Джон Форман - Много цифр. Анализ больших данных при помощи Excel

- Название:Много цифр. Анализ больших данных при помощи Excel
- Автор:
- Жанр:
- Издательство:Array Литагент «Альпина»
- Год:2016
- Город:Москва
- ISBN:978-5-9614-4076-8
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Джон Форман - Много цифр. Анализ больших данных при помощи Excel краткое содержание
Много цифр. Анализ больших данных при помощи Excel - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
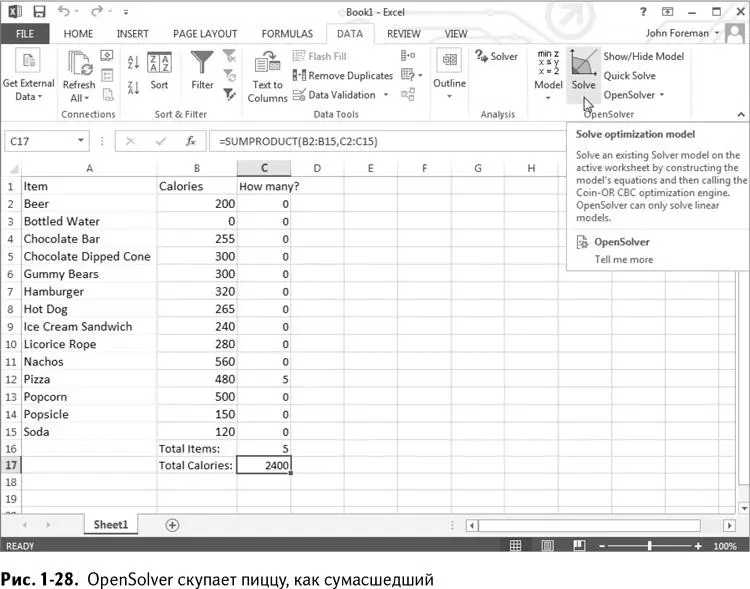
Для установки OpenSolver зайдите на http://opensolver.org и загрузите оттуда архив. Распакуйте файл в папку и в любое время, когда понадобится решить «увесистую» модель, просто внесите ее в электронную таблицу и дважды кликните на файле opensolver.xlam, после чего во вкладке «Данные» появится новый раздел OpenSolver. Теперь нажмите на кнопку «Решить». Как показано на рис. 1-28, я применил OpenSolver в Excel 2013 к модели из предыдущего раздела, и он считает, что можно купить 5 кусков пиццы.
Подытожим
Вы научились быстро ориентироваться в Excel и выбирать области поиска, эффективно использовать абсолютные ссылки, пользоваться специальной вставкой, VLOOKUP/ВПРи другими функциями поиска ячейки, сортировкой и фильтрацией данных, создавать сводные таблицы и диаграммы, работать с формулами массива и поняли, как и когда прибегать к помощи «Поиска решения».
Но вот один грустный (или смешной, в зависимости от вашего нынешнего настроения) факт. Я знал консультантов по менеджменту в крупных компаниях, которые получали немаленькую зарплату за то, что я называю «двухшаговым консалтингом»/консультационным тустепом:
1. Разговор с клиентами обо всякой чепухе (о спорте, отпуске, барбекю… конечно, я не имею в виду, что жареное мясо – полная ерунда).
2. Сведение данных в Excel.
Вы можете не знать всего о школьном футболе (я определенно не знаю), но если вы усвоите эту главу, смело отправляйте второй пункт в нокаут.
Запомните: вы читаете эту книгу не затем, чтобы стать консультантом по менеджменту. Вы здесь для того, чтобы глубоко погрузиться в науку о данных. И это погружение произойдет буквально со следующей главы, которую мы начнем с небольшого неконтролируемого машинного самообучения.
2. Кластерный анализ, часть I: использование метода k-средних для сегментирования вашей клиентской базы
Я работаю в индустрии почтового маркетинга для сайта под названием MailChimp.com. Мы помогаем клиентам делать новостную рассылку для своей рекламной аудитории. Каждый раз, когда кто-нибудь называет нашу работу «почтовым вбросом», я чувствую на сердце неприятный холод.
Почему? Да потому что адреса электронной почты – больше не черные ящики, которые вы забрасываете сообщениями, будто гранатами. Нет, в почтовом маркетинге (как и в других формах онлайн-контакта, включая твиты, посты в Facebook и кампании на Pinterest) бизнес получает сведения о том, как аудитория вступает в контакт на индивидуальном уровне , с помощью отслеживания кликов, онлайн-заказов, распространения статусов в социальных сетях и т. д. Эти данные – не просто помехи. Они характеризуют вашу аудиторию. Но для непосвященного эти операции сродни премудростям греческого языка. Или эсперанто.
Как вы собираете данные об операциях с вашими клиентами (пользователями, подписчиками и т. д.) и используете ли их данные, чтобы лучше понять свою аудиторию? Когда вы имеете дело с множеством людей, трудно изучить каждого клиента в отдельности, особенно если все они по-разному связываются с вами. Даже если бы теоретически вы могли достучаться до каждого лично, на практике это вряд ли осуществимо.
Нужно взять клиентскую базу и найти золотую середину между «бомбардировкой» наобум и персонализированным маркетингом для каждого отдельного покупателя. Один из способов достичь такого баланса – использование кластеризации для сегментирования рынка ваших клиентов, чтобы вы могли обращаться к разным сегментам вашей клиентской базы с различным целевым контентом, предложениями и т. д.
Кластерный анализ – это сбор различных объектов и разделение их на группы себе подобных. Работая с этими группами – определяя, что у их членов общего, а что отличает их друг от друга – вы можете многое узнать о беспорядочном имеющемся у вас массиве данных. Это знание поможет вам принимать оптимальные решения, причем на более детальном уровне, нежели раньше.
В этом разрезе кластеризация называется разведочной добычей данных , потому что эти техники помогают «вытянуть» информацию о связях в огромных наборах данных, которые не охватишь визуально. А обнаружение связей в социальных группах полезно в любой отрасли – для рекомендаций фильмов на основе привычек целевой аудитории, для определения криминальных центров города или обоснования финансовых вложений.
Одно из моих любимых применений кластеризации – это кластеризация изображений: сваливание в кучу файлов изображений, которые «выглядят одинаково» для компьютера. К примеру, в сервисах размещения изображений типа Flickr пользователи производят кучу контента и простая навигация становится невозможной из-за большого количества фотографий. Но, используя кластерные техники, вы можете объединять похожие изображения, позволяя пользователю ориентироваться между этими группами еще до подробной сортировки.
В разведочной добыче данных вы, по определению, не знаете раньше времени, что же за данные вы ищете. Вы – исследователь. Вы можете четко объяснить, когда двое клиентов выглядят похожими, а когда разными, но вы не знаете лучшего способа сегментировать свою клиентскую базу. Поэтому «просьба» к компьютеру сегментировать клиентскую базу за вас называется неконтролируемым машинным обучением , потому что вы ничего не контролируете – не диктуете компьютеру, как делать его работу.
В противоположность этому процессу, существует контролируемое машинное обучение , которое появляется, как правило, когда искусственный интеллект попадает на первую полосу. Если я знаю, что хочу разделить клиентов на две группы – скажем, «скорее всего купят» и «вряд ли купят» – и снабжаю компьютер историческими примерами таких покупателей, применяя все нововведения к одной из этих групп, то это контроль.
Если вместо этого я скажу: «Вот что я знаю о своих клиентах и вот как определить, разные они или одинаковые. Расскажи-ка что-нибудь интересненькое», – то это отсутствие контроля.
В данной главе рассматривается самый простой способ кластеризации под названием метод k-средних , который ведет свою историю из 50-х годов и с тех пор стал дежурным в открытии знаний из баз данных (ОЗБД) во всех отраслях и правительственных структурах.
Метод k-средних – не самый математически точный из всех методов. Он создан, в первую очередь, из соображений практичности и здравого смысла – как афроамериканская кухня. У нее нет такой шикарной родословной, как у французской, но и она зачастую угождает нашим гастрономическим капризам. Кластерный анализ с помощью k-средних, как вы вскоре убедитесь, – это отчасти математика, а отчасти – экскурс в историю (о прошлых событиях компании, если это сравнение относится к методам обучения менеджменту). Его несомненным преимуществом является интуитивная простота.
Читать дальшеИнтервал:
Закладка: