Денис Соломатин - Основы статистической обработки педагогической информации

- Название:Основы статистической обработки педагогической информации
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:2020
- ISBN:978-5-532-04389-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Денис Соломатин - Основы статистической обработки педагогической информации краткое содержание
Основы статистической обработки педагогической информации - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
разобьет общее изображение данных известной уже нам базы на фрагментарные части, расположив их одной строкой, так как указано nrow = 1:
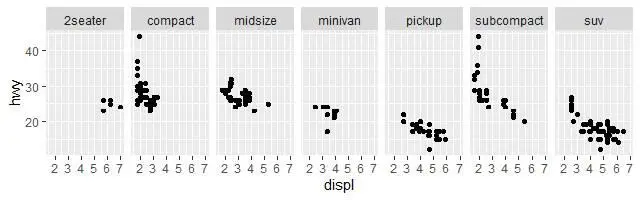
Чтобы расположить группы данных фрагментами на сетке, можно использовать комбинацию из двух переменных, добавив функцию facet_grid() к вызову графопостроителя. Первый аргумент в этом случае на этот раз будет содержать два имени переменных, разделенных знаком «~»:
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_grid(drv ~ cyl)
Если необходимо расположить группы только по одной переменной, в одну строку, либо в столбец, то достаточно поставить «.» вместо имени второй переменной. Так, например окончание +facet_grid(cyl ~ .) предпишет расположить графики вертикально, сгруппировав автомобили по числу цилиндров.
Упражнения
1. Что произойдет, если будете группировать данные по непрерывной переменной?
2. Что означают пустые ячейки на графике с facet_grid(drv~cyl)?
3. Каковы преимущества использования группирования данных частями по сравнению с цветовым выделением точек на одном графике? Каковы их недостатки? Как соблюдать баланс достоинств и недостатков этих подходов на больших объемах данных?
4. Прочитайте справку по ?facet_wrap. Что регулируется параметрами nrow, ncol? Какие ещё параметры управляют компоновкой? Почему функция facet_grid() не имеет аргументов nrow и ncol?
5. При использовании facet_grid() рекомендуется в столбцах располагать переменные с большим количеством уникальных значений. Почему?
Вернёмся к данным о результатах обучения. Во введении использовалась таблица с оценками успеваемости, которую можно воспроизвести следующей командой консоли:
My_table <���– structure(list(Класс = c("7а", "7а", "7а", "7а", "7а", "7а", "7а", "7а", "7а",
"7а", "7б", "7б", "7б", "7б", "7б", "7б", "7б", "7б", "7б", "7б", "эталон", "отстающий"),
`Фимилия Имя` = c("Иванов Иван", "Петров Петр", "Сидоров Сидор", "Егоров Егор",
"Романов Роман", "Николаев Николай", "Григорьев Григогий", "Викторов Виктор",
"Михайлов Михаил", "Тимуриев Тимур", "Ульянова Ульяна", "Ольгина Ольга",
"Людмилова Людмила", "Дарьева Дарья", "Кристинина Кристина",
"Натальина Наталья", "Глафирова Глафира", "Янина Яна", "Иринова Ирина",
"Валентинова Валентина", "Идеальный ученик", "Другая крайность"), Тема1 = c(5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 1), Тема2 = c(2, 3, 3, 2, 2, 3, 3, 2, 2, 3, 4, 5, 5, 4, 4, 4, 5, 5, 4, 5, 5, 1), Тема3 = c(1, 2, 2, 1, 1, 2, 2, 1, 2, 2, 1, 2, 2, 1, 1, 2, 2, 2, 1, 2, 5, 1), Тема4 = c(4, 5, 5, 4, 4, 4, 5, 5, 5, 4, 5, 5, 4, 4, 5, 5, 4, 4, 5, 4, 5, 1), `Тема 5` = c(1, 2, 2, 2, 1, 2, 1, 1, 2, 2, 1, 2, 2, 1, 1, 2, 2, 1, 2, 5, 5, 1), `№№` = c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22)),
row.names = c(NA, -22L), class = c("tbl_df", "tbl", "data.frame"))
Представим успеваемость графически:
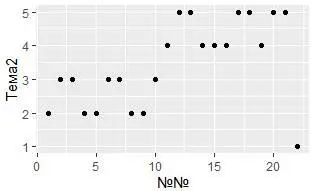
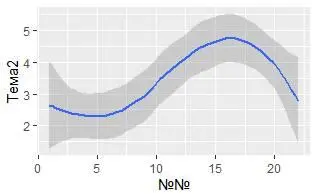
Насколько похожи эти две иллюстрации?
Оба графика содержат одну и ту же переменную x , один и тот же y , оба визуализируют одни и те же данные. Но их сюжет не идентичен. Каждая иллюстрация описается на свои визуальные образы для представления данных. В синтаксисе ggplot2 они используют разные геометрические объекты (geom). Geom – это геометрический объект, который применяет графопостроитель для представления данных. Например, линейные диаграммы используют линейные геометрические объекты, прямоугольные диаграммы используют геометрические объекты прямоугольной формы и так далее. Диаграммы рассеяния нарушают этот тренд, они используют точечное представление данных. Как видели выше, можно использовать разные геометрические объекты для визуализации одних и тех же данных. На левом графике используется точечная геометрия, а в правом – гладкая линия, усредняющая данные. Чтобы изменить геометрические примитивы на вашем чертеже, измените функцию geom_, которую добавляете к ggplot (). Например, чтобы воспроизвести вышеприведенные рисунки, выполните код:
# левый график
ggplot (data = My_table) +
geom_point (mapping = aes (x = `№№`, y = Тема2))
# правый график
ggplot (data = My_table) +
geom_smooth (mapping = aes (x = `№№`, y = Тема2))
Каждая функция geom в ggplot2 принимает аргумент mapping, однако не каждая настройка эстетики работает с любой функцией geom. Можно было бы установить форму точки, но нельзя установить форму линии. С другой стороны, можно установить параметр linetype, тогда geom_smooth() нарисует линии разного типа для каждого уникального значения переменной, которая сопоставлена с типом линии.
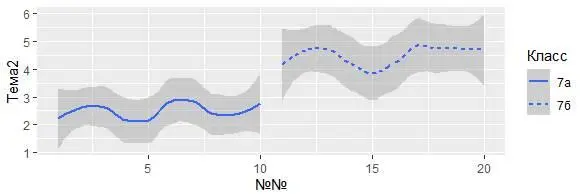
Например, функция geom_smooth() может разделить обучающихся по классам:
ggplot (data = My_table) +
geom_smooth (mapping = aes (x = `№№`, y = Тема2, linetype = Класс))
Одна линия описывает успехи в освоении Темы2 для всех одноклассников из «7а», а другая из «7б»:
Покажется немного странным, эклектикой, но можно выполнить наложение всех линий поверх необработанных данных с последующим их окрашиванием в соответствии с успеваемостью класса. Заметим, что этот график потребует два вызова geom_ для построения, но как разместить несколько геометрических объектов разного типа на одном и том же графике.
ggplot2 обеспечивает более 40 вариантов функции geom_, пакеты расширений предоставляют ещё больше возможностей. Лучший способ получить исчерпывающий обзор, используйте справку: ?geom_smooth.
Многие варианты функции geom_, такие как geom_smooth(), например, используют один геометрический объект для отображения нескольких строк данных. Для этих функций, можно выносить эстетику группы в категориальную переменную для рисования нескольких объектов в едином стиле, так как ggplot2 нарисует отдельный объект для каждого уникального объекта значение группирующей переменной. На практике ggplot2 будет автоматическая группировка данных для этих функций всякий раз, когда сопоставляется эстетика для дискретной переменной (как было в примере с linetype). Удобно использовать эту особенность, потому что в таком случае группа эстетических параметров оказывается самой по себе, она не выносится на поле легенды или в настройки каждого объекта. К слову, показ легенды можно запретить вовсе, установкой значения параметра show.legend = FALSE, как это показано в примере кода ниже:
ggplot (data = My_table) + geom_smooth (mapping = aes (x = `№№`, y = Тема2))
ggplot (data = My_table) +
geom_smooth (mapping = aes (x = `№№`, y = Тема2, group = Класс))
ggplot (data = My_table) +
geom_smooth( mapping = aes(x = `№№`, y = Тема2, color = Класс),
show.legend = FALSE)
Чтобы изобразить несколько графиков на одном чертеже, добавьте несколько вызовов функции geom к ggplot():
ggplot (data = My_table) +
geom_point (mapping = aes (x = `№№`, y = Тема2)) +
geom_smooth (mapping = aes (x = `№№`, y = Тема2))
Читать дальшеИнтервал:
Закладка:









