммы,а также полезно для длинных графиков, которые трудно подгонять без перекрытия по оси x .
Читать дальшеИнтервал:
Закладка:









