Дэвид Шпигельхалтер - Искусство статистики. Как находить ответы в данных

- Название:Искусство статистики. Как находить ответы в данных
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2021
- Город:Москва
- ISBN:9785001692508
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Дэвид Шпигельхалтер - Искусство статистики. Как находить ответы в данных краткое содержание
Эта книга предназначена как для студентов, которые хотят ознакомиться со статистикой, не углубляясь в технические детали, так и для широкого круга читателей, интересующихся статистикой, с которой они сталкиваются на работе и в повседневной жизни. Но даже опытные аналитики найдут в книге интересные примеры и новые знания для своей практики. На русском языке публикуется впервые.
Искусство статистики. Как находить ответы в данных - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Но, допустим, мы хотим сделать заявление о каких-то существующих тенденциях, скажем «количество убийств в Соединенном Королевстве растет». Например, Национальная статистическая служба Великобритании сообщила, что с апреля 2014 года по март 2015-го совершено 497 убийств и 557 в следующем таком же периоде. Конечно, число убийств возросло, но мы знаем, что оно меняется из года в год без видимых причин. Так есть ли здесь реальное изменение годового уровня убийств? Мы хотим сделать заключение об этом неизвестном количестве, поэтому нам нужна вероятностная модель для наблюдаемых величин.
К счастью, в предыдущей главе мы видели, что ежедневные количества убийств ведут себя как случайные наблюдения с распределением Пуассона – словно взятые из какой-то метафорической совокупности альтернативных возможных историй. В свою очередь, это означает, что общее число убийств за год можно рассматривать как одно наблюдение с пуассоновским распределением со средним значением m , равным (гипотетическому) «истинному» годовому уровню. Нас интересует, меняется ли это m от года к году.
Среднеквадратичное (стандартное) отклонение у распределения Пуассона – это корень из m , то есть √ m ; такова же стандартная ошибка нашей оценки. Это позволяет нам определить доверительный интервал, если мы будем знать m . Но мы его не знаем (в этом-то и суть проблемы). У нас есть период 2014–2015 годы, когда было совершено 497 убийств; это наша оценка для за этот год. С ее помощью можно найти стандартное отклонение: оно равно 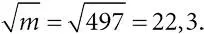 Это дает погрешность ± 1,96 × 22,3± ± 43,7. В итоге мы получаем приблизительный доверительный интервал для: 4± ± 43,7, то есть от 453,3 до 540,7. Мы можем быть уверены на%5 %, что «истинный» уровень убийств за это время находится между 453 и 541.
Это дает погрешность ± 1,96 × 22,3± ± 43,7. В итоге мы получаем приблизительный доверительный интервал для: 4± ± 43,7, то есть от 453,3 до 540,7. Мы можем быть уверены на%5 %, что «истинный» уровень убийств за это время находится между 453 и 541.
На рис. 9.4 отображено наблюдаемое число убийств в Англии и Уэльсе с 1998 по 2016 год, а также 95-процентные доверительные интервалы для «истинного» уровня. Ясно, что, несмотря на неизбежные разбросы между ежегодными числами, доверительные интервалы показывают, что нужно весьма осторожно делать заключения о временн ы х трендах. Например, 95-процентный интервал за 2015–2017 годы для числа 557 простирается от 511 до 603, то есть с существенным перекрытием с доверительным интервалом для предыдущего года.
Рис. 9.4
Число ежегодных убийств в Англии и Уэльсе между 1998 и 2016 годами, а также 95-процентные доверительные интервалы для «истинного» уровня убийств [183]
Итак, как же нам решить, произошло реальное изменение риска стать жертвой убийства или наблюдаемые изменения можно просто отнести к неизбежным случайным отклонениям? Если бы доверительные интервалы не перекрывались, то мы могли бы быть уверены, по крайней мере на 95 %, что изменение реально. Однако это довольно строгий критерий, и нам действительно следует построить 95-процентный интервал для изменения уровня убийств. Если такой интервал будет включать в себя 0, то мы не можем быть уверены в реальности изменения.
Между числом убийств за 2014–2015 и 2015–2016 годы произошло увеличение на 557–477 = 60. Оказывается, 95-процентный доверительный интервал для этого наблюдаемого изменения простирается от – 4 до +124. Это включает 0 (правда, едва-едва). Формально это означает, что мы не можем с 95-процентной уверенностью заключить, что истинный уровень изменился, но, поскольку нулевое значение находится на самом краю доверительного интервала, было бы неразумно утверждать, что изменений вовсе нет.
У доверительных интервалов вокруг числа убийств на рис. 9.4совершенно иная природа по сравнению с погрешностями, скажем, для безработицы. Последние выражают нашу эпистемическую неопределенность в отношении фактического числа безработных, в то время как интервалы вокруг числа убийств не выражают неопределенности для их фактического количества (мы полагаем, что они подсчитаны верно), а относятся к истинным рискам убийств в обществе. Эти два вида интервалов могут похоже выглядеть и даже использовать одинаковую математику, однако их интерпретации принципиально разнятся.
В этой главе содержался довольно сложный материал, что неудивительно: фактически в ней заложен весь формальный фундамент для статистических выводов, основанных на вероятностном моделировании. Но усилия того стоят, поскольку теперь мы можем использовать эту конструкцию для выхода за рамки простых описаний и оценок характеристик мира и понимания того, как статистическое моделирование может нам помочь ответить на важные вопросы о реальном мироустройстве и таким образом обеспечить прочную основу для научных открытий.
Выводы
• Теорию вероятностей можно использовать для получения распределения для выборочных статистик, из которых могут быть выведены формулы для доверительных интервалов.
• 95-процентный доверительный интервал определяется так: если мы проведем большое количество независимых экспериментов, для которых верны определенные предположения, то в 95 % этих испытаний построенный доверительный интервал будет содержать истинное значение параметра. Нельзя утверждать, что какой-то интервал с вероятностью 95 % содержит истинное значение.
• Из центральной предельной теоремы следует, что для больших выборок выборочное среднее и некоторые другие статистики имеют приблизительно нормальное распределение.
• Погрешности обычно не включают систематическую ошибку, вызванную не стохастическими причинами, – для ее оценивания нужны внешние знания и рассуждения.
• Доверительные интервалы можно вычислять, даже если мы наблюдаем все данные. Они отражают неопределенность параметров базовой метафорической совокупности.
Глава 10. Отвечаем на вопросы и заявляем об открытиях
Рождается ли мальчиков больше, чем девочек?
Врач Джон Арбетнот, ставший в 1705 году придворным лекарем королевы Анны, задался целью ответить на этот вопрос и проанализировал данные об обрядах крещения, проведенных в Лондоне за 82 года – с 1629 по 1710 год. Результаты его исследования приведены на рис. 10.1 в виде соотношения полов, то есть числа родившихся мальчиков на 100 родившихся девочек.
Рис. 10.1
Данные о соотношении полов (число мальчиков на 100 девочек) при обряде крещения в Лондоне между 1629 и 1710 годами, опубликованные Джоном Арбетнотом в 1710 году. Сплошная линия отображает равное число мальчиков и девочек; эта кривая построена по эмпирическим данным. Ежегодно мальчиков было окрещено больше, чем девочек
Арбетнот обнаружил, что ежегодно было окрещено больше мальчиков, чем девочек, причем соотношение колебалось от 101 до 116 и в целом составляло 107. Но он хотел вывести более общий закон, поэтому предположил, что если бы на самом деле никакой разницы между истинной долей мальчиков и девочек не было, то каждый год вероятность того, что мальчиков рождалось бы больше, чем девочек, а девочек рождалось бы больше, чем мальчиков, составила бы 50 на 50, то есть так же, как при подбрасывании монеты.
Читать дальшеИнтервал:
Закладка:







