РАЛЬФ РАЛЬФ ВИНС - Математика управления капиталом. Методы анализа риска для трейдеров и портфельных менеджеров

- Название:Математика управления капиталом. Методы анализа риска для трейдеров и портфельных менеджеров
- Автор:
- Жанр:
- Издательство:Альпина Паблишер
- Год:2007
- ISBN:ISBN 978-5-9614-0610-8
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
РАЛЬФ РАЛЬФ ВИНС - Математика управления капиталом. Методы анализа риска для трейдеров и портфельных менеджеров краткое содержание
Математика управления капиталом. Методы анализа риска для трейдеров и портфельных менеджеров - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Затем подставляем С = 1 в уравнение (4.06):

Таким образом, в точке Х = -3 N'(X) = 0,02243444681 (отметьте, что мы рассчитываем значения в столбце N'(X) для каждого значения X).
Рассчитаем очередной столбец, текущую сумму N'(X), накапливающуюся с ростом X. Это сделать достаточно просто. Далее рассчитаем столбец N(X) для вероятности, ассоциированной с каждым значением Х при данных значениях параметров. Формула для расчета N(X) выглядит следующим образом:
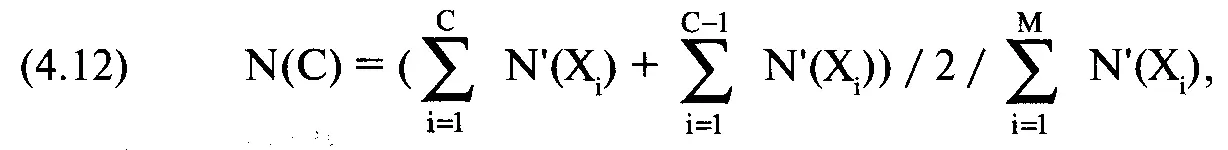
где С = текущее количество точек X;
М = общее количество точек X.
Уравнение (4.12) означает, что при каждом изменении Х необходимо добавить текущую сумму при данном значении Х к текущей сумме предыдущего значения X, затем разделить полученную сумму на 2. Далее полученный результат следует разделить на последнее значение в столбце текущей суммы N'(X) (накопленная сумма значений N'(X)). Это даст нам вероятность для значения Х при данных значениях параметров.
Таким образом, для Х = -3 текущая сумма N(X) = 0,302225586, а для предыдущего значения Х = -3,1 текущая сумма равна 0,2797911392. Сумма двух этих величин равна 0,5820167252. При делении на 2 мы получаем 0,2910083626. Разделив эту величину на последнее значение в столбце накопленной суммы N'(X), равное 11,8535923812, мы получаем 0,02455022522. Это и есть вероятность N(X) при стандартном значении Х = -3.
После того как мы вычислили накопленные вероятности для каждой сделки в фактическом распределении и вероятности для каждого приращения стандартного значения в нашем характеристическом распределении, мы можем осуществить тест К-С для значений параметров характеристического распределения, которые используются в настоящий момент. Однако сначала рассмотрим два важных момента.
В примере с таблицей накопленных вероятностей, показанной ранее для нашего регулируемого распределения, мы рассчитывали вероятности с приращением стандартных значений 0,1. Это было сделано для наглядности. На практике вы можете получить большую степень точности, используя меньший шаг приращения. Приращение 0,01 в большинстве случаев является вполне приемлемым.
Скажем несколько слов о том, как для регулируемого распределения выбрать ограничительные параметры, то есть количество сигма с каждой стороны от среднего. В нашем примере мы использовали 3 сигма, но в действительности следует использовать абсолютное значение самой отдаленной точки от среднего. Для нашего примера с 232 сделками крайнее левое (самое меньшее) стандартное значение составляет -2,96 стандартной единицы, а крайнее правое (самое большое) составляет 6,935321 стандартной единицы. Так как 6,93 больше, чем ABS(-2,96), мы должны взять 6,935321. Теперь добавим еще 2 сигма к этому значению для надежности и найдем вероятности для распределения от -8,94 до +8,94 сигма. Так как нам нужна хорошая точность, мы будем использовать приращение 0,01. Рассчитаем вероятности для стандартных значений:
| -8,94 |
| -8,93 |
| -8,92 |
| -8,91 |
| * |
| * |
| * |
| +8,94 |
Последнее, что мы должны сделать, прежде чем провести тест К-С, — это округлить фактические стандартные значения отобранных сделок с точностью 0,01 (так как мы используем 0,01 в качестве шага для теоретического распределения). Например, значение 6,935321 не будет иметь соответствующей теоретической вероятности, ассоциированной с ним, так как оно находится между значениями 6,93 и 6,94. Так как 6,94 ближе к 6,935321, мы округляем 6,935321 до 6,94. Прежде чем начать процедуру оптимизирования наших параметров регулируемого распределения путем применения теста К-С, мы должны округлить фактические отсортированные нормированные сделки в соответствии с выбранным шагом. Вместо округления стандартных значений сделок до ближайшего десятичного Х можно использовать линейную интерполяцию по таблице накопленных вероятностей, чтобы вычислить вероятности, соответствующие фактическим стандартным значениям сделок. Чтобы больше узнать о линейной интерполяции, посмотрите хорошую книгу по статистике, например «Управление деньгами на товарном рынке» Фреда Гема. Другие интересные книги указаны в списке рекомендованной литературы. До настоящего момента мы оптимизировали только параметры KURT и SCALE. Может показаться, что при нормировании данных параметр LOC должен быть приравнен к 0, а параметр SCALE — к 1. Это не совсем верно, так как реальное расположение распределения может не совпадать со средним арифметическим, а оптимальное значение ширины отличаться от единицы. Значения KURT и SCALE сильно связаны друг с другом. Таким образом, мы сначала попытаемся приблизительно определить оптимальные значения параметров KURT и SCALE. Для наших 232 сделок получаем SCALE =2,7, а KURT =1,9. Теперь попытаемся найти наиболее подходящие значения параметров. Этот процесс займет достаточно много времени, даже если у вас хороший компьютер. Мы проведем цикл, изменяя параметр LOC от 0,1 до -0,1 по -0,05, параметр SCALE от 2,6 до 2,8 по 0,05, параметр SKEW от 0,1 до -0,1 по -0,05 и параметр KURT от 1,86 до 1,92 по 0,02. Результаты этого цикла дают оптимальное (самое низкое значение статистики К-С) при LOC = О, SCALE = 2,8, SKEW =0 и KURT =1,86. Затем мы осуществим третий цикл. На этот раз будем просматривать LOC от 0,04 до -0,04 по -0,02, SCALE от 2,76 до 2,82 по 0,02, SKEW от 0,04 до -0,04 по -0,02 и KURT от 1,8 до 1,9 по 0,02. Результаты третьего цикла дают оптимальные значения LOC = 0,02, SCALE = 2,76, SKEW = 0 и KURT = 1,8. Мы нашли оптимальную окрестность, в которой параметры дают наилучшее приближение регулируемой характеристической функции к распределению реальных данных. Для последнего цикла мы будем просматривать LOC от 0 до 0,03 по 0,01, SCALE от 2,76 до 2,73 по -0,01, SKEW от 0,01 до -0,01 и KURT от 1,8 до 1,75 по -0,01. Результаты этого последнего прохода дают следующие оптимальные параметры для наших 232 сделок: LOC = 0,02, SCALE =2,76, SKEW = 0 и KURT =1,78.
Использование параметров для поиска оптимального f
Теперь, когда найдены наиболее подходящие значения параметров распределения, рассчитаем оптимальное f для этого распределения. Мы можем применить процедуру, которая была использована в предыдущей главе для поиска оптимального f при нормальном распределении. Единственное отличие состоит в том, что вероятности для каждого стандартного значения (значения X) рассчитываются с помощью уравнений (4.06) и (4.12). При нормальном распределении мы находим столбец ассоциированных вероятностей (вероятностей, соответствующих определенному стандартному значению), используя уравнение (3.21). В нашем случае, чтобы найти ассоциированные вероятности, следует выполнить процедуру, детально описанную ранее:
Читать дальшеИнтервал:
Закладка: