Джулиан Бакнелл - Фундаментальные алгоритмы и структуры данных в Delphi

- Название:Фундаментальные алгоритмы и структуры данных в Delphi
- Автор:
- Жанр:
- Издательство:ДиаСофтЮП
- Год:2003
- ISBN:ISBN 5-93772-087-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Джулиан Бакнелл - Фундаментальные алгоритмы и структуры данных в Delphi краткое содержание
Книга "Фундаментальные алгоритмы и структуры данных в Delphi" представляет собой уникальное учебное и справочное пособие по наиболее распространенным алгоритмам манипулирования данными, которые зарекомендовали себя как надежные и проверенные многими поколениями программистов. По данным журнала "Delphi Informant" за 2002 год, эта книга была признана сообществом разработчиков прикладных приложений на Delphi как «самая лучшая книга по практическому применению всех версий Delphi».
В книге подробно рассматриваются базовые понятия алгоритмов и основополагающие структуры данных, алгоритмы сортировки, поиска, хеширования, синтаксического разбора, сжатия данных, а также многие другие темы, тесно связанные с прикладным программированием. Изобилие тщательно проверенных примеров кода существенно ускоряет не только освоение фундаментальных алгоритмов, но также и способствует более квалифицированному подходу к повседневному программированию.
Несмотря на то что книга рассчитана в первую очередь на профессиональных разработчиков приложений на Delphi, она окажет несомненную пользу и начинающим программистам, демонстрируя им приемы и трюки, которые столь популярны у истинных «профи». Все коды примеров, упомянутые в книге, доступны для выгрузки на Web-сайте издательства.
Фундаментальные алгоритмы и структуры данных в Delphi - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
• Необходимо поддерживать переменную CurInx, определяющую позицию следующего символа. Ее начальным значением должен быть ноль.
• Для каждого добавляемого символа необходимо увеличивать значение CurInx и устанавливать значение CurWord [CurInx] равным символу.
• Когда требуется добавить текущее слово в список строк, необходимо снова вызвать метод SetLength, на этот раз передавая ему значение переменной CurInx. В результате длина строки будет устанавливаться равной количеству символов в строке. Затем значение CurInx необходимо переустановить равным нолю.
Применяя этот алгоритм, мы сознательно пытаемся минимизировать количество операций перераспределения памяти для CurWord (нам удалось свести это количество до двух, что можно считать почти идеальным результатом) и предотвращаем автоматическое преобразование компилятором символа в длинную строку.
------------
Как видите, код обеспечивает успешную реализацию конечного автомата. Кроме того, его очень легко расширить. Например, предположим, что должно учитываться также использование одинарных кавычек. Добиться этого достаточно просто: нужно создать новое состояние D, работающее таким же образом, как состояние В, за исключением того, что при переходе в это состояние и из него должны использоваться одинарные, а не двойные кавычки. Применительно к написанию кода это означает выполнение простого копирования и вставки с целью дублирования функций состояния В в состоянии D.
Синтаксический анализ файлов с разделяющими запятыми
Часто встречающаяся задача - необходимость выполнить синтаксический анализ файлов с запятыми-разделителями. Файл с запятыми-разделителями представляет собой текстовый файл, описывающий таблицу записей. Каждая строка в файле является отдельной записью, а сами строки делятся на поля записей, разделяемые одно от другого запятыми. (Иногда эту организацию файла называют форматом CSV (comma-separated values - значения, разделяемые запятыми).) При решении этой задачи возникает ряд затруднений (как всегда!). Поле может быть окружено кавычками (в результате значение поля может содержать запятые). Поле может отсутствовать - в этом случае две запятые означают, что поля следуют одно за другим.
Ниже приведен пример строки текста в формате CSV. Julian,Bucknall,,43,"Author, and Columnist"
Эта строка содержит пять полей. Первые два поля содержат значения [Julian] и [Bucknall], третье поле не имеет значения, значение четвертого поля - [43], а пятого - [Author, and Columnist]. (В данном случае строковые значения заключены в квадратные скобки для показа того, что двойные кавычки в исходной строке отбрасываются.)
Будем считать, что конечной целью является создание подпрограммы, которая принимает строку и список строк, разбивает строку на отдельные поля и вставляет поля в список строк. Прежде чем приступить к созданию диаграммы конечного автомата, давайте сформулируем несколько правил в отношении допустимого формата строки CSV. Во-первых, все символы являются значащими, и единственные отбрасываемые символы - запятые (естественно, после того, как они были использованы для разбиения текста CSV) и двойные кавычки, в которые заключено значение поля. Более того, двойная кавычка имеет значение открывающей двойной кавычки, если она расположена за запятой (или является первым символом строки). В частности, например, это правило означает, что если бы в приведенном примере строки между запятой и открывающей двойной кавычкой имелся один пробел, подпрограмма разбила бы строку на шесть полей, двумя последними из которых были бы ["Author] и [and Columnist"]. Более того, если бы двойная кавычка была идентифицирована в качестве открывающей двойной кавычки, то следующая двойная кавычка закрывала бы значение поля, а следующим символом должна была бы быть запятая (или конец строки). В противном случае имеет место ошибка, и строка усекается.
Теперь можно нарисовать блок-схему конечного автомата. На рис. 10.2 отражены пять состояний. Начальное состояние названо FieldStart. Если следующий символ - двойная кавычка, выполняется переход в состояние ScanQuoted, в котором выполняется отбор символов до тех пор, пока не встретится следующая двойная кавычка и не будет выполнен переход в состояние EndQuoted. Если следующий символ - запятая, можно снова выполнить переход в состояние FieldStart. Если это не так, выполняется переход в состояние ошибки, и выполнение программы прекращается. Пребывая в состоянии FieldStart, мы также можем получить запятую (поле считается пустым). Или, если мы получаем символ, который не является запятой или двойной кавычкой, осуществляется переход в состояние ScanField. В этом состоянии выполняется ввод и накопление символов до тех пор, пока не будет получена запятая.
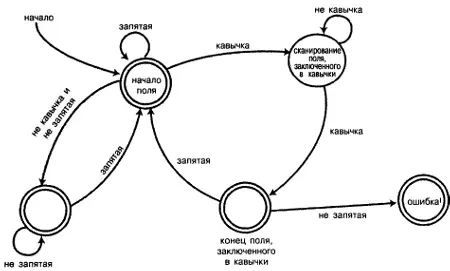
Рисунок 10.2. Конечный автомат синтаксического анализа строки в формате CSV
Как видите, в конечном автомате условия ошибки можно указывать, создавая специальное состояние. (С другой стороны, написанное можно понимать буквально. В конечном автомате, в котором не используется переход в состояние ошибки, существует только один символ, который может привести к переходу из состояния EndQuoted, - запятая, а любой другой символ приводит к "исключению".)
Преобразование блок-схемы конечного автомата в код столь же простая задача, как и в предыдущем примере. Код реализации приведен в листинге 10.2.
Листинг 10.2. Синтаксический анализ строки CSV
procedure TDExtractFields(const S : string; aList : TStrings);
type
TStates = (FieldStart, ScanField, ScanQuoted, EndQuoted, GotError);
var
State : TStates;
Inx : integer;
Ch : char;
CurField: string;
begin
{инициализация путем очистки списка строк и начало работы в состоянии FieldStart}
Assert(aList <> nil, 'TDExtractFields: list is nil');
aList.Clear;
State := FieldStart;
CurField := ''
{считывание всех символов строки}
for Inx := 1 to length(S) do
begin
{получение следующего символа}
Ch := S[Inx];
{обработать в зависимости от состояния}
case State of
FieldStart :
begin
case Ch of
'"' :
begin
State := ScanQuoted;
end;
',' :
begin
aList.Add('');
end;
else
CurField := Ch;
State := ScanField;
end;
end;
ScanField : begin
if (Ch= ',') then begin
aList.Add(CurField);
CurField := '';
State := FieldStart;
end else
CurField := CurField + Ch;
end;
ScanQuoted : begin
if (Ch= '"') then
State := EndQuoted else
CurField := CurField + Ch;
end;
EndQuoted : begin
if (Ch = ',') then begin
aList.Add(CurField);
CurField := '';
State := FieldStart;
end else
State := GotError;
end;
GotError : begin
raise EtdStateException.Create( FmtLoadStr (tdeStateBadCSV,
[UnitName, 'TDExtractFields']));
end;
end;
end;
{нахождение в состоянии ScanQuoted или GotError на момент окончания строки свидетельствует о наличии проблемы, связанной с закрывающей кавычкой}
if (State = ScanQuoted) or (State = GotError) then
raise EtdStateException.Create(FmtLoadStr (tdeStateBadCSV,
[UnitName, 'TDExtractFields']));
Читать дальшеИнтервал:
Закладка:

