Дмитрий Елисеев - Рассказы о математике с примерами на языках Python и C

- Название:Рассказы о математике с примерами на языках Python и C
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:неизвестен
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Дмитрий Елисеев - Рассказы о математике с примерами на языках Python и C краткое содержание
Книга распространяется бесплатно, скачать оригинал в PDF можно на странице
.
Рассказы о математике с примерами на языках Python и C - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Основной принцип GPU-расчетов — параллельность вычислений. Данные, хранящиеся в «глобальной памяти» (global & constant memory) устройства, обрабатываются модулями (каждый модуль называется «ядром»), каждый из которых работает параллельно с другими. Модуль имеет и свою собственную память для промежуточных данных (private memory). Так это выглядит в виде блок-схемы:
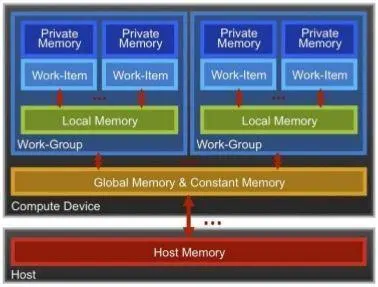
Таким образом, если задача может быть разбита на небольшие блоки, параллельно обрабатывающие небольшой фрагмент блока данных, такая задача может эффективно быть решена на GPU.
Рассмотрим пример: необходимо проверить, какие числа в массиве являются простыми. Массив может быть большим, например миллион элементов. Такая задача идеальна для распараллеливания: каждое число может быть проверено независимо от предыдущего.
Для решения такой задачи с помощью OpenCL необходимо выполнить ряд шагов.
1. Написать код микроядра (kernel):
Этот код будет запускаться непосредственно на графических процессорах видеокарты. Код пишется на языке C. В данном примере мы для упрощения храним код прямо в виде строки в программе.
const char *KernelSource = "\n" \
"__kernel void primes( \n" \
" __global unsigned int* input, \n" \
" __global unsigned int* output) \n" \
"{ \n" \
" unsigned int i = get_global_id(0); \n" \
" //printf(\"Task-%d\\n\", i); \n" \
" output[i] = 0; \n" \
" unsigned int val = input[i]; \n" \
" for(unsigned int p=2; p<=val/2; p++) { \n" \
" if (val % p == 0) \n" \
" return; \n" \
" } \n" \
" output[i] = 1; \n" \
"} \n" \
"\n";
Суть кода проста. Массив input хранит числа, которые нужно проверить, функция get_global_idвозвращает индекс задачи, которую выполняет данное ядро. Мы берем число с нужным индексом, проверяем его на простоту, и записываем 0или 1в зависимости от результата, в массив output.
2. Инициализировать подготовку вычислений:
int gpu = 1;
clGetDeviceIDs(NULL, gpu ? CL_DEVICE_TYPE_GPU : CL_DEVICE_TYPE_CPU, 1, &device_id, NULL);
cl_context context = clCreateContext(0, 1, &device_id, NULL, NULL, &err); cl_command_queue commands = clCreateCommandQueue(context, device_id, 0, &err);
На этом этапе можно выбрать где будут производиться вычисления, на основном процессоре или на GPU. Для отладки удобнее основной процессор, окончательные расчеты быстрее на GPU.
3. Подготовить данные:
#define DATA_SIZE 1024
cl_uint *data = (cl_uint*)malloc(sizeof(cl_uint) * DATA_SIZE);
cl_uint *results = (cl_uint*)malloc(sizeof(cl_uint) * DATA_SIZE);
4. Загрузить данные и программу из основной памяти в GPU:
cl_program program = clCreateProgramWithSource(context, 1, (const char **) & KernelSource, NULL, &err);
clBuildProgram(program, 0, NULL, NULL, NULL, NULL);
cl_kernel kernel = clCreateKernel(program, "primes", &err);
cl_mem output = clCreateBuffer(context, CL_MEM_WRITE_ONLY, sizeof(cl_uint) * count, NULL, NULL);
clEnqueueWriteBuffer(commands, input, CL_TRUE, 0, sizeof(cl_uint) * count, data, 0, NULL, NULL);
clSetKernelArg(kernel, 0, sizeof(cl_mem), &output);
clGetKernelWorkGroupInfo(kernel, device_id, CL_KERNEL_WORK_GROUP_SIZE, sizeof(local), &local, NULL);
5. Запустить вычисления на GPU и дождаться их завершения:
global = DATA_SIZE;
clEnqueueNDRangeKernel(commands, kernel, 1, NULL, &global, &local, 0, NULL, NULL);
clFinish(commands);
6. Загрузить результаты обратно из GPU в основную память:
clEnqueueReadBuffer( commands, output, CL_TRUE, 0, sizeof(cl_uint) * count, results, 0, NULL, NULL );
7. Освободить данные:
free(data);
free(results);
clReleaseMemObject(input);
clReleaseMemObject(output);
clReleaseProgram(program);
clReleaseKernel(kernel);
clReleaseCommandQueue(commands);
clReleaseContext(context);
Как можно видеть, процесс довольно-таки громоздкий, но оно того стоит. Для примера, проверка простоты 250000 чисел заняла на процессоре Core i5 около 6 секунд. И всего лишь 0,5 секунд заняло выполнение вышеприведенного кода на встроенной видеокарте. Для дешевого нетбука с процессором Intel Atom этот же код выполнялся 34 секунды на основном процессоре, и 6 секунд на GPU. Т. е. разница весьма прилична.
Разумеется, еще раз стоит повторить, что «игра стоит свеч» лишь в том случае, если задача хорошо распараллеливается на небольшие блоки, в таком случае выигрыш будет заметен.
Владельцы видеокарт NVIDIA (особенно игровых и достаточно мощных) могут также посмотреть в сторону библиотеки NVIDIA CUDA, расчеты с ее помощью должны быть еще быстрее.
20. Приложение 2 - Быстродействие языка Python
Язык Python очень удобен своей краткостью и лаконичностью, возможностью использования большого количества сторонних библиотек. Однако, один из его минусов, который может быть ключевым для математических расчетов — это быстродействие. Python это интерпретатор, он не создает exe-файл, что разумеется, сказывается на скорости выполнения программы.
Рассмотрим простой пример: рассчитаем сумму квадратов чисел от 1 до 1000000. Также выведем время выполнения программы.
Программа на языке Python выглядит так:
import time
start_time = time.time()
s = 0
for x in range(1,1000001):
s += x * x
print("Sum={}, T={}s".format(s, time.time() - start_time))
Результаты работы:
Sum = 333333833333500000, T = 0.47s
Учитывая, что чисел всего миллион, не так уж и быстро. Попробуем ускорить программу, для этого по возможности используем функции встроенных библиотек. Они зачастую написаны на C, и работают быстрее.
import time
start_time = time.time()
l = range(1000001)
s = sum(x * x for x in l)
print("Sum = {}, T = {}s".format(s, time.time() - start_time))
Результаты работы:
Sum = 333333833333500000, T = 0.32s
Быстрее, но лишь чуть-чуть. К тому же, данный код хранит весь массив в памяти, что неудобно.
И наконец, призываем «тяжелую артиллерию»: напишем программу на языке C. Код выглядит так:
#include
#include
int main()
{
clock_t start = clock();
unsigned long long int sum = 0, i;
for(i=1; i<1000001; i++) {
sum += i*i;
}
clock_t end = clock();
printf("Sum = %llu, T = %fs", sum, (float)(end — start)/CLOCKS_PER_SEC);
return 0;
}
Как можно видеть, он ненамного сложнее python-версии. Перед запуском программы, ее надо скомпилировать, выполнив команду C:\GCC\bin\gcc.exe "Appendix-2 - speedTest.c" -o"Appendix-2 - speedTest". Результат очевиден: T = 0,007 секунд. И еще чуть-чуть: добавляем флаг оптимизации по скорости, выполнив команду C:\GCC\bin\gcc.exe "Appendix-2 - speedTest.c" -o"Appendix-2 - speedTest" -O3. Результат: 0,0035 секунд, разница в быстродействии более 100 раз!
Увы, в более сложных задачах такого прироста реально не бывает (в последнем примере очень короткий код, который видимо полностью помещается в кеш-памяти процессора), но на некоторое улучшение быстродействия можно рассчитывать. Хотя переписывание программы — это крайний случай, сначала целесообразно поискать стандартные библиотеки, которые возможно уже решают данную задачу. К примеру, следующий код на языке Python, вычисляет сумму элементов массива за 0.1 с:
a = range(1000001)
Интервал:
Закладка:




